






前沿重器
栏目主要给大家分享各种大厂、顶会的论文和分享,从中抽取关键精华的部分和大家分享,和大家一起把握前沿技术。具体介绍:仓颉专项:飞机大炮我都会,利器心法我还有。(算起来,专项启动已经是20年的事了!)
2023年文章合集发布了!在这里:又添十万字-CS的陋室2023年文章合集来袭
往期回顾
RAG在整个大模型技术栈里的重要性毋庸置疑,而在RAG中,除了大模型之外,另一个不可或缺的部分,就是搜索系统,大模型的正确、稳定、可控生成,离不开精准可靠的搜索系统,大量的实验中都有发现,在搜索系统足够准确的前提下,大模型的犯错情况会骤然下降,因此,更全面、系统地了解搜索系统将很重要。
听读者建议,像之前的对话系统一样(前沿重器[21-25] | 合集:两万字聊对话系统),我也会拆开揉碎地给大家讲解搜索系统目前业界比较常用的架构、技术方案,目前的计划是分为这几个模块讲解:
开篇语(前沿重器[48] | 聊聊搜索系统1:开篇语):给大家简单介绍一下搜索系统的概况,以及现在大家比较关注在大模型领域的发展情况。
搜索系统的常见架构(前沿重器[49] | 聊聊搜索系统2:常见架构):经过多代人的探索,目前探索出相对成熟可靠,适配多个场景、人力、生产迭代等因素的综合性方案。
文档内容处理(前沿重器[50] | 聊聊搜索系统3:文档内容处理):对原始文档内容、知识的多种处理方案。
Query理解(前沿重器[51] | 聊聊搜索系统4:query理解):对query内容进行解析,方便后续检索使用。
召回:检索、粗排、多路召回(前沿重器[52] | 聊聊搜索系统5:召回:检索、粗排、多路召回):使用query理解的结果,从海量数据中找到所需的信息。
精排(前沿重器[53] | 聊聊搜索系统6:精排):对检索的内容进行进一步的精筛,提升返回的准确性。
其他搜索的附加模块(本期):补充说明一些和搜索有关的模块。
本期的内容是搜索的其他附加模块,重点讲几个和搜索有关的场景以及常见的解决方案。这篇文章比较轻松,都是一些概念和思路解释,只是补充说明一些可能会被忽略的内容。
搜索引导。
搜索广告。
大模型。
搜索引导
搜索引导在很早之前我有讲过:前沿重器[12] | 美团搜索引导技术启示,这个内容比较完整的讲解,可以参考《美团机器学习实践》的8.3。
搜索引导是指在用户搜索过程中给用户提供引导的统称,具体可以分为3种,搜索前、搜索中、搜索后引导,3个的内部所用的技术因为信息不同所以具体的技术方案会有所不同。这个“引导”,简单的理解,就是给用户进行query推荐。
搜索前,往往是根据用户的画像以及目前的新热内容进行推荐,常见的在搜索框下“猜你喜欢”、或者是预填在搜索框内的内容。
搜索中,指搜索过程中,用户输入一半时,下方出现的推荐内容,主要是根据用户已经输入的内容进行预想。
搜索后,指用户点击确定后,还给他推荐的一些相关的query。
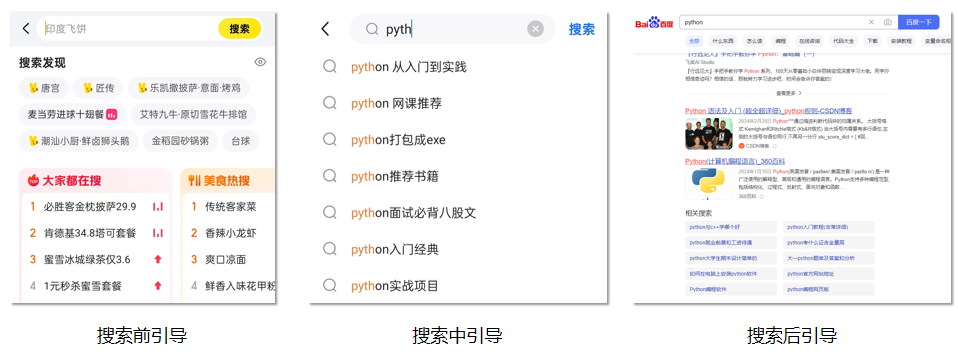
下面展开聊一聊这3个内容的具体场景细节和常见技术,只是简单聊不会展开。
搜索前
搜索前引导是没什么先验信息的,因此更多是推荐性质的,再者搜索界面往往比较空,里面会放很多东西。主要思路如下:
新、热信息,推荐常态了。
根据用户画像进行推荐,就当做推荐系统来做。
用户搜索历史。
搜索中
搜索过程中,用户已经输入了部分内容,此时的用户注意力基本聚焦在自己想输入的query上,所以这个时候没必要做太多复杂多样的工作,给出比较贴合目前用户输入内容的提示会比较好,主要思路如下:
用前缀树等方式,基于前缀召回一些高度相关、高质量、高点击的内容。
可以适当进行个性化。
但是请注意,此处的时延要求很高,必须尽快出,卡顿的时间内用户可能已经输入很多内容,尤其是pc端web段。
搜索后
搜索后,又回到了类似搜索前的状态,但与之不同的是此时用户已经有用户query,所以可以结合用户query做一些额外的尝试:
给出一些和用户query相似的句子,但检索出来的内容质量比较高(例如高有点率,即别的用户有点击的概率)。
搜了这些query的用户还搜了XX,用这个思路来找回,类似协同过滤了。
这个搜索引导的任务会挺适合做一种训练,就是根据问题思考问题特点并提出特定技术方案的训练,整个产品快速理解产品需求、用户习惯等,这些分析和探索的思维模式,非常值得吸收,大家也可以循着我的思路再过一遍。
搜索广告
广告是现在互联网非常常见的模式,搜索广告应该也不少见。

搜索广告目前需要考虑的内容:
搜索广告和推荐广告,跟搜索和推荐的类似,搜索广告是需要结合用户query的,给出的内容大概率要和query比较相关。这个是核心点。
相比搜索和推荐,广告本质是3方的权衡,用户、平台和广告方,而当考虑广告方收益后,用户的利益大概率要被一定程度牺牲。
广告商要求精准投放,对特定用户投放才会有效,用户视角对相关的内容反感度也不会很高,因此在匹配度和精准度上,各方的目标还是相对一致的。
因此,在权衡全局利益下,搜索广告的整体思路如下:
搜索广告考虑一定程度query相似度,否则投放质量和用户体验都会下降明显,所以query理解的相关工作仍旧需要做。
广告物料肯定远不如用户生成或者已有文档的数量多,所以搜索广告在召回层的要求需要一定程度下降。
精排和重排层,结合广告投放价值等进行综合排序。
大模型
大模型时代来临,大模型想必是大家关心的重点,所以我也单独拿出来说说自己的理解。大模型能助力搜索系统进行进一步提升,同时对于新的搜索系统,也很大程度降低早期启动时间。下面我分几个情况来讨论大模型在搜索中的应用情况。
离线文档处理:大模型的核心优势是few-shot甚至zero-shot的高baseline能力,在文档处理内,需要对文档内进行特定的关键词、实体、摘要进行抽取,大模型是一个非常快速的方案。
query理解:用大模型来做分类、实体抽取之类的任务已经是不是一个困难的事了,至少能省去很多标注的成本,或者是通过大模型来做粗标,无论如何从这个角度来讲,算是一个启动捷径。另外,大模型来做query拓展,收益也不低(前沿重器[38] | 微软新文query2doc:用大模型做query检索拓展)。
召回:召回层一般是直接做检索,在相似度上大模型的工作还需要探究,当然借助大模型做向量化的工作也不是没有,不过类似BGE-M3之类的操作,可能收益会比较高,直接用大模型的收益不如转为用大模型做拓展然后向量化。
精排:大模型做精排在早期还是可以尝试的,不过到了后期,还是不如特征之类比较成熟的方式,特征的有机组合和迭代节奏上有优势,且上限也不低。大模型在多特征多信息的环境下还是有些难度,可能会吃不下或者理解不了。
总的来说,大模型在这里的应用有如下特点:
有比较高的baseline,在数据匮乏,无法训练自有模型的时候,可以考虑大模型启动。
但是到了后期,很多问题可以用小模型替代,效果和性能可能还能提升,成本下降。
这里再补充一个点,可能会有人问到RAG,这里可以看出,大模型和搜索系统是相辅相成互相帮助的关系了,大模型用在搜索系统里能对搜索系统产生正面作用,而反过来,搜索系统在RAG中能快速查出对大模型有用的信息。
小结
本文主要对系列内没提到但比较重要的部分进行补充说明,主要讲的是搜索引导、搜索广告、大模型相关部分。
















 871
871











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









