







什么是数据库
数据库(Database)是一个结构化的数据集合,它允许用户存储、检索、更新和管理数据。数据库是信息系统的核心组件,广泛应用于各种领域,如金融、医疗、教育、科研等。数据库的主要特点包括:
结构化存储:数据库以一定的结构(如表、记录、字段等)来组织数据,使得数据易于存储、访问和管理。
数据共享:多个用户或应用程序可以同时访问和使用数据库中的数据,实现数据的共享和协同工作。
数据完整性:数据库系统通过数据完整性约束(如主键、外键等)来保证数据的正确性和一致性,防止数据冗余和错误。
数据安全性:数据库系统提供访问控制和安全机制,确保只有授权的用户才能访问和修改数据,保护数据不被非法访问或篡改。
并发控制:当多个用户同时访问数据库时,数据库系统通过并发控制机制来协调不同用户之间的操作,防止数据冲突和不一致。
数据库系统通常由数据库、数据库管理系统(DBMS)和数据库管理员(DBA)组成。数据库是数据的实际存储地,DBMS是管理数据库的软件系统,而DBA则负责数据库的规划、设计、维护和管理。
数据库类型
数据库的类型有很多,最常见的是关系型数据库(Relational Database),如MySQL、Oracle、SQL Server等。关系型数据库基于数学中的关系理论,使用表格的形式来存储数据,支持SQL(Structured Query Language)语言进行数据操作和管理。此外,还有非关系型数据库(NoSQL Database)如MongoDB、Redis等,它们更适合处理大量、非结构化的数据。
关系型数据库
这种数据库是应用开发的小伙伴最常见和最常用的数据库,请抓关键字“关系型”,什么意思呢?看下图:
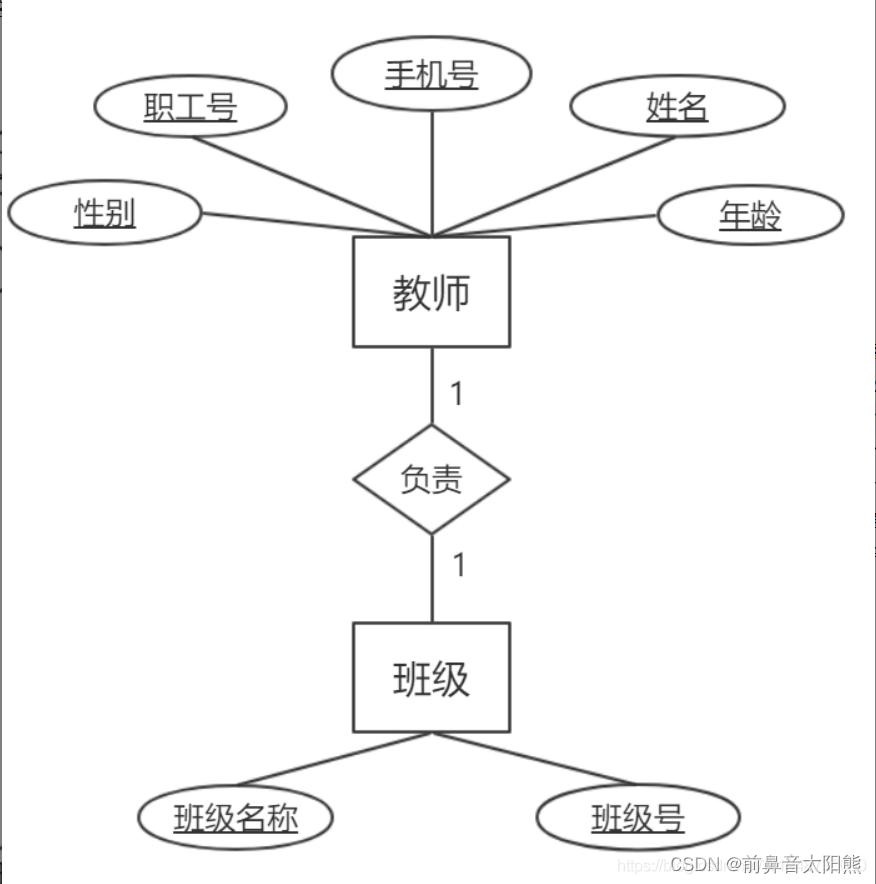
这就是关系型数据库建立的实体关系图(ER图,E(Entity 实体)、R(Relation 关系))实体对应现实中一个一个实际物体,关系是这些物体发生的交互,物体还有对应的一些属性,很简单对不对。
数据库的本质是提供了一个高效存储和检索数据的工具
数据库存储的本质就是一种文件,只不过通过数据库本身的引擎和提供的客户端工具能更好、跟方便的对文件的存储模式、存储机制、存储类型等进行管理
关系型数据库(Relational Database)是一种数据库管理系统,它使用关系模型来组织和管理数据。关系模型是由数学家E.F. Codd在1970年提出的,它基于数学中的集合论和关系代数。关系型数据库使用表格(或称为关系)来存储数据,表格中的每一行表示一个数据记录,每一列表示一个数据属性。
关系型数据库的主要特点包括:
- 结构化存储:数据以表格的形式进行组织,每个表格都有明确的列和行,使得数据易于查询和管理。
- 数据完整性:通过定义主键、外键、唯一约束等,关系型数据库能够确保数据的完整性和一致性。
- 数据安全性:关系型数据库提供用户访问控制和权限管理,确保只有授权的用户才能访问和修改数据。
- SQL支持:关系型数据库使用SQL(Structured QueryLanguage)作为查询和管理数据的标准语言,提供了丰富的数据操作功能。
- 事务处理:关系型数据库支持事务处理,确保多个数据库操作要么全部成功,要么全部失败,保持数据的一致性。
非关系型数据库
最常见的是Redis,很多小伙伴要问了,这不是缓存么?咋成数据库了?。其实“缓存”只是它的应用场景,Redis本质就是一个键值对存储的数据库,是非关系型的。看下图:
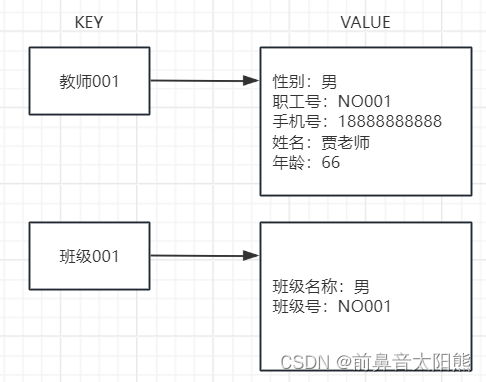
非关系型数据库的本质还是提供了一个高效存储和检索数据的工具
但是适用的场景不同,衍生出来对数据存储、检索不同的需求和性能指标
非关系型数据库(NoSQL Database)是一类与关系型数据库不同的数据库管理系统,它们不遵循传统的关系模型,而是采用其他数据结构或模型来存储和组织数据。非关系型数据库通常用于处理大量、非结构化的数据,或者在需要高并发、高可扩展性的场景下使用。
非关系型数据库的主要特点包括:
- 灵活的数据模型:非关系型数据库采用键值对、文档、列存储、图形等灵活的数据模型,不依赖于固定的表格结构,可以更好地适应数据的变化和多样性。
- 高性能和可扩展性:非关系型数据库通常具有更高的读写性能和更好的可扩展性,可以轻松地处理海量数据和高并发请求。
- 简单的API和操作:非关系型数据库通常提供简单的API和操作方式,使得开发和部署更加快速和方便。
- 无事务处理:与关系型数据库不同,非关系型数据库通常不支持事务处理,这意味着它们不能保证数据的强一致性。
常见的非关系型数据库包括MongoDB(面向文档的数据库)、Cassandra(列存储数据库)、Redis(键值存储数据库)、HBase(分布式列存储数据库)、Neo4j(图形数据库)等。这些数据库各有特点,适用于不同的场景和需求。
非关系型数据库的优点包括灵活性、高性能、可扩展性等,它们通常用于处理大量非结构化数据、实时数据分析、高并发应用等场景。然而,由于它们不支持事务处理和复杂的查询操作,因此在需要强一致性和复杂查询的场景下,可能仍然需要使用关系型数据库。
对比表
| 特点 | 关系型数据库 | 非关系型数据库 |
|---|---|---|
| 数据模型 | 固定表格结构,基于关系模型 | 灵活的数据模型,如键值对、文档、列存储、图形等 |
| 数据一致性 | 支持ACID事务,强一致性 | 通常不支持事务处理,最终一致性 |
| 数据完整性 | 通过约束(如主键、外键)保证数据完整性 | 依赖应用层保证数据完整性 |
| 查询能力 | 支持复杂的SQL查询 | 查询能力较弱,通常依赖于特定的API或查询语言 |
| 扩展性 | 较差的扩展性,固定的表结构 | 良好的扩展性,适应大量数据和高并发 |
| 性能 | 读写性能通常较低,尤其是在处理大量数据时 | 读写性能较高,适用于实时数据处理 |
| 适用场景 | 结构化数据存储,复杂查询,事务处理 | 非结构化数据存储,实时数据分析,高并发应用 |
什么是SQL
SQL(Structured Query Language)是一种用于管理关系型数据库的语言。它是数据库管理系统(DBMS)的标准编程语言,用于执行各种数据库操作,如查询、插入、更新和删除数据,以及创建和管理数据库对象,如表、索引和视图等。
抓关键:
1 SQL是一种编程语言:注意了,它也是编程语言哦。也就意味着它有编程语言的特性,比如变量定义、数据类型、函数定义等等
2 管理关系型数据库的语言:注意了,是用来管理关系型数据库的,所以他的英文全称第一个是“Structured”结构化的。那非结构化用什么来管理数据存储和查询呢?一般使用它们自己的语言(但是就不叫SQL了,比如MongoDB的叫MQL(MongoDB Query Language))或者API
SQL的基本特点
以下是SQL的一些基本功能和特点:
-
数据查询:SQL提供了SELECT语句,用于从数据库表中检索数据。您可以根据各种条件筛选数据,并对结果进行排序、分组和聚合。
-
数据插入:使用INSERT INTO语句,您可以将新数据插入到数据库表中。您可以插入单条记录,也可以一次插入多条记录。
-
数据更新:UPDATE语句用于修改现有数据库表中的数据。您可以根据条件更新记录中的特定字段。
-
数据删除:DELETE语句用于从数据库表中删除数据。您可以根据条件删除记录,也可以删除整个表中的数据。
-
表操作:SQL允许您创建新表(CREATE TABLE)、修改表结构(ALTER TABLE)、删除表(DROP TABLE)以及为表添加索引(CREATE INDEX)等。
-
数据完整性:SQL支持定义表的约束(CONSTRAINTS),以确保数据的完整性和准确性。常见的约束包括主键(PRIMARY KEY)、外键(FOREIGN KEY)、唯一性(UNIQUE)和非空(NOT NULL)等。
-
聚合函数:SQL提供了聚合函数,如COUNT、SUM、AVG、MAX和MIN等,用于对一组值执行计算并返回单个值。
-
事务处理:SQL支持事务处理,确保多个数据库操作要么全部成功,要么全部失败,以保持数据的一致性。
-
视图:您可以创建视图(VIEW),它是一个虚拟表,基于一个或多个实际表的查询结果。视图可以用于简化复杂的查询、限制用户对数据的访问以及提供数据抽象。
-
存储过程和函数:SQL允许您创建存储过程和函数,它们是预编译的SQL代码块,可以在数据库中存储和重复使用。存储过程和函数可以提高性能、减少网络流量,并简化复杂的数据库操作。
SQL是一种声明性语言,这意味着您只需要告诉数据库您想要做什么,而不需要指定如何去做。数据库管理系统负责优化和执行查询。
SQL语句的类型
我们先想象一下,你现在要创建一所学校,那么要怎么来做呢?
- 先出设计图,定好学校的蓝图,然后开始建设
- 建设好之后,要出管理措施,对学校进行管理
- 管理过程中,要给不同的人分配不同的职责和权限
- 事务的控制,教研任务、教学任务、考试等等,每一项都是一个独立完整的事项,从头到尾要有计划和监督,前后一致,出现问题及时纠正和调整,过程中实施监控,最终保证结果正确
而SQL的设计思想,就和上面的过程很像,我们再回顾下上面说到的“数据库的本质是提供了一个高效存储和检索数据的工具”,是用来管理存储的数据,那么也要从四个部分来对数据进行管理:
- 数据定义:定义好整个数据的结构,就是一个“数据的设计蓝图”
- 数据操作:增、删、改、查,对数据进行管理
- 数据控制:谁、什么角色、能对什么数据、进行什么操作,给不同的使用和操作数据的角色分配不同的职责和权限
- 事务控制:将一个任务,保证完整、正确的执行,保证原子性、一致性
是不是和建一座学校一样?而且你会发现和做其他事情也一样,划重点:
所有的现代科学都是仿生学。是模仿人类本身或者人类活动,来进行高度抽象和总结得出的科学理论,再结合实践不断完善得出的。
也就意味着。我们学习很多科学理论的时候,结合实际生活中的例子可以更好的理解,同时呢也可以把这些理论泛华应用到平时的工作和学习中,来解决其他问题
正所谓“一法通百法通”
SQL语句的类型 详细介绍
在SQL(Structured Query Language)中,根据功能和用途的不同,可以将SQL语句分为几种类型。以下是SQL中常见的几种语言分类及其简要介绍:
1. DDL (Data Definition Language) - 数据定义语言
- CREATE - 用于创建数据库对象,如表、索引、触发器、视图等。
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
column3 datatype,
....
);
- ALTER - 用于修改数据库对象的结构。
ALTER TABLE table_name
ADD column_name datatype;
- DROP - 用于删除数据库对象,如表、索引、触发器等。
DROP TABLE table_name;
- TRUNCATE - 用于删除表中的所有数据,但保留表结构。
TRUNCATE TABLE table_name;
2. DML (Data Manipulation Language) - 数据操作语言
- SELECT - 用于从数据库表中查询数据。
SELECT column1, column2, ...
FROM table_name
WHERE condition;
- INSERT - 用于向数据库表中插入新数据。
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);
- UPDATE - 用于修改数据库表中的现有数据。
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
- DELETE - 用于从数据库表中删除数据。
DELETE FROM table_name WHERE condition;
3. DCL (Data Control Language) - 数据控制语言
- GRANT - 用于授予用户或角色对数据库对象的访问权限。
GRANT SELECT, INSERT ON table_name TO user_name;
- REVOKE - 用于撤销用户或角色对数据库对象的访问权限。
REVOKE SELECT, INSERT ON table_name FROM user_name;
4. TCL (Transaction Control Language) - 事务控制语言
- COMMIT - 用于提交事务,即将事务中的所有更改保存到数据库中。
COMMIT;
- ROLLBACK - 用于回滚事务,即撤销事务中的所有更改。
ROLLBACK;
- SAVEPOINT - 用于设置事务的保存点,以便在之后可以回滚到该点。
SAVEPOINT savepoint_name;
- ROLLBACK TO - 用于回滚到指定的保存点。
ROLLBACK TO savepoint_name;
5. DDL (Data Definition Language) - 数据定义语言(续)
- CREATE INDEX - 用于创建索引,以提高查询性能。
CREATE INDEX index_name
ON table_name (column1, column2, ...);
- CREATE TRIGGER - 用于创建触发器,以在特定事件(如INSERT、UPDATE或DELETE)发生时自动执行代码。
CREATE TRIGGER trigger_name
TRIGGER_TIME TRIGGER_EVENT
ON table_name
FOR EACH ROW
EXECUTE PROCEDURE procedure_name();
- CREATE VIEW - 用于创建视图,即基于SQL查询的虚拟表。
CREATE VIEW view_name AS
SELECT column1, column2, ...
FROM table_name
WHERE condition;
这些只是SQL语言的一部分,实际上SQL还有很多其他的特性和命令。不过,了解这些基本的分类和命令可以帮助你更好地理解SQL的功能和用途。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











