







一、引言
我又有三个月没有写学习记录了,原因是这段时间由于一些原因没有好好学习。不过,最近有同事希望我帮忙写一个工具软件,这让我又有了学习动力。
我的同事因工作需要,不时要从网上搜索一些信息,他一般是登录百度、腾讯、搜狐等网站,输入关键字,得到搜索结果,然后从结果中一个个点开链接,查看相关的网页中有没有自己需要的内容。同事觉得这样的手工搜索效率很低,希望我给他做个爬虫软件,提供工作效率。
我以前没有关注过网络爬虫,对这方面不太了解,因此并没有马上答应同事,而是告诉他,我对这一块还不太了解,需要先学习学习。
在花了几天进行相关知识的学习后,我有了一点点的收获。今天先整理出了从百度搜索结果中抓取标题。链接、内容,并保存到xlsx文件中的相关内容,为后续的学习做好技术储备。
二、功能实现
我个人最常用的搜索引擎就是百度了,就先从如何从百度抓取搜索结果学起。
(一)用到的库
本次学习从百度抓取搜索结果用到了四个库:requests、lxml、BeautifulSoup、xlsxwriter。其中,lxml库和BeautifulSoup库的功能相同,都是用于解析 HTML 内容的,实现数据爬取只需使用其中之一即可。这次学习把这两个库都研究了一下,分别写了两段代码,感受其不同。
(二)参考的资料
使用lxml库实现HTML 内容解析参考的资料链接:
https://blog.csdn.net/m0_74972192/article/details/140781438
使用BeautifulSoup库实现HTML 内容解析参考的资料链接:
https://blog.csdn.net/m0_74972192/article/details/140781438
上面两个参考资料都只提供了如何从百度搜索结果中爬取标题和链接的方法。而百度搜索到的结果除了标题和链接外,一般的文字网页还会提供内容摘要和来源平台名称,我希望把这两个内容页抓下来。另外一个不足就是,上面两个参考资料中的代码只能抓取一个页面的结果,而不是所有的搜索结果,而我希望一次抓取到更多的结果。
(三)场景分析
我们在百度网页输入关键字后进行搜索,会获得多个结果,百度会将搜索结果以10个为一组分成多个页面。百度返回给用户的搜索结果页面,展示的是前10个结果组成的第一页,并在页面下方提供了用于跳转到其它页面的按钮样式超链接。
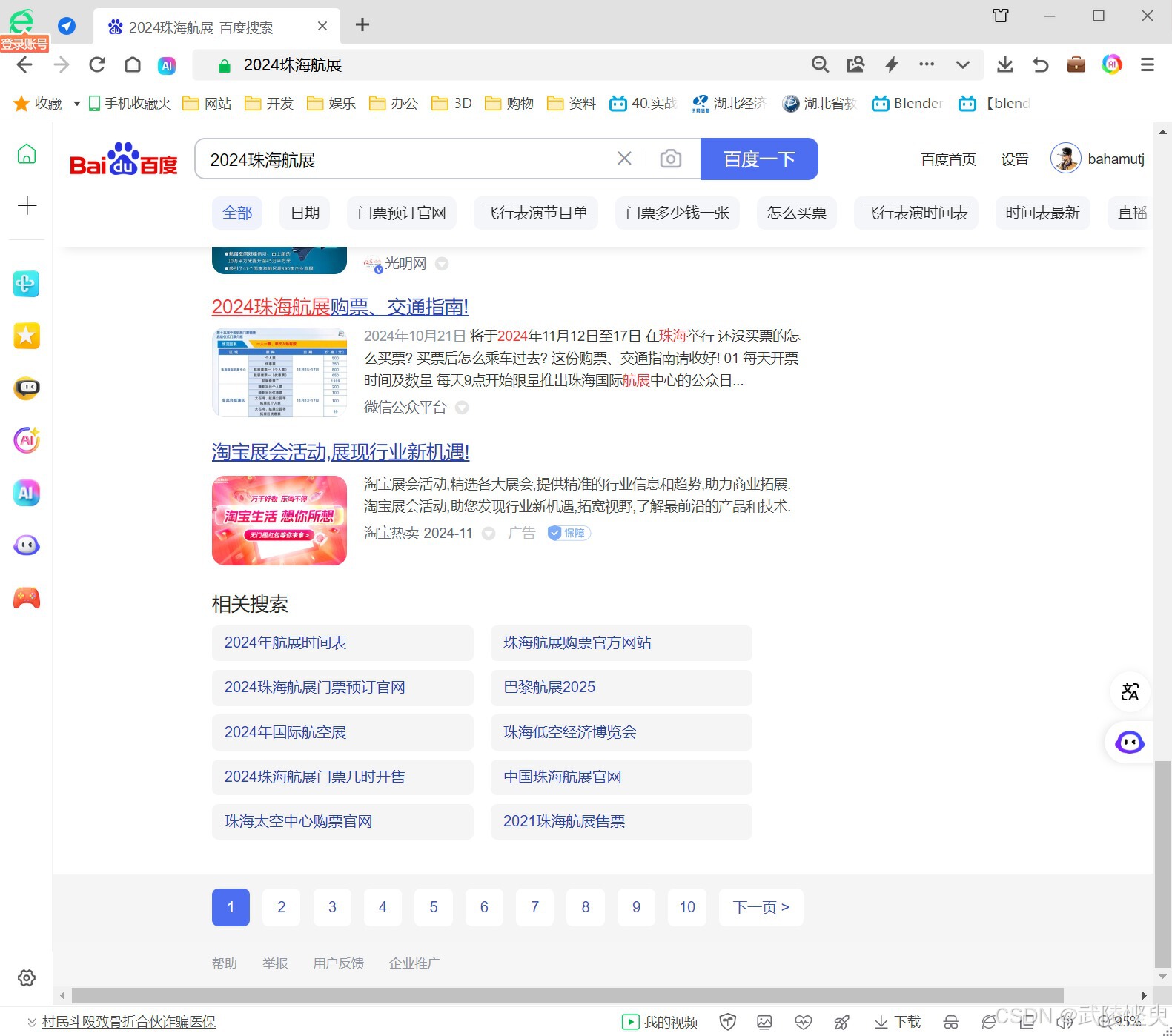
通过对网上资料的学习,我知晓了要从百度搜索页面爬取结果,需要向网站发送如下的网址格式。
f'https://www.baidu.com/s?wd={wd}&pn={pn}'其中wd是要搜索的关键字,pn则是百度网站显示的页面数,第一页pn=0,第二页pn=10,第三页pn=20,依此类推。这也就意味着每次抓取只会获得一个页面的数据,而搜索到的结果一般会超过10个,就要分多次去抓取了。这一点使用循环语句即可。
前面提到的参考资料里都只提供了如何抓取标题和链接的方法,而我希望还要抓取对应的内容摘要和来源,但一时没找到相关的资料,需要我自己去研究。好在我找到了对网页进行分析的方法,有了方法就难不倒我了。
根据所学,我通过网页浏览器的“开发人员工具”(F12),对百度网页进行了一些研究,掌握了抓取数据的一些规律。
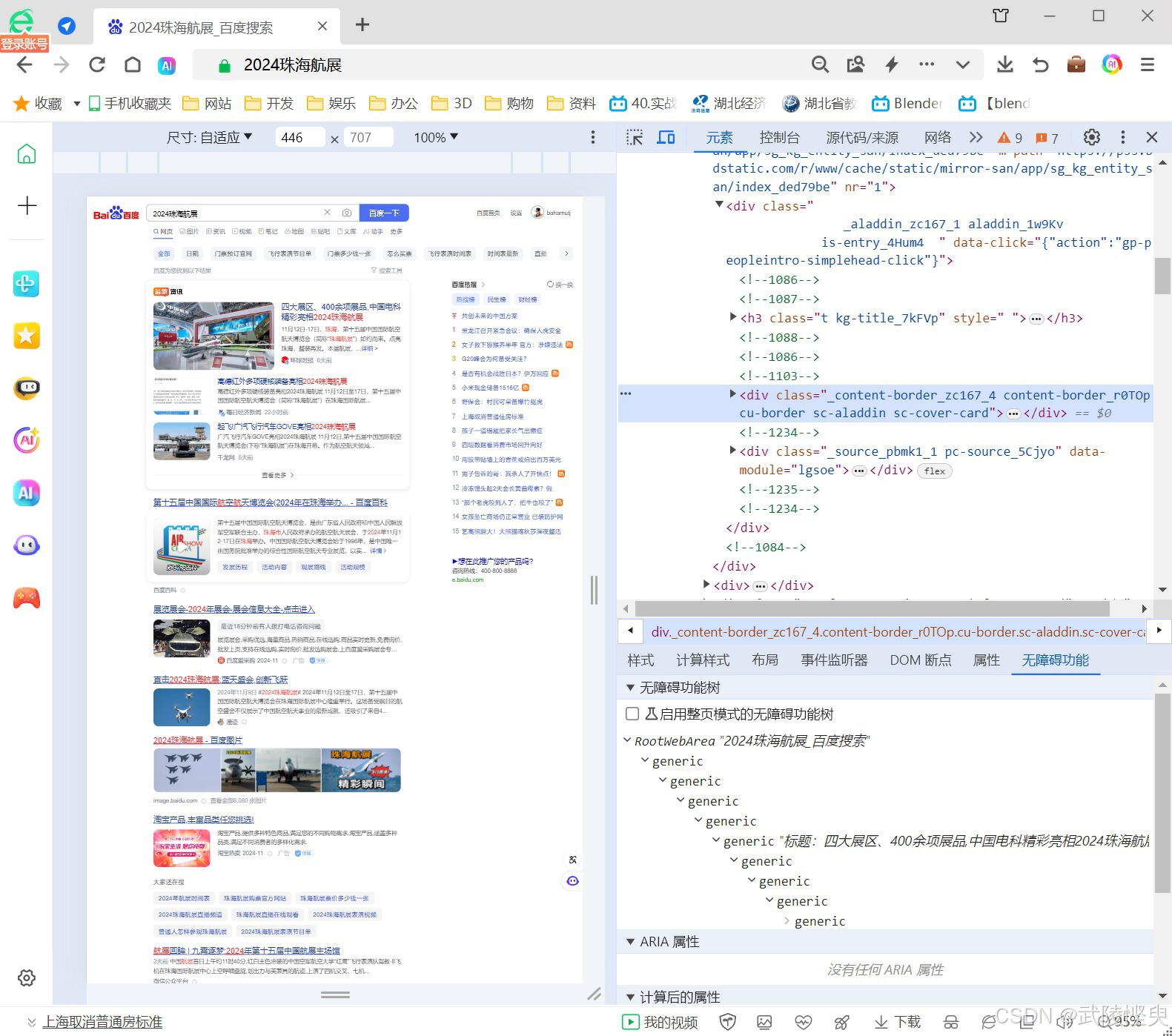
由于上述参考资料中分别有lxml库解析和BeautifulSoup库的内容,因此我就分别针对这两个资料的代码进行修改来实现我自己的目的。
1.lxml库解析
lxml库解析方面,第一个参考资料提供的代码比较完备,只需要做适当的修改,就可以达到我的目的。通过研究网页源代码,发现摘要内容都在span节点内,来源则在aria-hidden="true"的span节点下。在解析HTML内容部分,添加相关的代码即可获取到摘要和来源。
html = etree.HTML(response)
selectors = html.xpath('//div[@class="c-container"]') # 获取包含搜索结果的节点
data = []
nub = 0
for selector in selectors:
title = "".join(selector.xpath('.//h3/a//text()')) # 获取标题
title_url = selector.xpath('.//h3/a/@href')[0] # 获取链接
print(title)
print(title_url)
# 通过研究网页源代码,发现摘要内容都在span节点内
contents = selector.xpath('.//span//text()') # 获取摘要内容(列表形式)
# 将内容列表拼接成字符串
content = ''
if len(contents) > 0:
for c in contents:
content = content + c + ' '
print(content)
source = selector.xpath('.//span[@aria-hidden="true"]//text()')[0] # 获取来源
if source is None:
source = ''
print(source)
nub += 1
data.append([title, title_url, content, source])2.BeautifulSoup库解析
BeautifulSoup库方面,第二个参考资料中提供的方便只适合抓取标题和链接,不适合抓取摘要和来源。我一开始时根据第一个参考资料的内容进行的修改,使用soup.find_all方法从源代码中截图所有的class="c-container"的div节点。但在代码测试时经常会出现报错。检查错误可发现,有部分数据无法正常获取标题。通过“开发人员工具”检查源代码,会发现错误出现在如图片集合或视频集合之类的结果中或附近,虽然具体问题在哪里我一时还没有查清,但更换其它的关键字测试,也多次出现了类似的错误,且基本与图片、视频、音频等结果有关系。
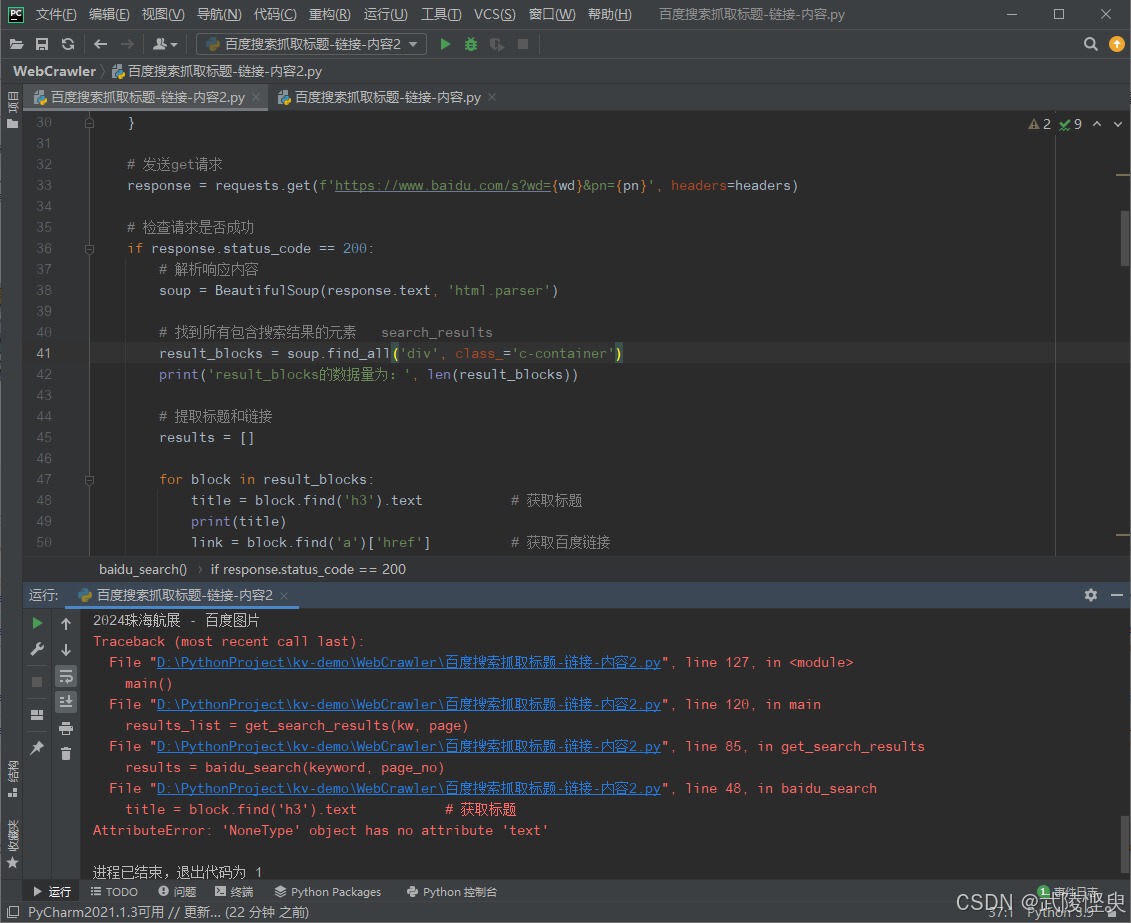
(错误的地方在获取到“2024珠海航展-百度图片”之后)
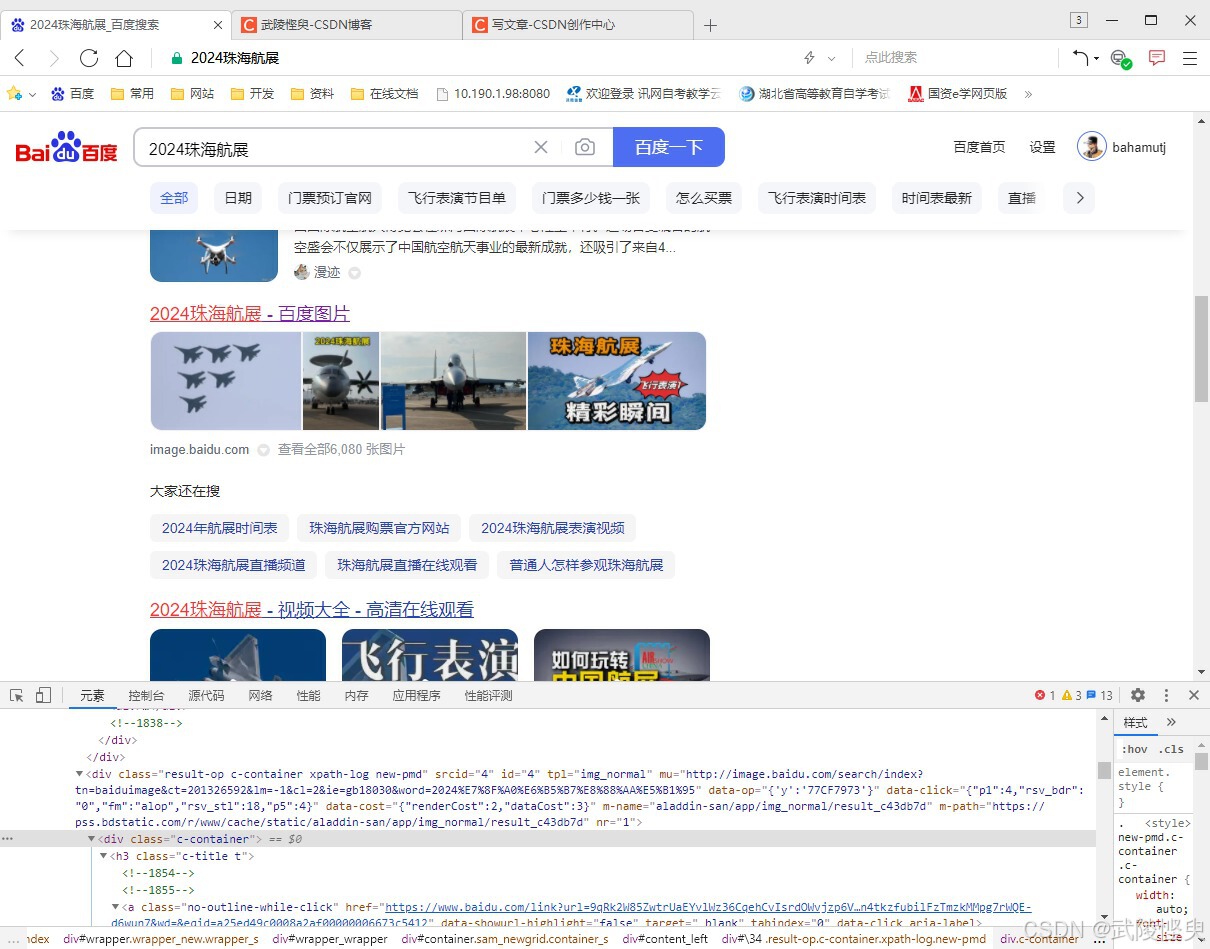
(“开发人员工具”检查错误发生出错的地方总会有图片、视频等内容)
经过研究,我发现将节点改为class属性值为"result c-container new-pmd"或者"result c-container xpath-log new-pmd"的div节点时,可以将易出错的数据过来掉(这是更上层的div节点,这两类节点下只包含了单个的文章类网页信息)。这样后续的抓取标题、链接、内容就不会出错了。当然,缺点就是会漏掉一部分搜索结果。不过漏掉的一般是图片、视频、音频之类的内容,与同事的需求冲突不大。
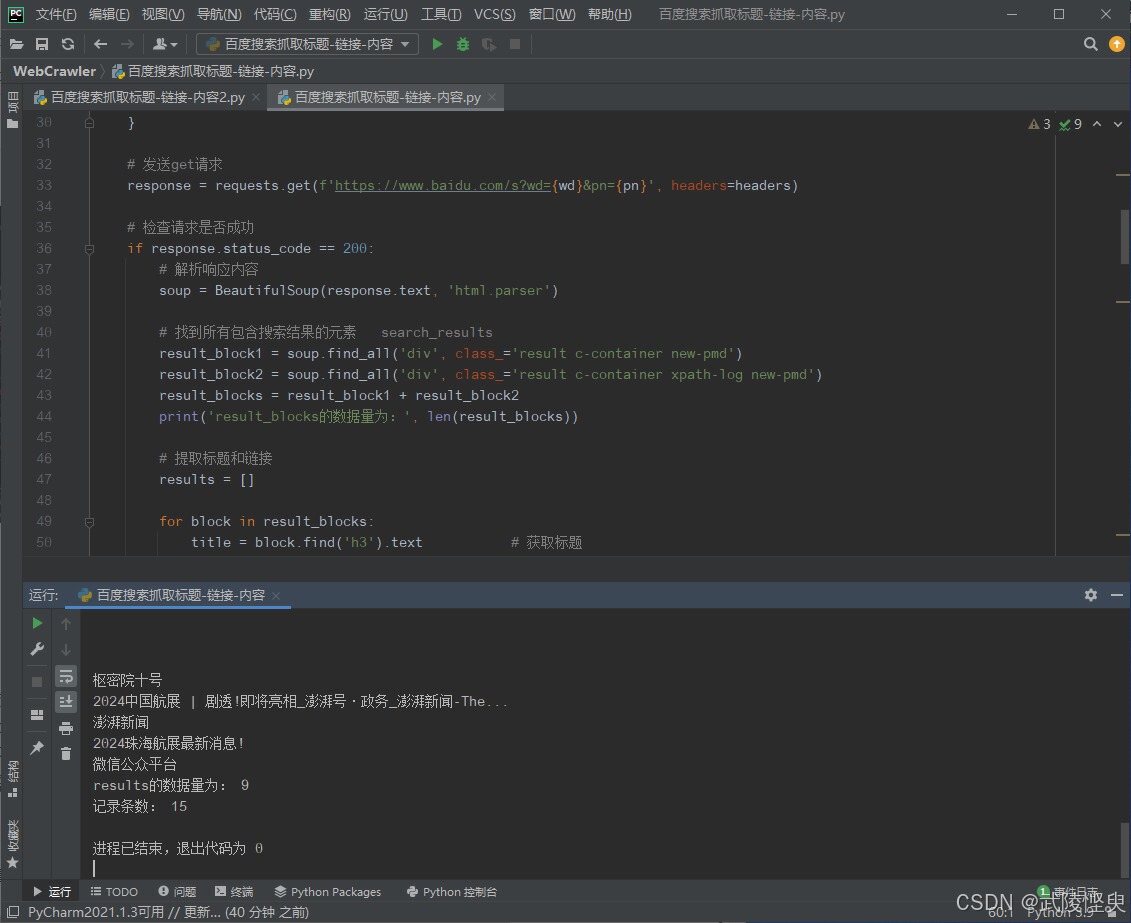
(修改了代码后,再次测试没有报错,但会漏掉一部分搜索结果)
解析部分的代码如下:
# 找到所有符合条件的节点,这里设置了两类节点,分别获取,然后合并。
result_block1 = soup.find_all('div', class_='result c-container new-pmd')
result_block2 = soup.find_all('div', class_='result c-container xpath-log new-pmd')
result_blocks = result_block1 + result_block2
print('result_blocks的数据量为:', len(result_blocks))
# 提取标题和链接
results = []
for block in result_blocks:
title = block.find('h3').text # 获取标题
print(title)
link = block.find('a')['href'] # 获取百度链接
contents = block.find_all('span') # 获取内容信息
abstract = ''
# 将获取到的内容合并成摘要信息
for content in contents:
abstract += content.text
abstract += ' '
# 获取原始链接和来源
sources = block.find('div', class_='c-gap-top-xsmall')
source = ''
if sources:
source = sources.find('a').text
print(source)
# 将本次循环抓取到的数据添加到results中
results.append([title, link, abstract, source])(三)保存数据
第一个参考资料中有现成的代码,可以将抓取到的数据保存到csv文件中,但在测试中,我发现,如果标题或摘要中有逗号,就会将字符串分割成多段,保存到多个列中,使得数据不能正常对齐(如下图)。
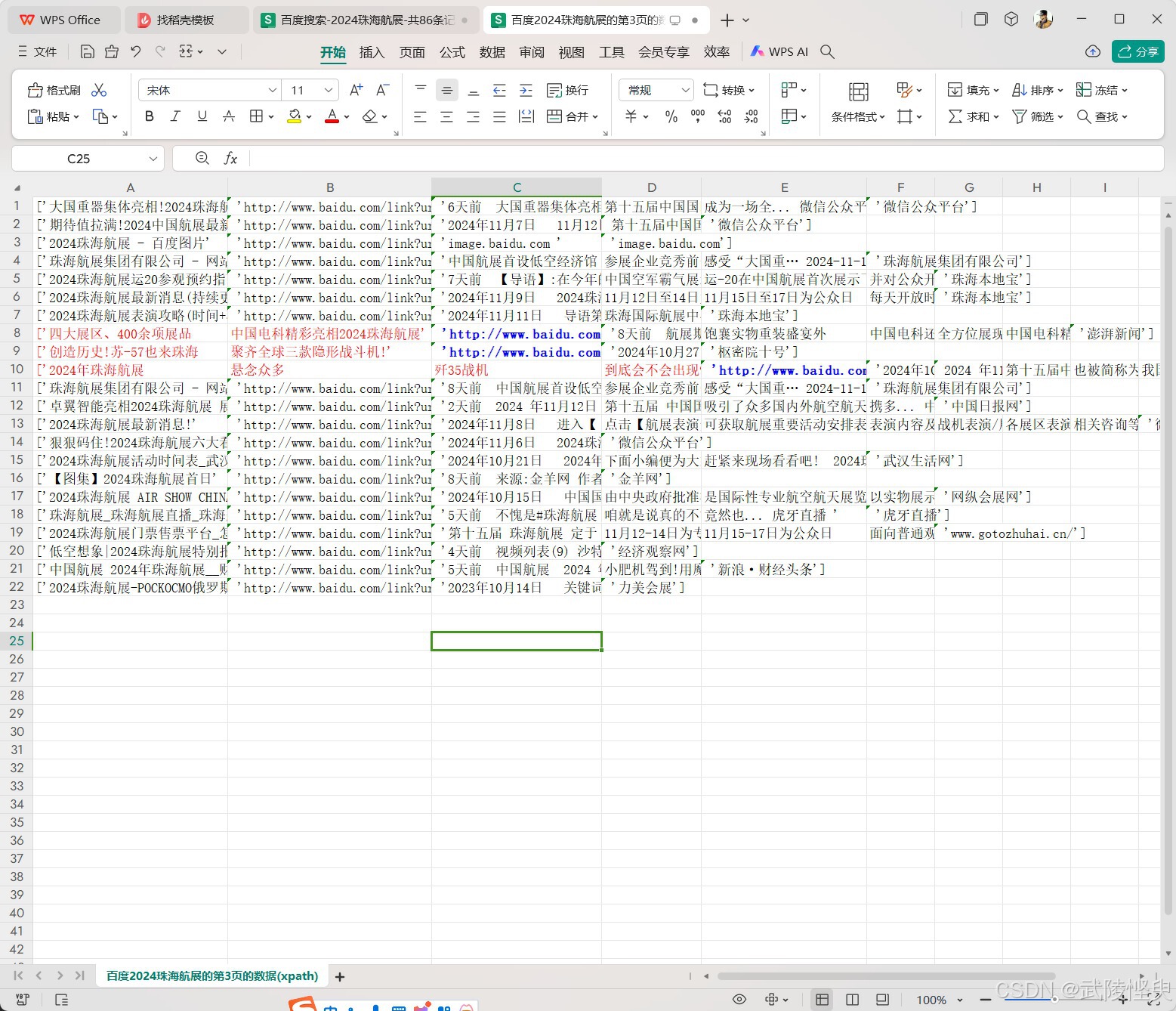
(部分标题有逗号,内容被分割成了多列,导致数据不能对齐)
使用xlsxwriter将数据写入到xlsx中可以解决这一问题。这方面的资料很多,网上找找就有了,稍微改一下就行。
def save_excel(kw, page, datas):
""" # 将数据保存到xlsx文件中 """
workbook = xlsxwriter.Workbook(f"百度-{kw}-共{page}页列表.xlsx") # 创建excel
worksheet = workbook.add_worksheet("sheet1")
worksheet.write(0, 0, "标题")
worksheet.write(0, 1, "百度链接")
worksheet.write(0, 2, "内容摘要")
worksheet.write(0, 3, "信息来源")
row = 1
for data in datas:
worksheet.write(row, 0, data[0])
worksheet.write(row, 1, data[1])
worksheet.write(row, 2, data[2])
worksheet.write(row, 3, data[3])
row += 1
workbook.close()
print('数据已保存到xlsx文件中')(四)实现步骤总结
总结前面的所学,实现抓取百度搜索结果并保存到xlsx文件的功能需要经过以下几个步骤:
1.设置需要搜索的关键字和要抓取多少个页面。在本实例中通过input方法实现。
2.直行for循环,依次获取各页的源代码并解析,抓取需要的数据,并将每次抓取的结果合并。每次抓取都向百度网站发送请求指定关键字和页号,网站返回结果后,获取其源代码,对源代码进行分析,提取自己需要的内容。这一步,我分别用两种方法进行了实现。
4.将提取出的内容保存到xlsx文件中。
(五)测试结果
完成代码设计后,运行软件输入关键字“2024珠海航展”,页数设置为10,运行程序,软件自动将结果保存到xlsx文件中,测试结果如下:
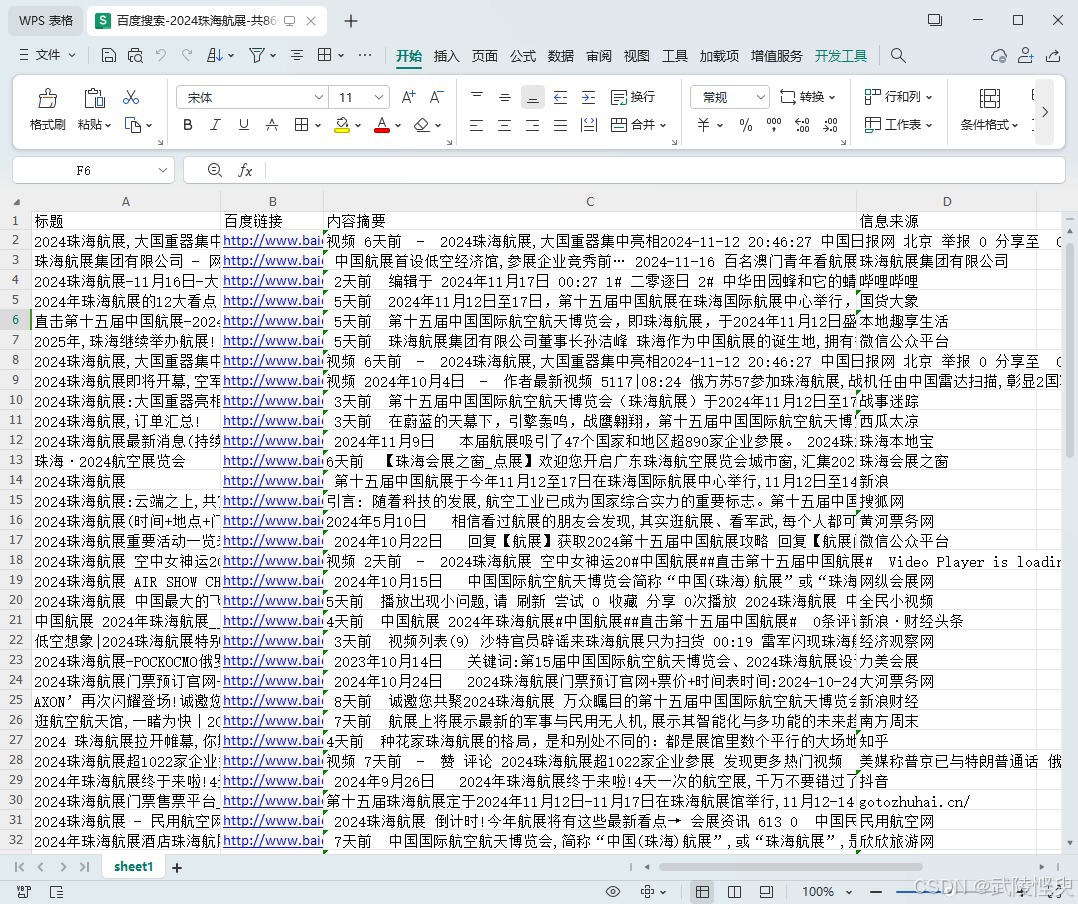
两种方法都获得了结果,但内容有些不同,且获取的结果均不足100条,说明两种方法均会漏掉一些内容。不过大部分的内容都能抓取,遗漏的不是很多,还能够接受。
三、完整代码
我分别将两个不同的库解析的代码展示出来,希望对大家有所帮助。
1.lxml库解析完整代码
import requests
from lxml import etree
import xlsxwriter
def get_web_page(wd, pn):
""" 获取百度搜索结果 """
url = 'https://www.baidu.com/s'
# 设置请求头
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,'
'application/signed-exchange;v=b3;q=0.9',
'User-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.62",
'Cookie': 'BAIDUID=C58C4A69E08EF11BEA25E73D71F452FB:FG=1; PSTM=1564970099; '
'BIDUPSID=87DDAF2BDABDA37DCF227077F0A4ADAA; '
'__yjs_duid=1_351e08bd1199f6367d690719fdd523a71622540815502; '
'MAWEBCUID=web_goISnQHdIuXmTRjWmrvZPZVKYQvVAxETmIIzcYfXMnXsObtoEz; MCITY=-%3A; BD_UPN=12314353; '
'BDUSS_BFESS=003VTlGWFZGV0NYZU1FdFBTZnFYMGtPcUs2VUtRSERVTWRNcFM5cmtHaGoyb1ZpRUFBQUFBJCQAAAAAAAAAAAEAAABCyphcYWRkZDgyMAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAGNNXmJjTV5iT; '
'BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; '
'H_PS_PSSID=34813_35915_36166_34584_36120_36195_36075_36125_36226_26350_36300_22160_36061; '
'ab_sr=1.0.1_ODllMjlmYmJlNjY5NzBjYTRkN2VlMDU3ZGI5ODJhNzA4YzllOTM3OTAwMWNmZTFlMTQ3ZmY3MmRlNDYyYWZjNTI5MzcwYmE3MDk0NGNkOGFmYThkN2FlMDdlMzA0ZjY0MmViNWIzNjc0ZjhmZWZmZGJmMTA3MGI5ZGM5MDM4NmQ3MWI0ZDUyMDljZWU4ZDExZjA1ZTg5MDYyYmNiNDc4ODFkOTQ2MmYxN2EwYTgwOTFlYTRlZjYzMmYwNzQ0ZDI3; '
'BAIDUID_BFESS=C58C4A69E08EF11BEA25E73D71F452FB:FG=1; delPer=0; BD_CK_SAM=1; PSINO=1; '
'H_PS_645EC=c87aPHArHVd30qt4cjwBEzjR%2BwqcUnQjjApbQetZm98YZVXUtN%2FOXOxNv3A; '
'BA_HECTOR=25a0850k0l8h002kio1h5v7ud0q; baikeVisitId=61a414fd-dde7-41c2-9aa5-aa8044420d33',
'Host': 'www.baidu.com'
}
# 关键字和页号参数
params = {
'wd': wd,
'pn': pn
}
# 发送get请求
response = requests.get(url, headers=headers, params=params)
response.encoding = 'utf-8'
# 获取源代码中的文本
response = response.text
return response
def parse_page(response):
""" 网页文本分析 """
html = etree.HTML(response)
selectors = html.xpath('//div[@class="c-container"]') # 获取包含搜索结果的节点
data = []
nub = 0
for selector in selectors:
title = "".join(selector.xpath('.//h3/a//text()')) # 获取标题
title_url = selector.xpath('.//h3/a/@href')[0] # 获取链接
print(title)
print(title_url)
contents = selector.xpath('.//span//text()') # 获取摘要内容(列表形式)
# 将内容列表拼接成字符串
content = ''
if len(contents) > 0:
for c in contents:
content = content + c + ' '
print(content)
source = selector.xpath('.//span[@aria-hidden="true"]//text()')[0] # 获取来源
if source is None:
source = ''
print(source)
nub += 1
data.append([title, title_url, content, source])
print(f"当前页一共有{nub}条标题和网址的信息!")
return data
def save_data(datas, kw, page):
""" # 数据写入文件后,如果标题中有逗号,会将标题分段,已弃用 """
for data in datas:
with open(f'./百度{kw}的第{page}页的数据(xpath).csv', 'a', encoding='utf-8') as fp:
fp.write(str(data) + '\n')
print(f"百度{kw}的第{page}页的数据已经成功保存!")
def save_excel(kw, page, datas):
""" # 将数据保存到xlsx文件中 """
workbook = xlsxwriter.Workbook(f"百度-{kw}-共{page}页列表.xlsx") # 创建excel
worksheet = workbook.add_worksheet("sheet1")
worksheet.write(0, 0, "标题")
worksheet.write(0, 1, "百度链接")
worksheet.write(0, 2, "内容摘要")
worksheet.write(0, 3, "信息来源")
row = 1
for data in datas:
worksheet.write(row, 0, data[0])
worksheet.write(row, 1, data[1])
worksheet.write(row, 2, data[2])
worksheet.write(row, 3, data[3])
row += 1
workbook.close()
print('数据已保存到xlsx文件中')
def main():
kw = input("请输入要查询的关键词:").strip()
page = input("请输入要查询的页数:").strip()
page_pn = int(page)
pages = int(page)
results = []
for page in range(1, pages+1):
page_pn = str(page * 10 - 10)
resp = get_web_page(kw, page_pn)
datas = parse_page(resp)
# print(datas)
results.extend(datas)
print('results的数据量为:', len(results))
save_excel(kw, page, results)
# save_data(results, kw, page) # 有bug
if __name__ == '__main__':
main()2.BeautifulSoup库解析完整代码
import requests
from bs4 import BeautifulSoup
import xlsxwriter
def baidu_search(wd, pn):
""" 通过百度进行搜索,并返回结果 """
# 设置请求头部信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/94.0.4606.71 Safari/537.36'
}
# 发送get请求
response = requests.get(f'https://www.baidu.com/s?wd={wd}&pn={pn}', headers=headers)
# 检查请求是否成功
if response.status_code == 200:
# 解析响应内容
soup = BeautifulSoup(response.text, 'html.parser')
# 找到所有符合条件的节点,这里设置了两类节点,分别获取,然后合并。
result_block1 = soup.find_all('div', class_='result c-container new-pmd')
result_block2 = soup.find_all('div', class_='result c-container xpath-log new-pmd')
result_blocks = result_block1 + result_block2
print('result_blocks的数据量为:', len(result_blocks))
# 提取标题和链接
results = []
for block in result_blocks:
title = block.find('h3').text # 获取标题
print(title)
link = block.find('a')['href'] # 获取百度链接
contents = block.find_all('span') # 获取内容信息
abstract = ''
# 将获取到的内容合并成摘要信息
for content in contents:
abstract += content.text
abstract += ' '
# 获取来源
sources = block.find('div', class_='c-gap-top-xsmall')
source = ''
if sources:
source = sources.find('a').text
print(source)
# 将本次循环抓取到的数据添加到results中
results.append([title, link, abstract, source])
print('results的数据量为:', len(results))
return results
else:
print("请求失败!")
return None
def get_search_results(keyword, pages):
""" 循环获取多个页面的数据 """
search_results = []
# 获取搜索结果
for x in range(1, pages + 1):
page_no = str(10 * (x - 1)) # 转换出参数pn的值
results = baidu_search(keyword, page_no)
search_results.extend(results)
if search_results:
print('记录条数:', len(search_results))
else:
print("未能获取搜索结果。")
return search_results
def save_excel(kw, row, datas):
""" # 将数据保存到xlsx文件中 """
workbook = xlsxwriter.Workbook(f"百度搜索-{kw}-共{row}条记录.xlsx") # 创建excel
worksheet = workbook.add_worksheet("sheet1")
worksheet.write(0, 0, "标题")
worksheet.write(0, 1, "百度链接")
worksheet.write(0, 2, "内容摘要")
worksheet.write(0, 3, "信息来源")
row = 1
for data in datas:
worksheet.write(row, 0, data[0])
worksheet.write(row, 1, data[1])
worksheet.write(row, 2, data[2])
worksheet.write(row, 3, data[3])
row += 1
workbook.close()
def main():
""" 主程序 """
kw = input("请输入要查询的关键词:").strip()
page = input("请输入要查询的页数:").strip()
page = int(page)
results_list = get_search_results(kw, page)
rows = len(results_list)
save_excel(kw, rows, results_list)
if __name__ == "__main__":
main()

















 1679
1679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











