










一、引言
四天前我发了一篇关于“从百度搜索结果抓取标题、链接、内容,并保存到xlsx文件中”的网络爬虫学习日志,算是在网络爬虫这个技术分支上走出了第一步。
我同事提出的爬虫软件需求包含了几个主要的新闻网站,只解决了爬取百度搜索的结果还不够,我还需再接再厉。这两天我将目光转向了新浪,琢磨其怎么从新浪新闻搜索中抓取搜到的结果的相关数据。新浪新闻搜索的实现技术与百度又有些不同,刚开始我还只能抓取第一页的内容,不过有了之前的知识积累,再加上不断的从网上搜索相关的资料,总算解决了问题,实现了将新浪新闻搜索到的所有新闻的标题、链接、内容、来源、时间都抓取下来的目标。经过多次测试,感觉抓取效果比之前从百度抓取要好,不光能把所有结果都抓取下来,还能通过设置参数实现对不同时间范围内的新闻进行搜索,这正是我同事需要的功能。
二、功能实现
(一)用到的库
本日志代码用到了两个库:requests、BeautifulSoup。用于发送请求获取数据和对数据进行分析,至于将抓取的结果保存到xlsx文件中,之前的日志中已经有相关的代码了,这里就不再重复了。
(二)网页数据分析
打开新浪新闻中心首页,在首页右上角的搜索框输入关键字,点搜索后跳转到了新浪网的新闻搜索页面。
刚开始使用网页浏览器的“开发者工具”对页面进行分析,比较顺利的找出了标题、链接、内容、来源、发布时间所在的节点信息。
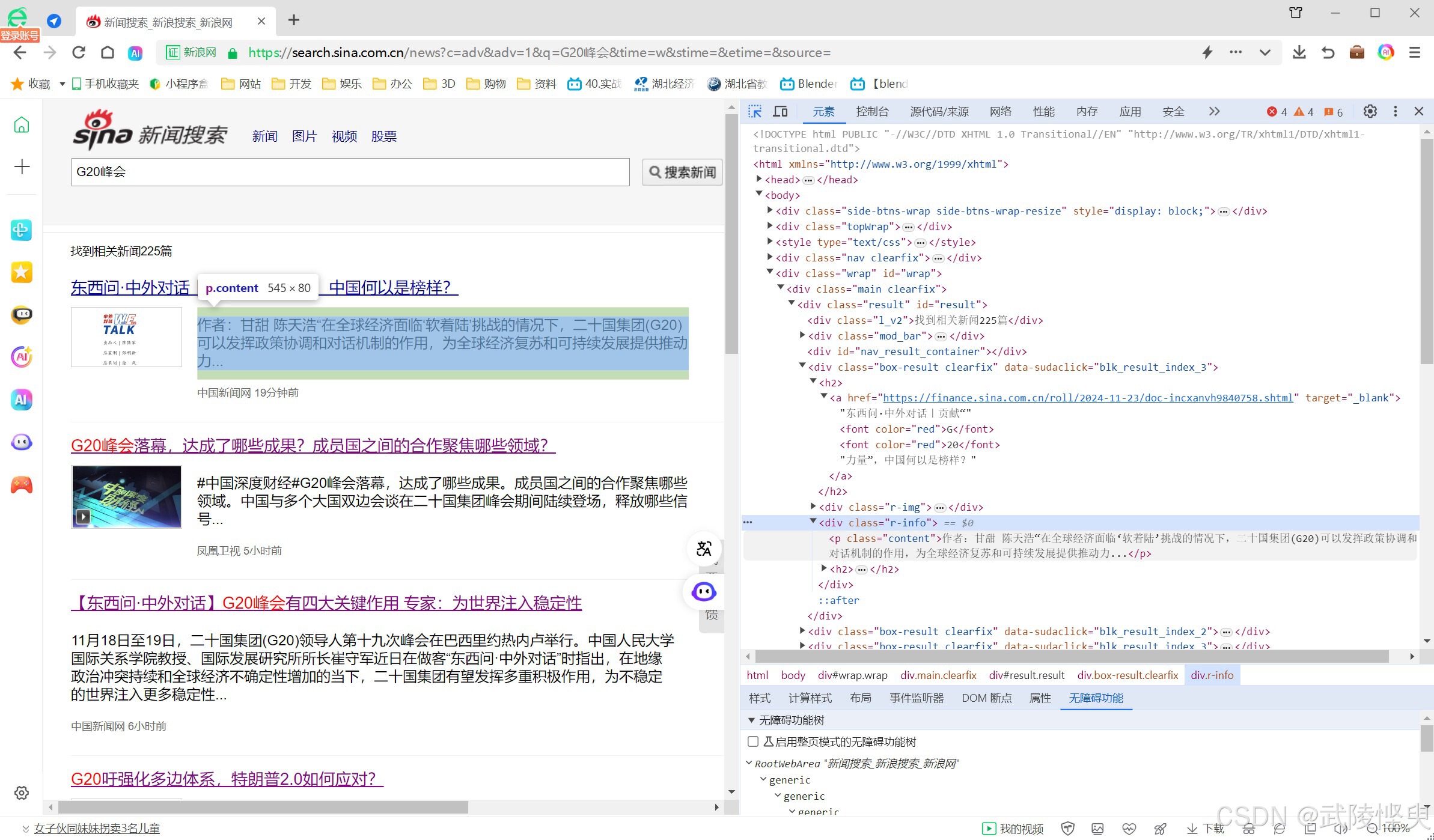
(找标题、链接、内容等信息比较容易)
但,点第2页、第3页...浏览器的网址栏显示的网址始终是“https:// search.sina.com.cn/news” ,这与百度的情况不一样(百度的网址会发生变化,可以通过观察网址发现规律)。接着我又对页面下方的其它页的跳转按钮进行了分析,一看是有规律的,但我尝试了将其中的几个参数添加到浏览器的网址栏中点更新,没有获得期待的效果。这就意味着,我没有找到网址的编写规律。
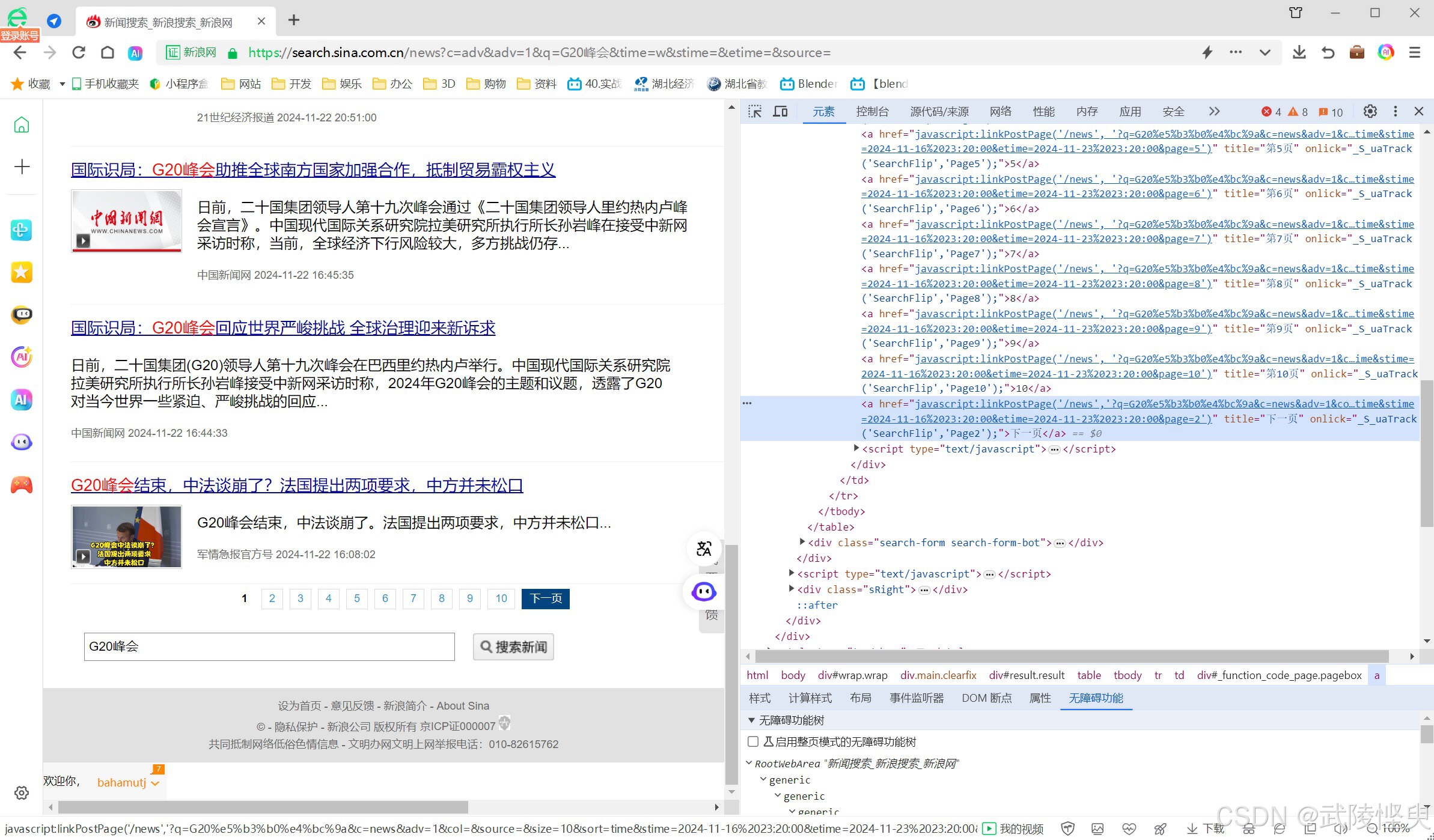
(试图从页面下方的各页跳转链接中找规律,不过水平有限,没成功)
自己研究不出来,就只能上网找了。我在网上搜索了一通,虽然找到了一些资料,但要么不能解决我遇到的问题,要么就是几年前的资料,看了一两遍,一时没看懂。这让我只能实现对第一页的内容进行抓取,与目标有很大出入。我只能暂时搁置,去研究其它网站的数据爬取。
过了一天,我又转回来研究新浪网的新闻搜索抓取。这次,我注意到了“搜索新闻”按钮右边有个“高级搜索”按钮,点击进去后发现多了时间范围和媒体两个参数。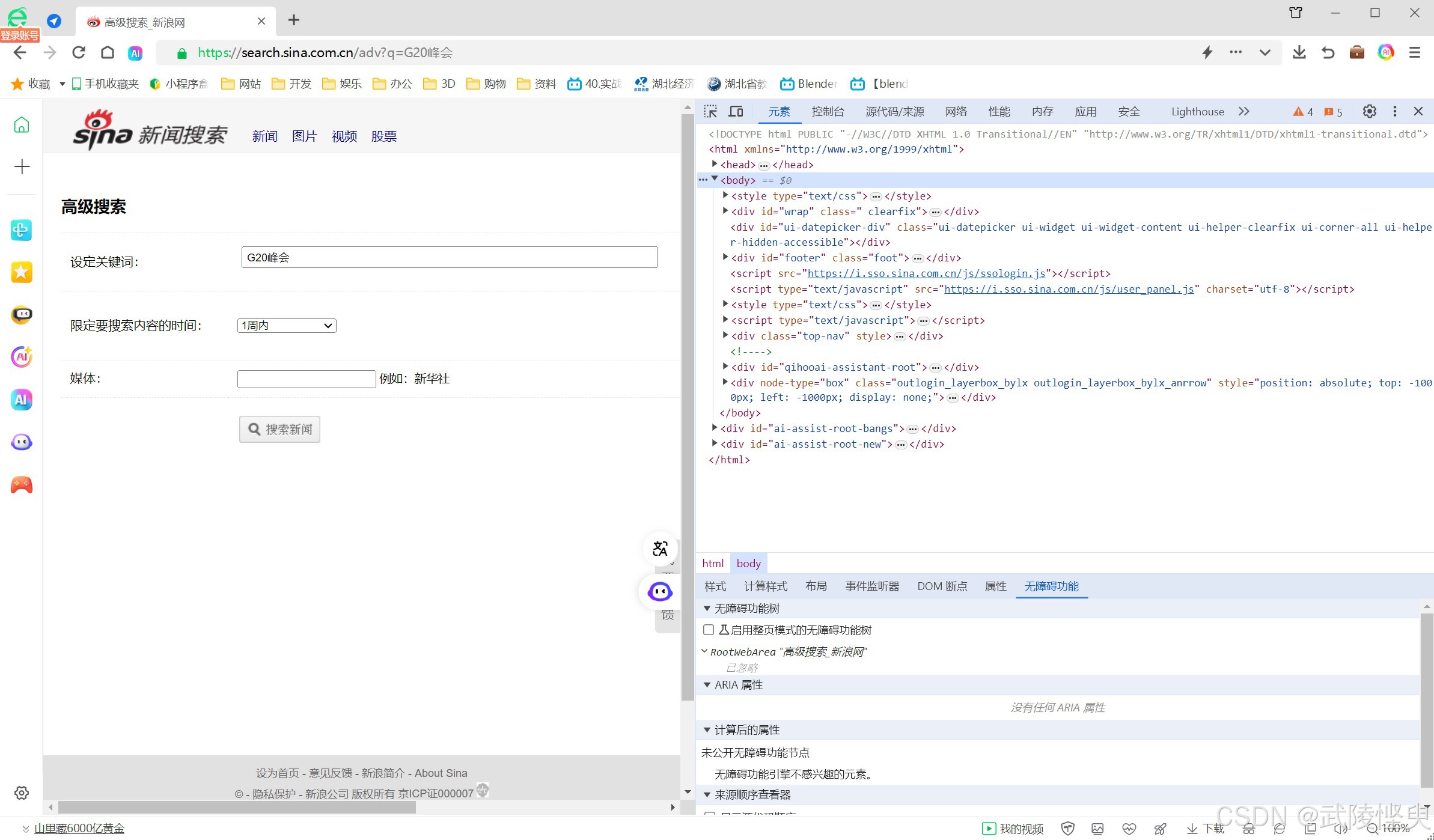
我尝试改了一下时间范围,将设置从“不限”改成了“1周内”,点“搜索新闻”按钮。这个时候结果发生了变化,同时网址栏中显示的网址也发生了变化。与之前的网址相比多了以下的内容:
“?c=adv&adv=1&q=G20峰会&time=w&stime=&etime=&source=”
看到这些字符串,我感觉有戏了。
我先是通过“高级搜索”摸索进行不同参数的设置找出了time参数和source参数的规律,之后又尝试修改上面的参数,发现adv参数就是“高级搜索”模式的开关。这个时候再回过头看页面下方的各页跳转链接,明白了stime和etime的功能,另外这个时候添加page参数,终于可以获取到其它页面的内容了。
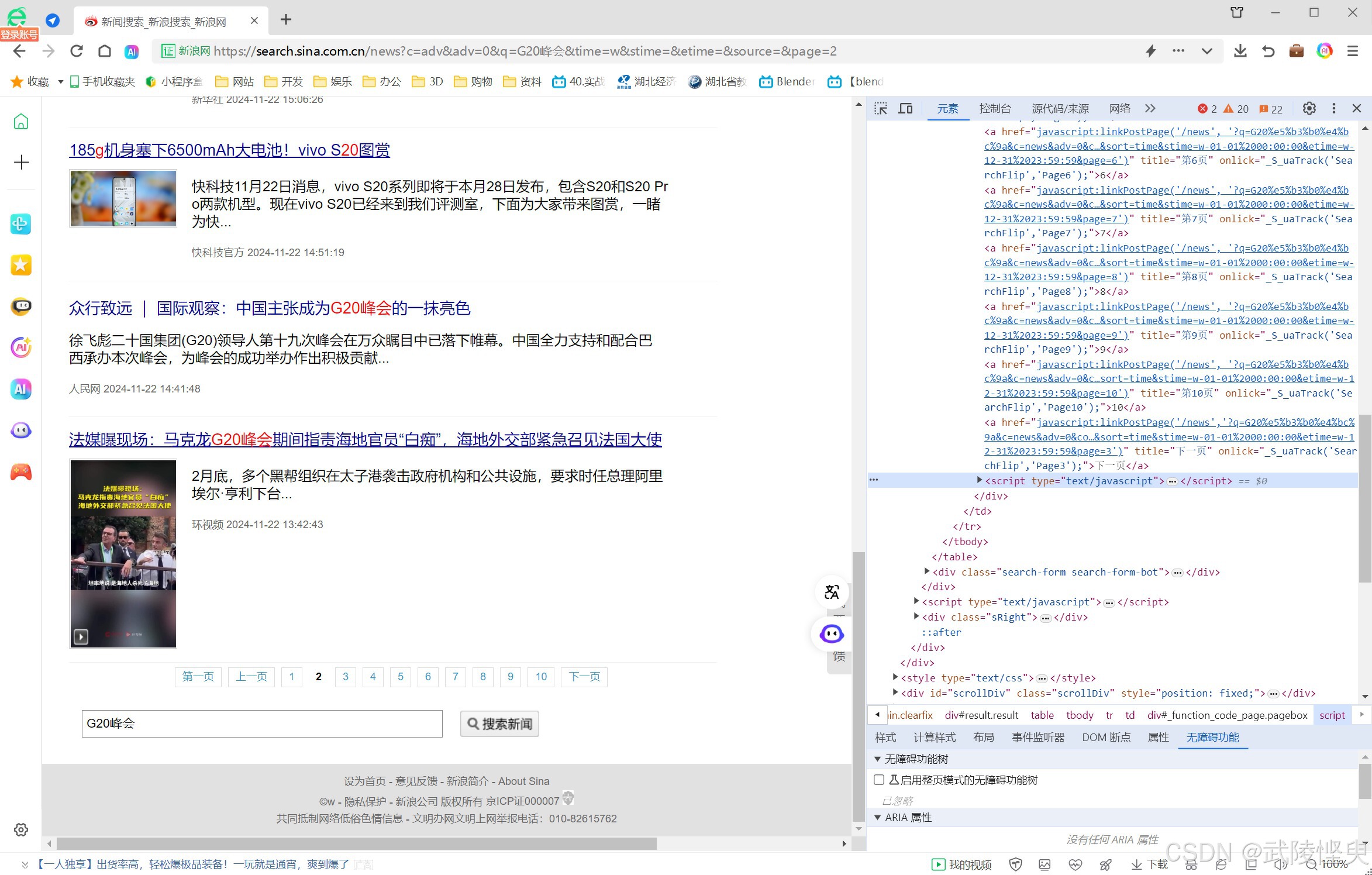
(在使用高级摸索后添加page参数可以调取其它页面的内容了)
(三)新浪新闻搜索网址中的各参数
经过多次测试,我获得的抓取搜索结果的网址格式如下:
https://search.sina.com.cn/?&c=news&adv=0&q=关键字&source=&size=20&sort=time&time=&stime=&etime=&page=1各参数的含义列明如下:
c :我的理解是类型,取值有:adv-高级搜索、news-新闻等。当此参数设为adv时,网址前缀可以设置为“https:// search.sina.com.cn/news”;当此参数改为new后,网址前缀可以设置为“https:// search.sina.com.cn/”。其它的图像、视频类型的搜索也是通过这个参数进行切换。
adv:高级搜索摸索的开关,0-关;1-开
q :关键字
source:来源,如新华社
size: 每页展示的结果数,经测试范围10-20
sort:排序方式,time-默认值,按时间排序
time:时间范围:h-1小时内,d-1天内,w-1周内,m-1月内,输入年份(如2024)-仅查该年份的数据。参数值为空表示不限
stime:开始时间,数据格式:2024-11-23%2010:23:43,一般可不设置
etime:结束时间,数据格式:2024-11-24%2010:23:43,一般可不设置
page:页号,1-第1页;2-第2页;3-第3页。。。
(四)新闻数据的抓取
本次从新浪新闻搜索的结果中,我们要抓取标题、链接、内容摘要、来源和发布时间5个数据。使用BeautifulSoup对get请求获取到的网页源代码进行分析,抓取的数据保存在results列表中,。关键代码如下:
response = requests.get(url)
response.encoding = 'utf-8'
# 检查请求是否成功
if response.status_code == 200:
# 解析响应内容
soup = BeautifulSoup(response.text, 'html.parser')
if page == 1: # 只有第一页是才抓取
try:
# 获取总的搜索结果信息
news_number = soup.find('div', 'l_v2').text
print(news_number)
except Exception as e:
print(e)
# 抓取当前页面中的搜索结果
result_blocks = soup.find_all('div', class_='box-result clearfix')
print(f'第{page}页抓取到的搜索结果数量为{len(result_blocks)}')
# 从result_blocks列表中提取有效的数据
for block in result_blocks:
order += 1 # 序号自增
title = block.find('a').text # 获取标题
link = block.find('a')['href'] # 获取链接
# 获取包含内容摘要、来源、发布时间的信息块
infos = block.find('div', class_='r-info')
# 获取内容摘要
content = infos.find('p', class_='content').text
# 获取来源和发布时间
source_time = infos.find('span').text
st_list = source_time.split() # 列表形式,元素可能是2个或3个,第一个是来源,后面的是发布时间
source = st_list[0] # 获取来源
# 获取发布时间
if len(st_list) > 2:
time = st_list[1] + ' ' + st_list[2] # 时间格式为yyyy-mm-dd hh:mm:ss
else:
time = st_list[1] # 时间格式为XX小时前
# 将本页抓取的数据添加到结果列表中
results.extend([order, title, link, content, source, time])
# 在屏幕上输出本页抓取到的信息
print(order, ". ", title)
print(link)
print(content)
print(source, ' ', time)
print(" ")(五)如何实现循环抓取
关于如何实现循环抓取,我在网上搜到了一篇相关的文章“python 爬取当下一页可点击 点开爬取”,该文章给出了解决思路和示例代码,我参照着做就实现了。
该代码执行原理是使用while循环不停的向指定的url发送get请求,从返回的源代码爬取我们需要的数据,然后从获取该页面中的下一页按钮中的超链接。如果获取到了就将page参数加1后,重新设置url;如果没有获取到下一页的超链接,说明已经到了最后一页了,退出循环。
# 初始化url中的各个参数,其中page的参数设置为1(代码略)
while url:
# 向url发生get请求(代码略)
# 从返回的源代码中爬取我们需要的数据(代码略)
# 获取下一页链接
next_page = soup.find('a', string='下一页') # 获取下一页按钮所在的节点
if next_page:
print("下一页链接:", next_page.get('href'))
page += 1
# 修改url中的page参数
url = f'https://search.sina.com.cn/news?c=news&adv=1&q={keyword}&time={time}&size=20&page={str(page)}'
else:
print("已到最后一页")
break(六)实现效果
理清了逻辑,对最初的代码进行适当的修改,就得到了这段代码。其中url里的参数“q”、“time”和“page”都设置成变量,完成后进行测试,顺利通过,效果如下。
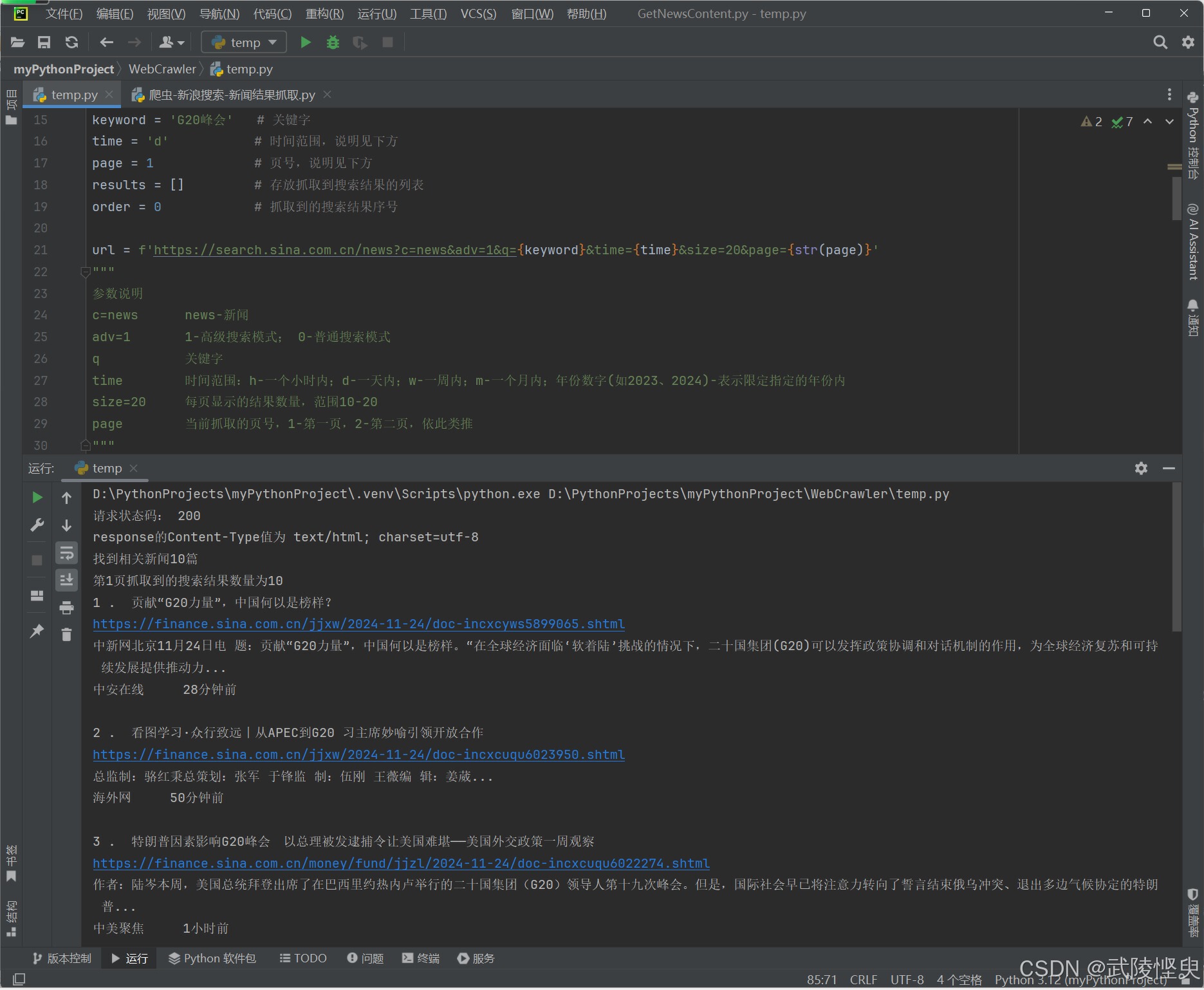
(q设置为“G20峰会”,time设置为w-1周内,page设置为1-第1页)
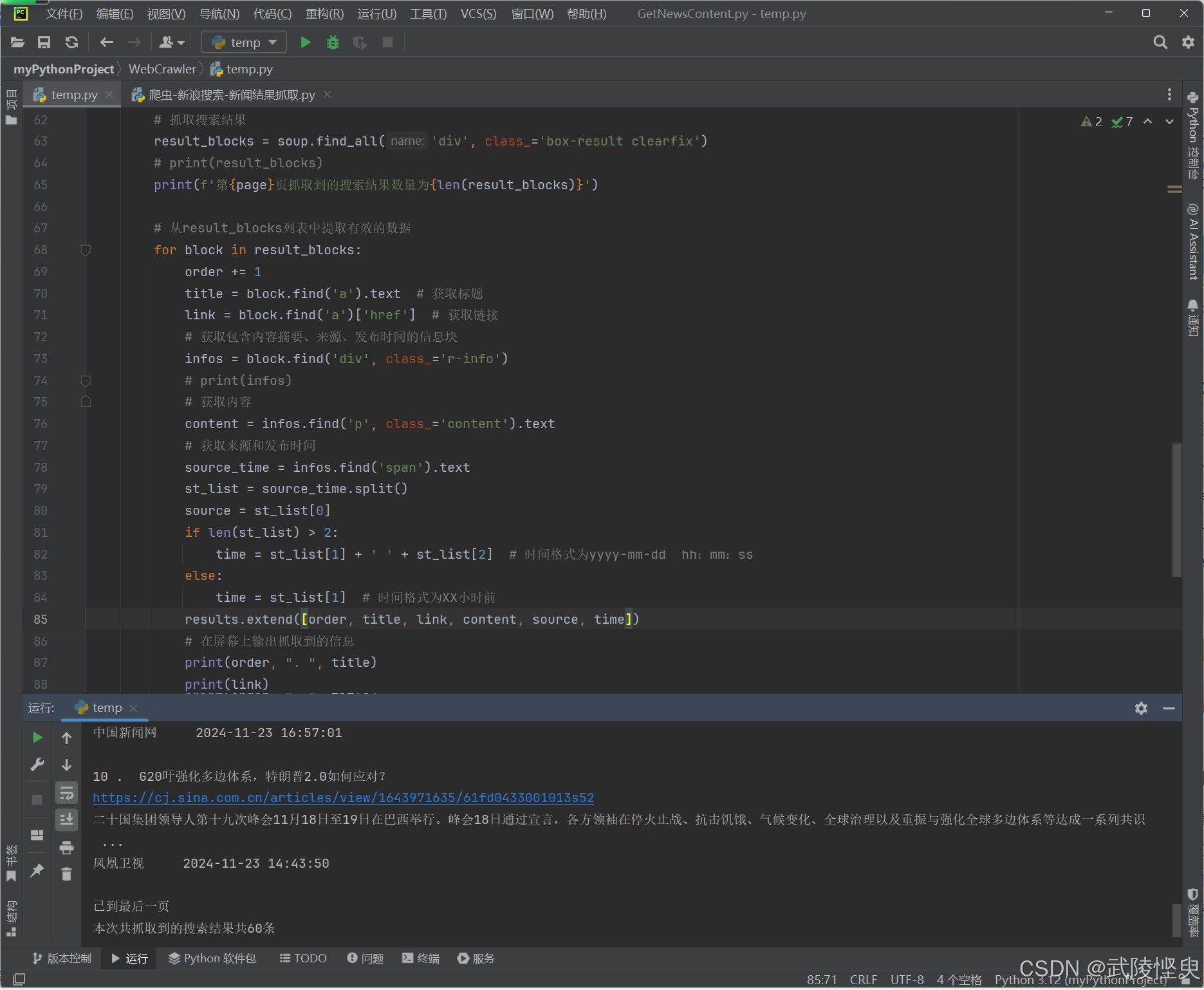
(一共抓取到了60条结果)
所有的结果都保存在results中,至于保存到xlsx文件中的方法可参考我的前一篇日志 “从百度搜索结果抓取标题、链接、内容,并保存到xlsx文件中”,这里不再赘述。
(七)拓展
新浪搜索的页面,除了能通过关键字搜新闻,还能搜图片和视频。而掌握了对新闻的搜索,再研究对图片和视频的搜索就比较容易了。这三者的区别主要是在url的参数c上。
c=news时搜新闻,c=img时搜图片,c=video时搜视频。
# 搜新闻
https://search.sina.com.cn/?&c=news&adv=0&q=关键字&source=&size=20&sort=time&time=&stime=&etime=&page=1
# 搜图片
https://search.sina.com.cn/?&c=img&adv=0&q=关键字&source=&size=20&sort=time&time=&stime=&etime=&page=1
# 搜视频
https://search.sina.com.cn/?&c=video&adv=0&q=关键字&source=&size=20&sort=time&time=&stime=&etime=&page=1不过图片和视频搜索页面的显示格式与新闻不同,进行分析提取所需数据的代码部分需要重新编写,不过有了搜新闻的经验,难度不大。这部分内容,本文也不详述,仅展示一下搜索的结果。
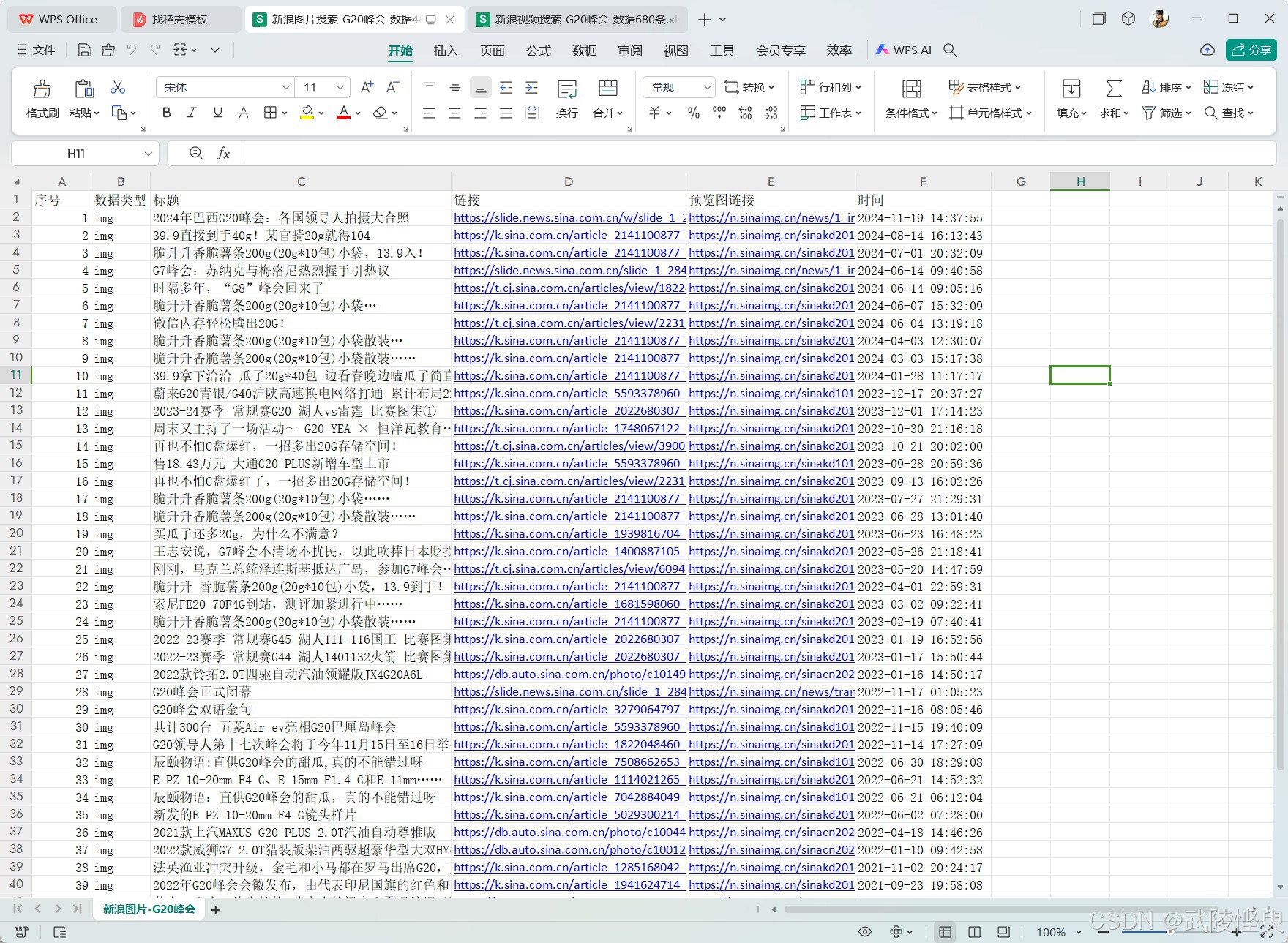
(搜索图片的结果)
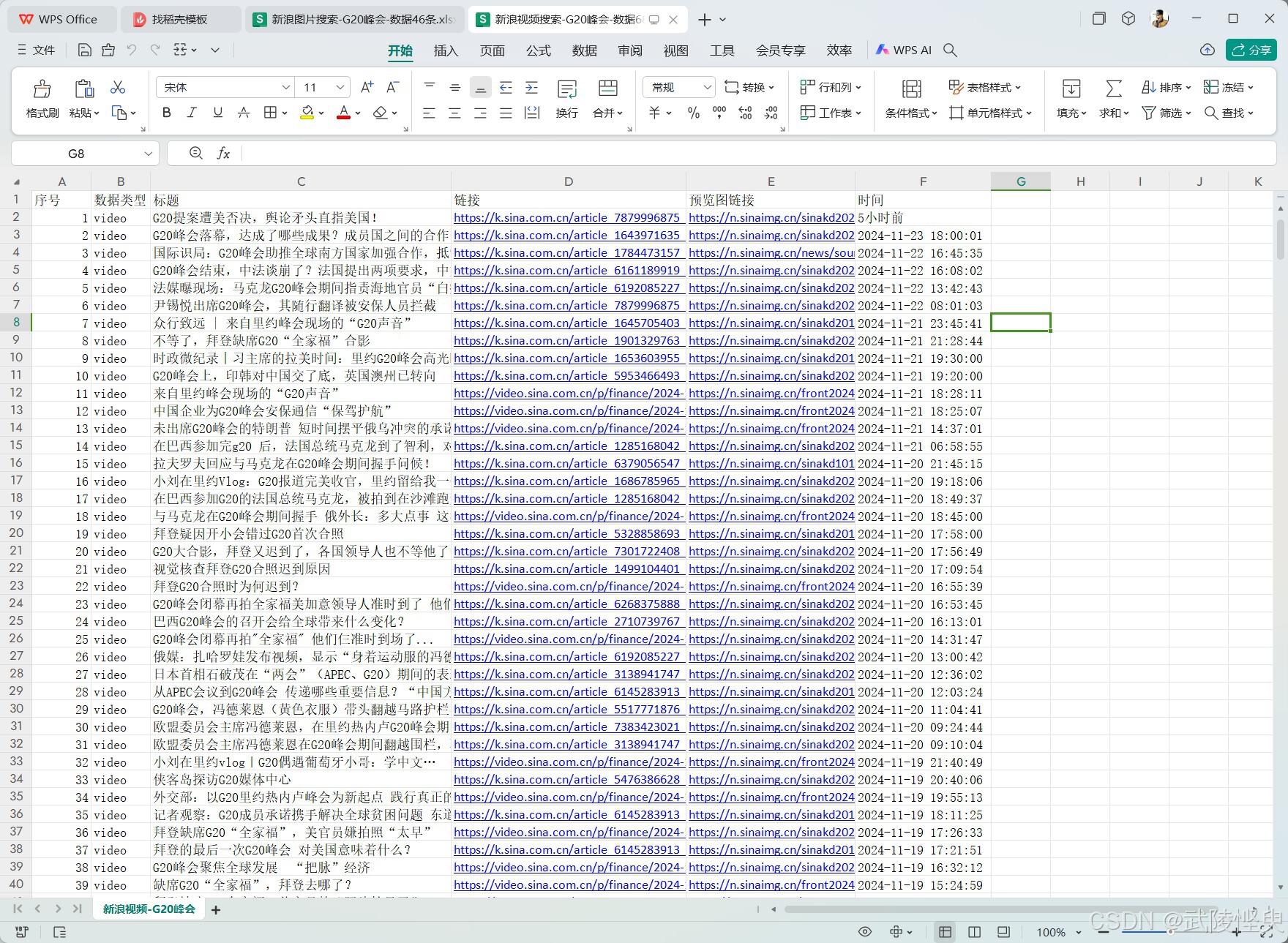
(搜索视频的结果)
三、代码展示
最后放上抓取所有新闻数据的完整代码,共参考。
import requests
from bs4 import BeautifulSoup
keyword = 'G20峰会' # 关键字
time = 'd' # 时间范围,说明见下方
page = 1 # 页号,说明见下方
results = [] # 存放抓取到搜索结果的列表
order = 0 # 抓取到的搜索结果序号
url = f'https://search.sina.com.cn/news?c=news&adv=1&q={keyword}&time={time}&size=20&page={str(page)}'
"""
参数说明
c=news news-新闻
adv=1 1-高级搜索模式; 0-普通搜索模式
q 关键字
time 时间范围:h-一个小时内;d-一天内;w-一周内;m-一个月内;年份数字(如2023、2024)-表示限定指定的年份内
size=20 每页显示的结果数量,范围10-20
page 当前抓取的页号,1-第一页,2-第二页,依此类推
"""
# 循环抓取所有页面中的数据
while url:
# 发送get请求
response = requests.get(url)
response.encoding = 'utf-8'
# 检查请求是否成功
if response.status_code == 200:
# 解析响应内容
soup = BeautifulSoup(response.text, 'html.parser')
if page == 1: # 只有第一页是才抓取
try:
# 获取总的搜索结果信息
news_number = soup.find('div', 'l_v2').text
print(news_number)
except Exception as e:
print(e)
# 抓取当前页面中的搜索结果
result_blocks = soup.find_all('div', class_='box-result clearfix')
print(f'第{page}页抓取到的搜索结果数量为{len(result_blocks)}')
# 从result_blocks列表中提取有效的数据
for block in result_blocks:
order += 1
title = block.find('a').text # 获取标题
link = block.find('a')['href'] # 获取链接
# 获取包含内容摘要、来源、发布时间的信息块
infos = block.find('div', class_='r-info')
# 获取内容
content = infos.find('p', class_='content').text
# 获取来源和发布时间
source_time = infos.find('span').text
st_list = source_time.split()
source = st_list[0]
if len(st_list) > 2:
time = st_list[1] + ' ' + st_list[2] # 时间格式为yyyy-mm-dd hh:mm:ss
else:
time = st_list[1] # 时间格式为XX小时前
results.extend([order, title, link, content, source, time])
# 在屏幕上输出抓取到的信息
print(order, ". ", title)
print(link)
print(content)
print(source, ' ', time)
print(" ")
# 获取下一页链接
next_page = soup.find('a', string='下一页') # 获取文本内容为下一页的超链接节点
if next_page:
print("下一页链接:", next_page.get('href'))
page += 1
url = f'https://search.sina.com.cn/news?c=news&adv=1&q={keyword}&time={time}&size=20&page={str(page)}'
else:
print("已到最后一页")
break
else:
print('status_code!=200, 不能解析内容')
print(f'本次共抓取到的搜索结果共{len(results)}条')

















 1343
1343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











