







文心一言
Leaky ReLU(Leaky Rectified Linear Unit)函数是深度学习领域中的一种激活函数,主要用于解决ReLU(Rectified Linear Unit)函数在负值区域为零的问题。ReLU函数在输入为正时保持原样,而在输入为负时则输出为零,这可能导致某些神经元在训练过程中“死亡”或停止学习。
Leaky ReLU函数在负值区域有一个小的正斜率,使得即使输入为负,输出也不会完全为零。这有助于避免神经元死亡的问题,并使网络能够学习更多的特征。
Leaky ReLU函数的数学表达式如下:
f(x) = alpha * x (当 x < 0)
f(x) = x (当 x >= 0)
其中,alpha是一个小的正数,通常设置为0.01或其他接近零的值。这意味着当输入为负时,输出将是输入的alpha倍,而不是零。
Leaky ReLU函数具有以下优点:
- 缓解神经元死亡问题:由于负值区域有非零输出,Leaky ReLU函数有助于避免ReLU中可能出现的神经元死亡问题。
- 计算效率高:与其他复杂的激活函数相比,Leaky ReLU函数的计算相对简单,因此在训练大型神经网络时具有较高的效率。
- 提高模型性能:在某些情况下,使用Leaky ReLU作为激活函数可以提高模型的性能,因为它允许网络学习更多的特征。
然而,值得注意的是,尽管Leaky ReLU在某些方面优于ReLU,但并非所有情况下都是最佳选择。在实际应用中,应根据具体任务和数据集来选择适合的激活函数。此外,还有其他激活函数(如PReLU、ELU等)也用于解决ReLU的问题,并可能在不同场景下具有更好的性能。
智谱清言
Leaky ReLU(泄漏修正线性单元)是深度学习中的一种激活函数,旨在解决ReLU(修正线性单元)在训练过程中可能遇到的梯度消失问题。
传统的ReLU激活函数定义为:

在ReLU函数中,正数的激活值保持不变,而负数的激活值被置为0。这在训练深度神经网络时非常有用,因为它简化了计算并提高了效率。然而,当使用ReLU激活函数时,可能会遇到训练缓慢的问题,尤其是在网络的早期层,因为梯度可能会在网络的反向传播过程中消失(即,梯度变为非常小的值,接近零)。这意味着网络的后续层几乎不会更新其权重,因为它们的输入(来自前一层)的梯度为零。
为了解决这个问题,Leaky ReLU被提出。Leaky ReLU的主要区别在于它对负数输入的处理方式。而不是将负数输入的激活值设置为0,它允许一个小的、非零的泄漏项,通常是一个小的正数(例如0.01)。这样,即使输入是负数,也仍然有一个非零的梯度可以传播,从而有助于缓解梯度消失的问题。
Leaky ReLU的函数定义如下:
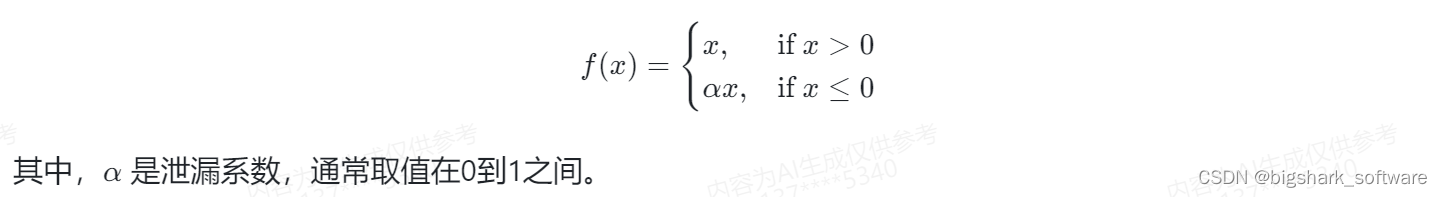
使用Leaky ReLU可以提高训练的速度和网络的性能,尤其是在处理具有许多负数输入的数据时。然而,Leaky ReLU也有一些缺点,比如可能会增加训练的复杂性,并且在某些情况下可能会导致训练不稳定。因此,是否使用Leaky ReLU取决于具体的应用场景和数据集。
豆包
Leaky ReLU是一种修正线性单元(Rectified Linear Unit, ReLU)函数,也是深度学习中常用的激活函数,通常指代以斜坡函数及其变种为代表的非线性函数。相比于标准的ReLU函数,Leaky ReLU在输入值小于0时有非0的负数输出,这种函数作为一种人工神经元的激活函数,被广泛应用于深度学习和神经网络的模型中。
Leaky ReLU函数对于负数部分不再输出零,而是输出一个很小的负数,通常用一个小的斜率α乘以输入。其公式为:。该函数的优点是解决了ReLU的神经元死亡问题,因为负数部分有一个小的梯度,其缺点是对于α的选择比较敏感,需要调参。
讯飞星火
Leaky ReLU函数是深度学习中常用的激活函数之一,它通过引入一个很小的线性分量来调整负输入值的梯度问题。
Leaky ReLU函数的主要特点包括:
- 解决梯度问题:在标准ReLU函数中,当输入值小于零时,输出为零,并且梯度也为零。这可能导致神经元在训练过程中失效,因为它们不会再有任何变化,这个问题被称为“神经元死亡”。Leaky ReLU通过为负输入值引入一个非零的梯度来解决这一问题,通常这个梯度是一个非常小的值,比如0.01倍的输入值。
- 参数设置:Leaky ReLU函数中通常会引入一个超参数α(alpha),这个值决定了负输入时的梯度大小。在实际应用中,α经常被设置为0.01。
- 避免神经元死亡:由于Leaky ReLU在输入小于零的情况下也能计算得到一个梯度,因此它可以在一定程度上避免神经元死亡的问题,使得网络能够更好地学习。
- 稀疏性保持:尽管Leaky ReLU对负输入有响应,但它仍然保持了ReLU函数的单侧抑制特性,即能够使一部分神经元的输出为零,这有助于模型的稀疏性。
总的来说,Leaky ReLU函数通过在负输入区域引入一个小的梯度,解决了标准ReLU函数在负输入时梯度为零的问题,从而提高了神经网络的学习能力和稳定性。















 4206
4206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











