







文章代码来源:《deep learning on keras》,非常好的一本书,大家如果英语好,推荐直接阅读该书,如果时间不够,可以看看此系列文章
还记得第一次跑出自己的神经网络的那种欣喜感,仿佛是看着自己的第一个孩子出生了一样。为了让更多人尽快也体验的这种欣喜感,特此总结此系列教程,代码来自书<deep learning on keras>.
简要介绍一下我们需要的:
- 安装annaconda,它自带的很多科学计算包能够省掉很多我们自己安装的麻烦
- 打开cmd,输入pip install tensorflow,默认安装的是cpu版tensorflow,对于我们这新手级别的,已经够用了,要装gpu版比较麻烦
- 在装好tensorflow以后再pip install keras,这个keras是基于tensorflow或者caffe的,我习惯使用tensorflow,keras是在tensorflow上的进一步封装,使用起来非常简单,我们只需要把精力放在网络结构的搭建上就够了。
引入库和数据集
此处我们引入MNIST数据集,这是一个手写数字数据集,由60000个训练集和10000个测试集构成。
import keras
from keras.datasets import mnist
(trainimages, trainlabels), (testimages, testlabels) = mnist.loaddata()
这句代码表示调用数据集mnist,把训练图片和标签分别存到trainimages和trainlabels里面,测试图片和标签分别存在testimages和testlabels里面。
接下来我们看一看具体是如何储存这些数据的:
>>> train_images.shape
(60000, 28, 28)
>>> len(train_labels)
60000
>>> train_labels
array([5, 0, 4, ..., 5, 6, 8], dtype=uint8)
我们看到计算机使用数组的形式来储存这些数据,(60000,28,28)代表着有60000个图片,每一个的大小是28*28。而labels则更加直接,每一个位置对应于图片的位置为数字的大小。
接下来,看一下测试集的情况,其实完全类似:
>>> test_images.shape
(10000, 28, 28)
>>> len(test_labels)
10000
>>> test_labels
array([7, 2, 1, ..., 4, 5, 6], dtype=uint8)
搭建训练框架
from keras import models
from keras import layers
network = models.Sequential()
network.add(layers.Dense(512, activation='relu', input_shape=(28 * 28,)))
network.add(layers.Dense(10, activation='softmax'))
我们从keras引入了models 和layers,前者用来搭建整个模型框架。
- models.Sequential()这一句代表我们之后加layers是按照顺序从前往后加。
- 至于layers.Dense则是设置这一层的具体参数第一个为输出维度,第二项为激活函数类型,第三维为输入的形状,我们看到shape的第二项逗号之后没有东西,这个是根据输入数据来自动补的,例如我们输入数据为

个,那么第二项则是
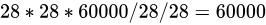
,也就是说总数一定要是

的整数倍,不然会报错。
- 第二层layers输出为10,激活函数为softmax,就是将10个输出里面最大取1,最小取0,最后就得到了我们需要的预测值,至于为什么这里不需要输入,这就是keras的好处了,它自动计算需要的输入的大小,所以我们只需要关心最开始的输入大小,不需要逐层计算每一层的大小,这对于深层网络的搭建非常方便。
network.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])设置优化器,损失函数,还有需要显示的指标,这三个都是可以改的,大家可以
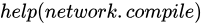
来查看更多有关这些参数的东西。
预处理数据和标签
train_images = train_images.reshape((60000, 28 * 28)) train_images = train_images.astype('float32') / 255 test_images = test_images.reshape((10000, 28 * 28)) testimages = testimages.astype('float32') / 255输入的图像是unit8类型的,我们转化为float32,因为python里面很多运算只支持float32类型,然后将形状拉长为28*28的,因为我们构建的网络是一个简单的全连接网络,也就是逐个像素点的预测,最后是归一化的问题,由于像素值一开始都是0-255,我曾经就感到很奇怪为什么要全部归一化到0-1,不就是等比例缩放吗,为什么会影响到收敛性呢,感兴趣的同学可以搜索神经网络正则化相关的知识。
from keras.utils import to_categorical train_labels = to_categorical(train_labels) testlabels = tocategorical(testlabels)对标签下手,将原来的十个数字转化成分类的编码,这个具体为什么以后会再详细介绍。
开始训练!
>>> network.fit(train_images, train_labels, epochs=5, batch_size=128) Epoch 1/5 60000/60000 [==============================] - 9s - loss: 0.2524 - acc: 0.927 Epoch 2/5 51328/60000 [========================>.....] - ETA: 1s - loss: 0.1035 - acc: 0.9692keras还有一个好处就是它的可视化做的比较好,开始训练以后,有一个动态的小箭头告诉你训练到什么程度了,让人感到很舒服。再解释一下代码,第一项,放入训练数据,第二项放入对应的标签,epochs代表要训练多少批次,因为这个优化是一个循环往复的过程,需要不断的循环才能逐渐靠近最优,最后就是batch_size,这是minibatch,这也是正则化相关内容,如果每次都将全部的数据集放进来才训练一次,那么我们的训练进度就会很慢,所以我们就会把数据分成很多小批次,一次喂一点进去,而为什么偏偏是128呢,这是因为计算机是二进制的,给它2的次方的数,运算会更加快。
评估训练效果
>>> test_loss, test_acc = network.evaluate(test_images, test_labels) >>> print('test_acc:', test_acc testacc: 0.9785通过上述指令,在训练完以后network输入测试集和对应的标签来进行测试。















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









