







注:开源力量Hadoop Development网络培训个人笔记,培训链接:http://new.osforce.cn/course/52
有了数据类型之间的对应关系,JNI就可以正确识别并转换Java类型。Java支持方法重载,仅靠函数名是无法唯一确定一个方法的。于是JNI提供了一套签名规则,用一个字符串来唯一确定一个方法,以此,JNI可识别Java的方法。其规则如下:
|
Type Signature
|
Java Type
|
|---|---|
|
Z
|
boolean
|
|
B
|
byte
|
|
C
|
char
|
|
S
|
short
|
|
I
|
int
|
|
J
|
long
|
|
F
|
float
|
|
D
|
double
|
|
L fully-qualified-class ;
|
fully-qualified-class
|
|
[ type
|
type[]
|
|
( arg-types ) ret-type
|
method type
|
For example, the Java method:
has the following type signature:
HDFS -- 数据压缩、数据完整性、数据序列化、基于文件的数据结构
在hadoop的配置文件core-site.xml可以设置是否启用本地库,默认是启用本地库。
<property>
<name>hadoop.native.lib</name>
<value>true</value>
<description>.....</description>
</property>
命令: ant compile-native
文件压缩主要有两个好处,一是减少了存储文件所占空间,另一个就是为数据传输提速。在hadoop大数据的背景下,这两点尤为重要。
Hadoop里支持很多种压缩格式:
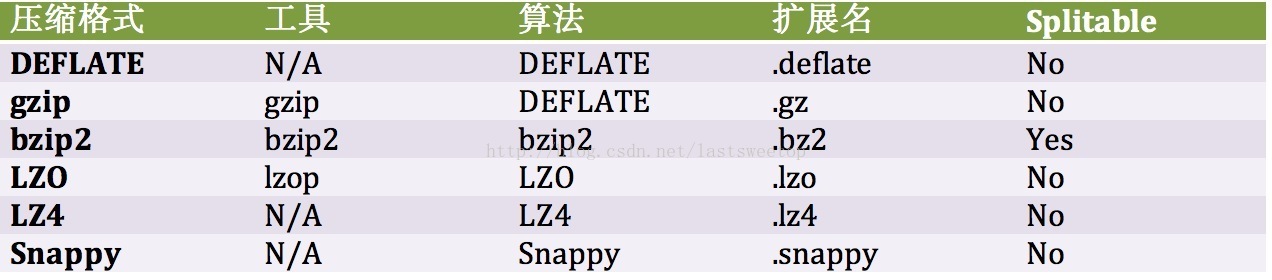
LZO and LZ4 已经不在Hadoop 1.x中了。
目录 src/core/org/apache/hadoop/io/compress
CompressionCodec有两个方法可以方便的压缩和解压。
- 压缩:通过createOutputStream(OutputStream out)方法获得CompressionOutputStream对象
- 解压:通过createInputStream(InputStream in)方法获得CompressionInputStream对象
那么如何选择压缩格式呢?这取决于文件的大小,你使用的压缩工具,下面是几条选择建议,效率由高到低排序:
- 用一些包含了压缩并且支持splittable的文件格式,比如Sequence File,RCFile或者Avro文件,这些文件格式我们之后都会讲到。如果为了快速压缩可以使用lzo,lz4或者snappy压缩格式。
- 使用提供splittable的压缩格式,比如,bzip2和索引后可以支持splittable的lzo。
- 提前把文件分成几个块,每个块单独压缩,这样就无需考虑splittable的问题了
- 不要压缩文件 以不支持splittable的压缩格式存储一个很大的数据文件是不合适的,非本地处理效率会非常之低。
参考链接:http://blog.csdn.net/lastsweetop/article/details/9162031
数据完整性常见技术
为了保证数据的完整性,一般采用数据校验技术:
- 奇偶校验技术
- MD5、SHA1等校验技术
- CRC-32循环冗余校验技术
- ECC内存纠错校验技术
1)HDFS以透明方式校验所有写入的数据,针对数据的io.bytes.per.checksum()字节创建一个单独的校验和,如果节点检测数据错误,就会报CheckSumException异常。
2)除了在读取数据时进行验证,数据节点也会在后台运行一个进程DataBlockScanner(数据块检测程序)验证存储在数据节点上的所有块。
3)一旦检测到corrupt block,在heartbeat阶段,DN会收到NN发来的Block Command,从其他数据块中拷贝一份新的replica。
LocalFileSystem
如果使用本地文件系统file:///,在写一个文件file的时候,会隐式创建一个file.crc文件,包含每个数据块的checksum
使用FileSystem.setVerifyChecksum(false)来禁用校验和验证,也可以在shell命令中使用-ignoreCrc选项
禁用校验的方法:通过RawLocalFileSystem原生支持校验和,
1)通过设置fs.file.impl的值为org.apache.hadoop.fs.RawLocalFielSystem
2)建立它的实例
序列化
1)什么是序列化:将结构化对象转换成字节流以便于进行网络传输或写入持久存储的过程。
2)什么是反序列化:将字节流转换成一些结构化对象的过程。
序列化用途:作为一种持久化格式,作为一种通信的数据格式,作为一种数据拷贝克隆机制
序列化特征(Hadoop 1.x序列化仅满足了紧凑和快速的特点):
1)紧凑:Hadoop中最稀缺的资源是带宽,所以紧凑的序列化机制可以充分地利用带宽。
2)快速:通信时大量使用序列化机制,因此,需要减少序列化和反序列化的开销
3)可扩展:随着通信协议的升级而升级
4)互操作:支持不同开发语言的通信
Hadoop的序列化不采用java的序列化,而是实现了自己的序列化机制。Hadoop通过Writable接口实现的序列化机制,不过没有提供比较功能,所以和Java中的Comparable接口合并,提供了一个接口WritableComparable。Writable接口提供了两个方法:write和readFiles。
Hadoop提供了几个重要的序列化接口:RawComparator、WritableComparator
序列化框架:Apache Avro,Facebook Thrift,Google Protocol Buffers
基于文件的数据结构,有两种文件格式:SequenceFile,MapFile
SequenceFile
- SequenceFile文件是hadoop用来存储二进制形式的key-value对而设计的一种平面文件(Flat File)
- 可以把sequencefile当作一个容器,把所有文件打包到SequenceFile类中,可以高效的对小文件进行存储和处理
- SequenceFile文件并不按照其存储的key进行排序存储,SequenceFile的内部Writer提供了append功能
- SequenceFile中的key和value可以是任意类型Writable或者是自定义Writable类型
SequenceFile的内部格式取决于是否启用压缩,如果是,要么是记录压缩,要么是块压缩。有三种类型:无压缩类型(4字节)、记录压缩(key不压缩)、块压缩(比记录压缩更紧凑,而且一般优先选择。默认1000K字节,格式为:记录数、键、值长度、值)
- MapFile是经过排序的索引的SequenceFile,可以根据key进行查找;
- MapFile的key 是WritableComparable类型的,而value是Writable类型的;
- 可以使用MapFile.fix()方法来重建索引,把SequenceFile转换成MapFile
- 它有两个静态成员变量:
static String DATA_FILE_NAME //数据文件名
static String INDEX_FILE_NAME //索引文件名
|
SequenceFile写过程:
(1)创建Configuration;(2)获取FileSystem; (3)创建文件输出路径Path; (4)调用SequenceFile.createWriter得到SequenceFile.Writer对象; (5)调用SequenceFile.Writer.append追加写入文件; (6)关闭流; | MapFile写过程: (1)创建Configuration; (2)获取FileSystem; (3)创建文件输出路径Path; (4)new一个MapFile.Writer对象; (5)调用MapFile.Writer.append追加写入文件; (6)关闭流; |
|
SequenceFile读过程:
(1)创建Configuration;(2)获取FileSystem; (3)创建文件输出路径Path; (4)new一个SequenceFileReader进行读取; (5)得到keyClass和valueClass; (6)关闭流; | MapFile读过程: (1)创建Configuration; (2)获取FileSystem; (3)创建文件输出路径Path; (4)new一个MapFile.Reader对象; (5)得到keyClass和valueClass; (6)关闭流; |















 3064
3064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









