







前言
Hi大家好,我叫延捷,是一名计算机视觉算法工程师,也是叉烧的老朋友了。我们计划发布一系列关于多模态大模型的文章,帮助大家快速、精准地了解多模态大模型的前世今生,并且深入各个多模态大模型领域优秀的工作,希望能给大家一个脉络性的盘点,一起学习,共同进步。
Introduction
上一期我们介绍了在多模态大模型领域相当火热Gemini系列,分享了Google在多模态大模型领域的一些经典工作,并且也会介绍笔者非常喜欢的一个工作Mini-Gemini。本期则会详细给大家介绍“小而美”的MiniCPM-V工作。同样地我并不会过多列举一些不必要的论文细节和指标,而是会着重讲述:
“心路历程”:一个系列工作逐步发展的路径,作者是如何根据当前工作的缺点一步步优化的,并且会总结出每篇工作的highlight,在精而不在多;
“数据细节”:各个工作中对数据处理的细节,包括但不限于数据的收集,采样时的分布,如何清洗/重建noisy数据,如何进行数据预处理,视频抽样的方案等,这些对算法工程师来说是同样重要的一环;
“前人肩膀”:各个工作中隐藏着一些非常值得盘的消融实验,站在前人的肩膀上,使用这些已有的消融实验结论,不仅能帮助我们更好地理解论文,更能在实际工作中少做些不必要的实验and少走弯路。
同样相信大家会从本文中收获不少。
MiniCPM-V
《MiniCPM-V: A GPT-4V Level MLLM on Your Phone》(2024)
MiniCPM-V其实也是一个多模态大模型的系列,跟LLaVA、Qwen-VL等不同,MiniCPM-V系列的设计哲学是在性能和效率之间实现良好的平衡,主打的方向是少参数、推理快速、可端侧运行,旨在用更少的参数达到那些大参数模型的效果。由于本篇论文的主角是MiniCPM-Llama3-V 2.5(为方便下面笔者就简称为MiniCPM-V 2.5),并且MiniCPM-V的其他系列也没有释放paper,这里我们就从MiniCPM-V 2.5入手,介绍当今2B和8B模型领域的强力好手。
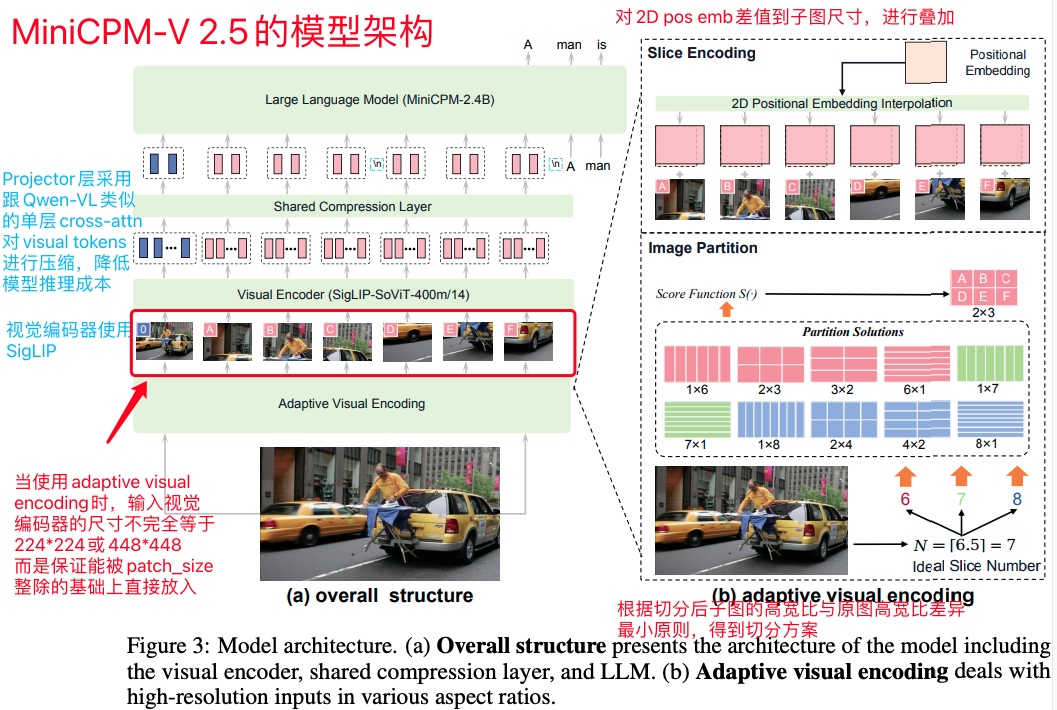
MiniCPM-V 2.5的核心依然是使用了当下最流行、最有效的Visual Encoder + Projector + LLM的经典架构。笔者认为MiniCPM-V 2.5的核心亮点有三:一是在图像输入处理端,AnyRes技术的基础上,参考LLaVA-UHD的工作,精细化地使用了自适应视觉编码(Adaptive Visual Encoding),使得输入图像的切分子图能与视觉编码器的预训练尺寸更好地适配,并且尽可能地减少resize对原始图像高宽比的改变,降低因为图像扭曲导致的失真,保持整个图像信息分布的一致性;二是在tokenizer端,使用Spatial Schema把各个子图像的img tokens进行包装和区分;三是在训练端,在pre-traning中也采用了分阶段的训练策略,递进式地进行预训练。下面我们就来详细介绍MiniCPM-V 2.5这个工作。
模型结构方面,Visual Encoder采用了SigLIP,Projector采用了跟Qwen-VL系列一样的单层cross-attention结构,基于固定数量的img queries来压缩视觉编码器得到的visual tokens,LLM则使用了经典的LLaMA-3
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









