









STRUG:Structure-Grounded Pretraining for Text-to-SQL
该论文已被 NAACL 2021 所接收。
pdf:https://arxiv.org/abs/2010.12773
总结:本文通过使用现有的数据集 ToTTo 来构造预训练任务,包含3个训练目标,分别是 column grouding(预测列名是否在utterance中被提到,包括直接提到和提到相关的value)、value grounding(预测一个utterance的token是否是value)、column-value mapping(预测每个utterance的token和column的关系,即对每个token进行多分类预测,类别是所有的列名),来增强模型对于 column、value、以及两者之间的映射关系的捕捉能力。此外,本文对 Spider 的验证集部分数据的 utterance 进行了修改,即把一些显式提到的列名去掉了,或者改写了表达,使得数据更加符合真实情况,得到了 Spider-Realistic 验证数据集。
摘要
学习捕捉文本与表格之间的对齐关系对于像 text-to-sql 这类表格相关的任务来说是至关重要的。模型需要正确识别自然语言问句中对于列名、列值的引用,同时需要对应到正确的数据库模式上。本文提出了一种新颖的弱监督的基于结构预训练的 STRUG 模型,该模型可以基于一个文本-表格平行语料库,来有效地学习捕捉文本-表格对齐关系。本文提出了3个新颖的预测任务:column grouding、value grounding 和 column-value mapping,然后在不需要复杂sql标注的情况下使用弱监督的方式来训练这些任务。此外,为了评估模型在真实场景下的表现,本文基于Spider构建了一个新的评估数据集 Spider-Realistic,其在 spider 的验证集基础上移除了对列名的显式引用,同时本文还采用了两个已知的单数据库的text-to-sql数据集来评估模型的效果。STRUG在Spider和Spider-Realistic数据集上显著超越了BERT-large,同时在 WikiSQL数据集上效果同样有提升。
引言

首先,作者指出 text-to-sql 任务的一个关键挑战就是 文本-表格对齐问题,即正确识别自然语言文本中对于列和列值的引用,同时将之对应到正确的schema上。以图1的上半部分中的例子来说,模型首先需要识别出 自然语言文本中对列名的引用有 total credits 、department,同时有列值的引用 History,然后把这些引用对应到正确的schema上去。造成这种困难有3个原因:
- 1、用户对于数据库中的列名会有各种各样不同的表达(如缩写、同义词、单复数等),而这些表达与数据库原始表名是不一致的;
- 2、模型需要对新的数据库schema有泛化能力,即在训练时没见到过数据库schema;
- 3、某些时候,由于数据库表巨大,无法对每个列值进行搜索,或者说无权限访问列值的时候,模型依旧需要识别列值引用,及其对应的列名。
文本-表格对齐也广泛存在于文本-表格语料库(文中列举了现有的3个语料库)中,这种类型的数据相比于 text-to-sql 数据集更容易收集得到。如图1下半部分所示,自然语言文本中有3个列值引用11417、Pune Junction 和 Nagpur Junction,分别对应到的列名是 train number、departure station和arrival station。这种对齐信息很容易利用表格内容或者人工标注得到。本文通过预训练方式来充分平行语料中的文本-表格对齐信息,来帮助下游的text-to-sql任务。
本文通过大量的实验表明:
- 1、在Spider数据集上,RAT-SQL + STRUG 的效果优于 RAT-SQL + BERT-large,同时在 Spider-Realistic数据集上也有较大提升,这进一步证明了本文预训练框架在解决文本-表格对齐问题上的优越性;
- 2、STRUG也可以帮助减少对昂贵的大规模监督训练语料的需求。通过在WikiSQL数据集上使用少量训练数据进行训练,本文的预训练方法可以较大幅度提升模型性能,并且超越现在已有的预训练方法。
模型
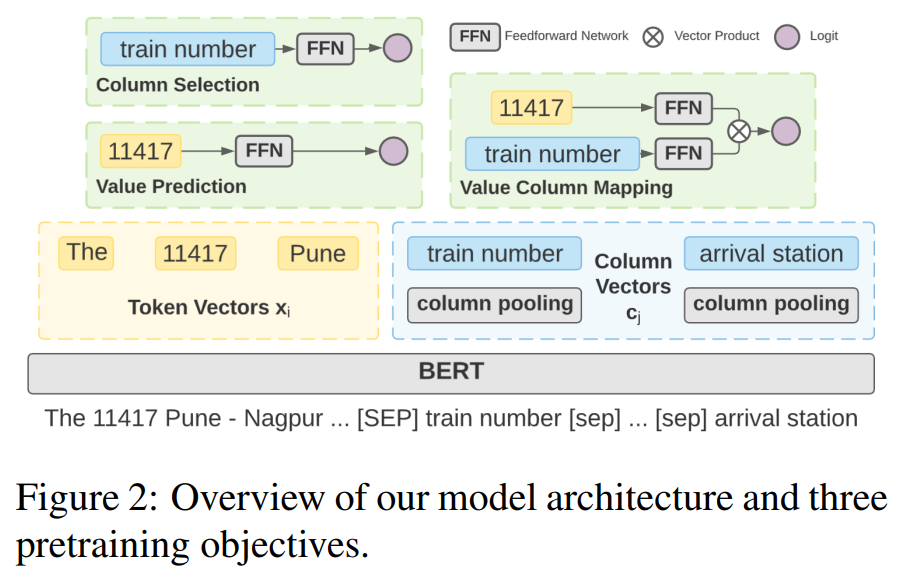
如图2所示为本文的预训练框架 STRUG,可以看到基本结构很简单,就是在 BERT 层的上面对于3个子任务(Column Selection、Value Prediction、Value Column Mapping),分别接了3个简单的分类层,多任务训练。对于下游任务,本文模型可以像BERT一样轻松接入现有模型。如图2所示,模型输入是将 自然语言文本 和 表格的所有列名拼接成一个序列,中间用<SEP>分割。对于像 train number这样有多个token的列名,其最终的列表征向量是通过该列首尾token的embedding相加取平均得到。
Column Grounding
在 text-to-sql 任务中,一项重要的任务就是找到正确的列名并填入SQL中。而在文本-表格平行语料中,也有相似的任务,即选出文本中提到的列名。这不仅需要模型能够理解列名的语义信息,同时能够结合自然语言文本的上下文表征,来推断该列名和对应的文本之间的关系。
给定列名的表示向量 C j C_j Cj,预测其是否在文本中被提到过,即对每列来说本质是一个二分类任务。 p j c = f ( c j ) p_j^c = f(c_j) pjc=f(cj)。label为 y j c ∈ 0 , 1 y_j^c \in {0, 1} yjc∈0,1。Loss为 L c L_c Lc。
Value Grounding
预测一个utterance的token是否是value,同 Clomun Grounding类似,对每个文本token进行二分类预测:对于每个token x i x_i xi, p i v = f ( x i ) p_i^v = f(x_i) piv=f(xi),label为 y i v ∈ 0 , 1 y_i^v \in {0, 1} yiv∈0,1。Loss为 L v L_v Lv。
Column Value Mapping
预测每个utterance的token和column的关系,即对每个token进行多分类预测,类别是所有的列名。Loss为 L c v L_{cv} Lcv。
Final Loss
3个子任务的loss等权相加,本文尝试过对3个loss使用不同权重,但效果并无多大变化,故采用等权相加。
L
=
L
c
+
L
v
+
L
c
v
L = L_c + L_v + L_{cv}
L=Lc+Lv+Lcv
实验
数据集信息
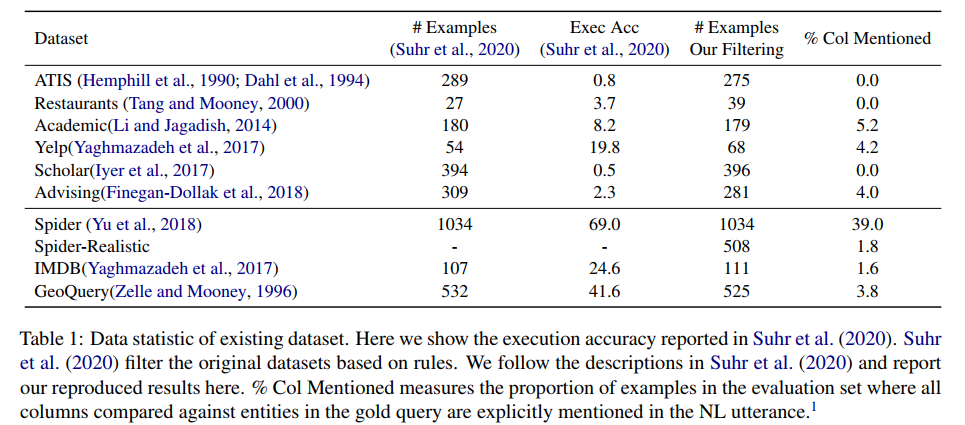
Spider-Realistic数据样例

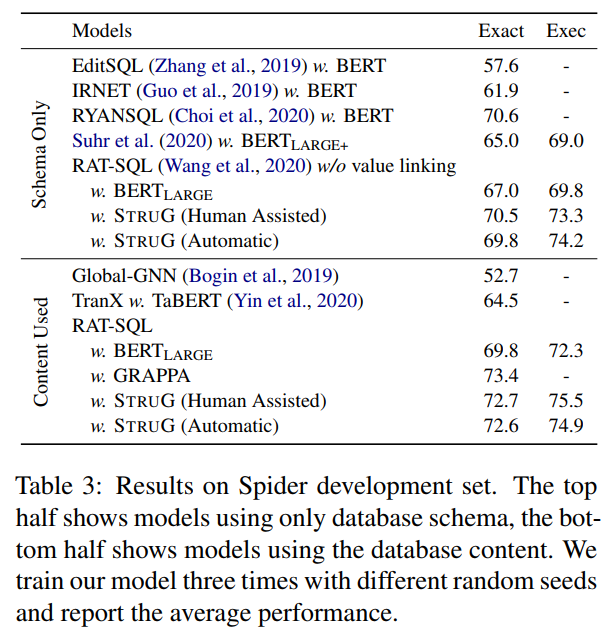
Spider验证集上的实验结果,上半部分展示的只使用 数据库schema 的结果,下半部分展示了使用了数据库内容的结果。
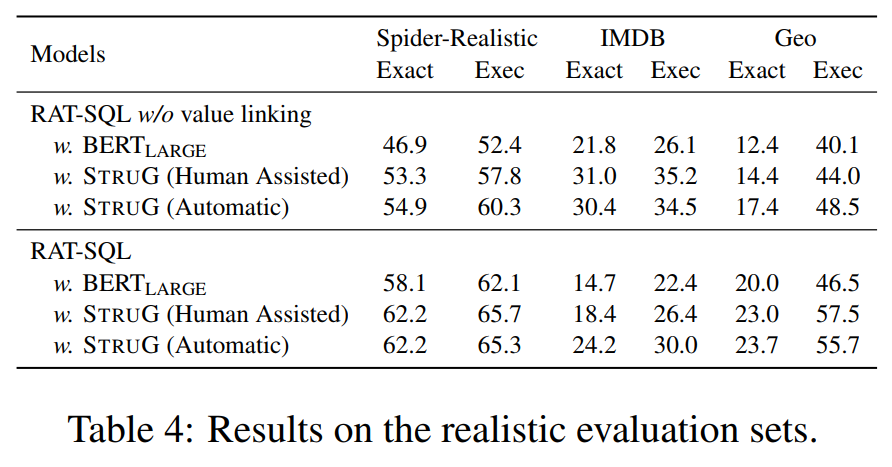
在 Spider-Realistic数据集上的实验结果:
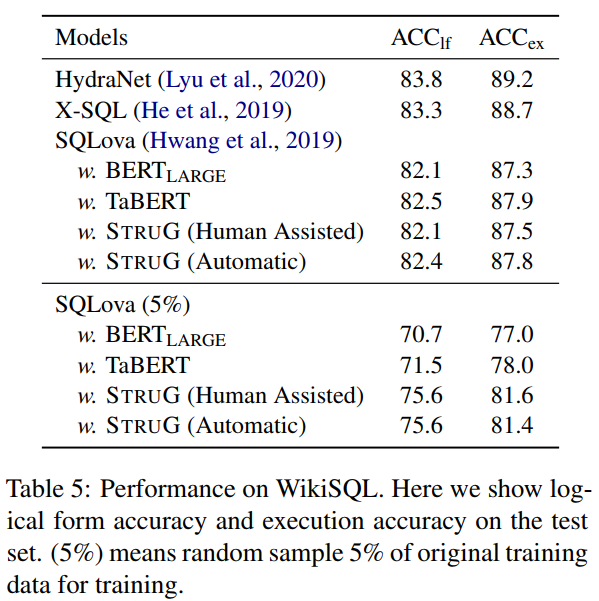
WikiSQL上的实验结果:















 2770
2770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









