









Structure-Grounded Pretraining for Text-to-SQL
NAACL,2021
https://arxiv.org/pdf/2010.12773.pdf
Abstract
本文提出了一种新的基于弱监督结构的 text-to-SQL 的预训练框架(STRUG),该框架能够有效地学习基于平行 text-table 语料库的对齐。为此设置一组新的预测任务:列定位、值定位和列-值映射,并使用弱监督训练,不需要复杂的SQL注释。
此外,基于 Spider 创建了一个新的评估集 Spider-Realistic,并显式地删除了列名,并采用两个现有的单数据库 text-to-SQL 数据集。
STRUG 在 Spider 和现实评估集上的性能显著优于 B E R T L A R G E BERT_{LARGE} BERTLARGE,在 WikiSQL 上带来一致的改进。
1 Introduction
- 学习 text-table 对齐具有挑战性,原因:
- 模型需要共同理解NL语句和数据库模式;
- 模型需要能够泛化到新的数据库模式和参考语言(这些在训练集是看不到的);
- 不使用单元值,即无需在数据库上进行详尽的搜索和匹配。
- 提出了一种新的基于弱监督结构的 text-to-SQL 的预训练框架。
- 方法:设计了一组预测任务(列定位、值定位和列-值映射),并利用包含NL语句和表数据的并行语料库进行优化。
- 实现:利用现有的 table-to-text generation 数据集 ToTTo 进行预训练,并通过弱监督获得三个任务的标签。
- 基于 Spider 创建了一个新的评估集 Spider-Realistic
- 动机:实际的自然语言表达中往往不明确地提到确切的列名
- 方法:删除话语中显式提到的列名
- 实验
- 采用与BERT相同的模型架构,并在顶部使用简单的分类层进行预训练。
- 对于下游任务,STRUG 可作为一个 text-table encoder,与任何现有的最先进的模型集成。
- 结果
- 使用 STRUG 作为编码器的性能明显优于 B E R T L A R G E BERT_{LARGE} BERTLARGE。在 Spider-Realistic 上有更大的改进。
- STRUG也有助于减少对大量昂贵的监督训练数据的需求。
2 Related Work
Pretraining for Text-Table Data:
- TaBERT & TAPAS
- 方法:通过利用大量的web表及其文本上下文,共同学习文本表表示。他们将表格压平,并使用特殊的嵌入来建模结构信息。然后使用一个屏蔽语言模型(MLM)目标从 text-table 数据中学习知识。
- 缺点:MLM最初是为单个NL语句建模而设计的,这使得它在捕捉一对序列之间的关联方面很弱,比如文本和表之间的对齐。
- Grappa
与现有的语义解析数据增强工作有相似之处。优势主要来自于合成数据。
方法:首先构建合成的 question-SQL 对(利用从现有的 text-to-SQL 数据集导出的同步上下文无关语法),然后使用SQL语义预测目标从合成数据中学习组合归纳偏差。
目前,还缺乏充分利用平行 text-table 语料库中自然存在的对齐知识的模型,这也是本文研究的目标。
3 Weakly Supervised Multitask Pretraining
3.1 Motivation
- 目标是通过三种基于结构的任务直接捕获 text-table 对齐知识。
- 预测任务是为寻找非结构化文本和结构化表模式之间的关联而设计的,并且与 text-to-SQL 密切相关。这样,学习到的对齐知识可以有效地转移到下游任务中,提高最终的绩效。
3.2 Pretraining Objectives
使用与BERT相同的模型架构,并为三个基于结构的任务添加简单的分类层。
将NL描述和列头拼接,送入BERT,得到NL描述每个token的上下文表示 { x i } \left\{x_{i}\right\} {xi} 和 每个列的上下文表示 { c j } \left\{c_{j}\right\} {cj}。

- Column grounding——定义为一个二元分类任务(不能访问value值)
对表格中的每一列,使用一层前馈网络得到预测 p j c = f ( c j ) p_{j}^{c}=f\left(\mathbf{c}_{j}\right) pjc=f(cj)
L c = CrossEntropy ( softmax ( p i c ) , y j c ∈ 0 , 1 ) \mathcal{L}_{c} = \text { CrossEntropy }\left(\operatorname{softmax}\left(p_{i}^{c}\right), y_{j}^{c} \in 0,1\right) Lc= CrossEntropy (softmax(pic),yjc∈0,1) - Value grounding——定义为一个二元分类任务(表的内容不可用,模型有必要根据表模式推断可能的 value types,并使用它来筛选 value。)
模型首先识别实体短语,然后只保留与关联表相关的短语。
对每个token x i x_i xi,使用一层前馈网络得到预测 p i v = f ( x i ) p_{i}^{v}=f\left(\mathbf{x}_{i}\right) piv=f(xi)
L v = CrossEntropy ( softmax ( p i v ) , y j v ∈ 0 , 1 ) \mathcal{L}_{v} = \text { CrossEntropy }\left(\operatorname{softmax}\left(p_{i}^{v}\right), y_{j}^{v} \in 0,1\right) Lv= CrossEntropy (softmax(piv),yjv∈0,1) - Column-Value mapping——定义为NL标记和列之间的匹配任务
对每个token x i x_i xi,将其与每一列 c j c_j cj 配对,计算 x i x_i xi 匹配 c j c_j cj的概率 p i , j c v = f ( [ x i , c j ] ) p_{i, j}^{c v}=f\left(\left[\mathbf{x}_{i}, \mathbf{c}_{j}\right]\right) pi,jcv=f([xi,cj])。
L c v = CrossEntropy ( softmax ( p i c v ) , y i c v ∈ 0 , 1 ) \mathcal{L}_{c v} = \text { CrossEntropy }\left(\operatorname{softmax}\left(p_{i}^{c v}\right), y_{i}^{c v} \in 0,1\right) Lcv= CrossEntropy (softmax(picv),yicv∈0,1)
总损失: L = L c + L v + L c v \mathcal{L}=\mathcal{L}_{c}+\mathcal{L}_{v}+\mathcal{L}_{c v} L=Lc+Lv+Lcv
3.3 Pretraining Data
ToTTo 包含120,761个NL描述和使用启发式方法从维基百科自动收集的相应的web表。此外,它还提供了单元级注释,突出显示(黄色高亮)了描述中提到的单元,并删除了不相关或含糊的短语。

如图,
- 黄色高亮:ToTTo 提供的单元注释
- 虚线高亮: 通过字符串匹配获得的单元注释
使用两种预训练设置
- 人工辅助设置:使用单元注释以及修改后的描述。
- 自动设置:使用单元注释和原始描述,通过精确的字符串匹配获得单元注释。
在这两种设置中,单元值只用于预训练数据的构建,而不是作为预训练模型的输入。
提高泛化能力,还加入了两种数据增强技术。
- 模拟多表:原始并行语料库中每个训练实例只包含一张表,随机抽取 K n e g K_{neg} Kneg 个表作为负样本,并附加到输入序列中。
- 更好地利用表内容:将NL中匹配的短语随机替换为同一列的单元的值。
4 Curating a More Realistic Evaluation Set
5 Experiments
5.1 Benchmarks and Base Models
5.2 Implementation Details
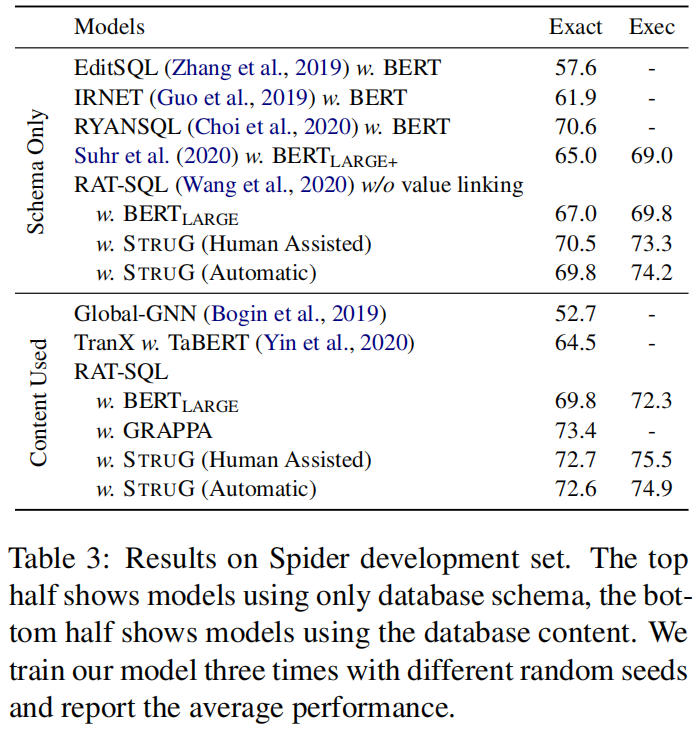
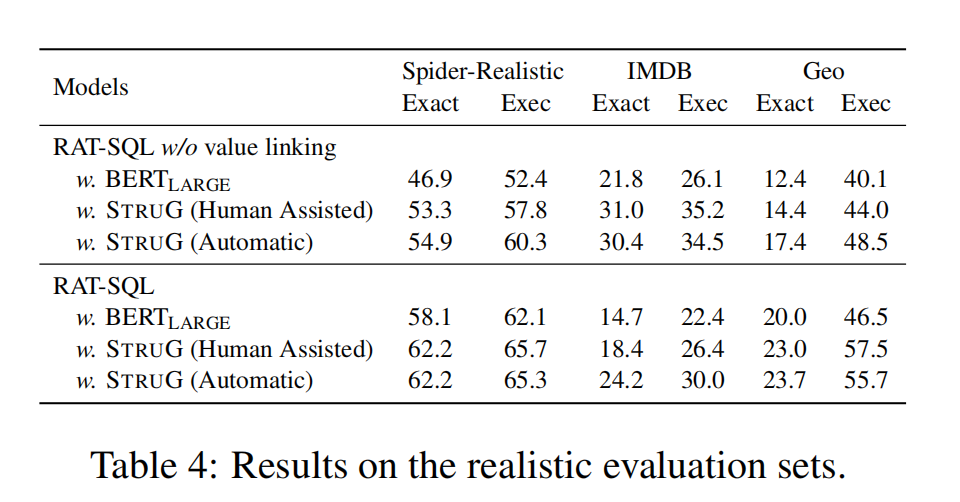
5.3 Main Results















 5217
5217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









