






前沿重器
栏目主要给大家分享各种大厂、顶会的论文和分享,从中抽取关键精华的部分和大家分享,和大家一起把握前沿技术。具体介绍:仓颉专项:飞机大炮我都会,利器心法我还有。(算起来,专项启动已经是20年的事了!)
2024年文章合集最新发布!在这里:再添近20万字-CS的陋室2024年文章合集更新
往期回顾
阿里妈妈最近的一篇论文,在大模型这个背景下,提出一种基于大语言模型(LLMs)的通用推荐模型(URM),旨在通过统一的输入-输出框架处理多种推荐任务,避免传统推荐系统中针对不同任务设计专用模型的复杂性。
论文:Large Language Models Are Universal Recommendation Learners
链接:https://arxiv.org/abs/2502.03041
论文解读:https://mp.weixin.qq.com/s/rdzMvu-CZ7PzIwui79pD7w(阿里妈妈官方)
论文解读:https://zhuanlan.zhihu.com/p/23489001158
目录:
introduction&相关工作
introduction
相关工作
核心方案
数据
模型
训练
实验
个人总结
introduction&相关工作
这块我自己感觉作者根据论文提出的一些研究观点还挺有意义的,所以我在这里展开聊聊。
introduction
作者认为传统推荐系统会存在如下问题,这也是作者研究的出发点。
推荐系统下的任务非常复杂多变,依赖多目标来适配。为了精准捕捉用户意图,设计了点击预测、购买预测等任务,另外还要考虑多样性、创新性、冷启动等多方面问题,再者还有一些时间变化、突发事件的建模,例如季节性、节日、购物节、某些热点时间后的行为等。
推荐系统目前的方案,主要通过数据、任务设计的模式来准备模型,此时在比较狭窄的任务域或者是时间片上是生效的,但是任务一旦有变可能就需要重新训练了,且调整起来比较复杂,还会有数据之类的额外问题要面对。
传统多任务虽然是一个不错的思路,然而不同任务放在一个训练下,很容易顾此失彼,存在负迁移(negative transfer)。(而且我自己实践下来发现,多任务后,随着任务增加,操作难度是逐渐上升的)
上述问题的核心基本都在于传统方案在多任务多场景下的泛用性,而大模型这个模式则在这方面具有得天独厚的优点,即灵活的指令控制能力,因此他在多任务场景下能更好地控制整体效果。除此以外,还有一个小的补充,为了应对多种推荐场景,多模态的表征也被引入到这个大模型里。
相关工作
相关工作这块作者主要聊了两个方面,多任务和推荐系统LLM。
多任务的研究焦点主要在提升信息共享、缓解任务冲突,此时研究者在任务架构上就投入了大量精力,主要是参数共享和一些优化策略,但是随着任务的逐渐增加,多任务的问题仍旧是存在的,甚至多任务有些时候还有些兼容性问题。这里特别提出一个有意思的问题,就是搜索和推荐的差异,搜索是有明确的查询需求的,但是推荐没有,这两个任务之间的差异很明显,本就难以兼容。
而LLM用在推荐,这几年屡见不鲜,激进地直接生成无论是对用户行为还是物料ID的表征,都存在巨大挑战,而且还有多模态信息的注入,简单的ID表征并不能很好地描述物料本身的特性。因此本文重在介绍的,是将ID和文本嵌入都集成到LLM里面去,平衡性能和多功能性。
核心方案
文章和官方讲解文章里都有挺多细节的,我梳理着一个一个来。论文的分节还是挺标准的,就是大家对一个模型理解的几个模块,即数据、模型、训练。
数据
大模型训练,作者给出了非常直观的示例方便大家理解,这里我直接给出例子:
推荐任务类型 | 提示模板 |
|---|---|
多场景推荐 | 用户最近点击的项目如下:{用户行为序列}。在场景 {场景} 中,请推荐项目。 |
多目标推荐 | 用户最近点击的项目如下:{用户行为序列}。请推荐用户会 {行为} 的项目。 |
长尾项目推荐 | 用户最近点击的项目如下:{用户行为序列}。请推荐长尾项目。 |
意外性推荐 | 用户最近点击的项目如下:{用户行为序列}。请推荐一些新的项目类别。 |
长期推荐 | 用户最近点击的项目如下:{用户行为序列}。请推荐符合用户长期兴趣的项目。 |
搜索问题 | 用户最近点击的项目如下:{用户行为序列}。请推荐与 {查询} 匹配的项目。 |
可以看出,非常简单粗暴地,作者通过不同的语言来定义出不同任务,然后便可进行训练。值得注意的是,这里的“用户行为序列”,说的是具体行为的ID,例如这样子。
输入:用户最近点击的项目如下:[7502][8308][8274][8380]。请推荐与服装相关的项目。
而对应的,他们的输出就应该是这个格式。
目标文本:夏季的泳装和沙滩装;适合各种场合的休闲连衣裙。 目标项目:[3632][1334]
这个格式还是挺巧妙的,避免了模型对ID直接理解的困难,因为有文本来辅助对齐,训练的时候模型不需要重新理解这个ID。
模型
直接上图,整个模型架构是这样的。
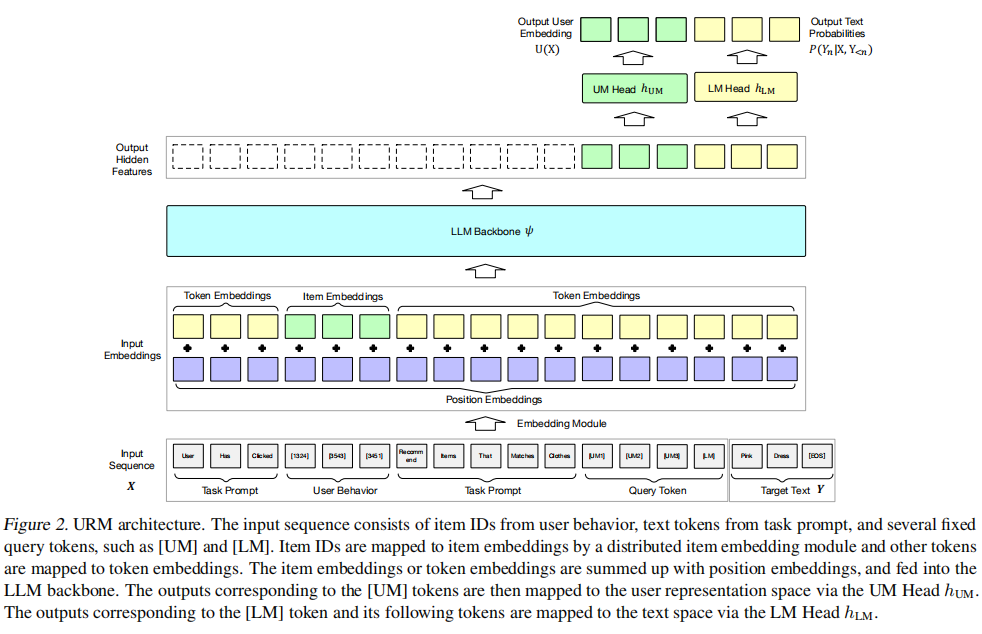
此处作者把输入分成好几个模块,每个模块在进入大模型之前,都会各自根据位置的嵌入进行求和,在经过大模型训练后,生成几个隐藏特征,用于计算最终输出,可以看到,此处对模型的修改并不算大,就只有输入和输出,这样有利于最大限度保证大模型内部的知识。
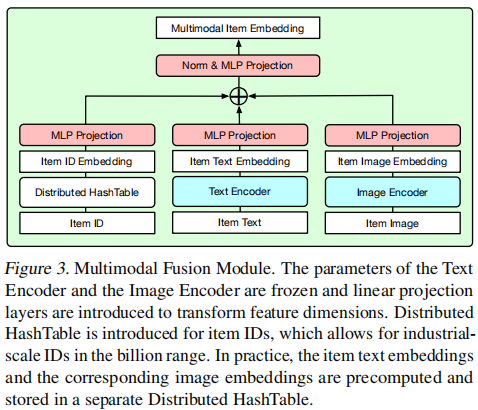
有关物料的嵌入,比较常见的方案一个是直接训练一个模型做映射,把ID和文本空间对齐,另一个是将物料信息输入到一个大模型里生成文本后进行表征,前者两者的对齐本就困难,后者则难以体现物料的差异化。本文专门设计一个多模态融合模块,可以用于融合不同类型的项目信息,ID有分布式的ID哈希表,文本有文本编码器,图片有图片编码器,经过SFT后,多模态项目融合嵌入可以有效地与文本语义空间对齐,同时保留每个项目的特定信息,在文本嵌入的泛化性和 ID 嵌入的区分性之间取得了良好的平衡。
说完物料便要说序列的融合,用户的行为实质上是物料序列组成的。在文本生成的过程,一般的自回归模式很容易产生物料库内没有的内容,而且自回归的推理成本和时间也比较高,因此文中直接生成目标文本和目标物料两者,而且考虑到文本和物料两者的空间存在冲突,所以此处采用特殊的标签"[UM]"和"[LM]"来区分,有两个关键的输出头,一个是用户建模的输出头,将最终结果转为用户的嵌入,一个是语言头,允许模型进行文本生成的训练。
对UM和LM的标记,大家可以看这个例子。
输入:用户最近点击的项目如下:[7502][8308][8274][8380]。请推荐与服装相关的项目。[UM][LM]
此处,用户的Embedding,即上面模型架构图中的U(X)和物料的嵌入之间是可以进行相似度计算的,便可以进行向量召回。而在进一步,为了应对不同的场景,增加UM的个数是可以的,更进一步,更多的UM也意味着能表达更多维度的信息,可能更有利于最终的预测准确性,毕竟多个UM是经过全局注意力的,经过前向传播后就能吸收着多个方面的信息。
训练
训练的话还是比较好理解的,就是多目标任务,对于给定输入X,有两个输出,文本结果Y和物料Z,计算损失的时候,便是X和Y用负对数似然做优化,而X和Z则用NCE(Noise Contrastive Estimation)损失来做,对这两个目标,用一个系数来控制重要性。
实验
实验整体内容也比较常规,在线下通用测试集和工业界结果都有提升。值得留意的是消融实验和各种补充实验。
尽管多任务会让效果下降,似乎能充分体现多任务数据之间的协助,随着任务增加,实验任务的效果还有提升。这个挺反直觉的,一般的多任务反而会牵制多个任务的效果提升。
ID嵌入+文本嵌入的混合嵌入模式,对最终的效果是有收益的,纯文本的效果确实不好,ID嵌入次之,两者结合能有1+1>2的效果。
LM Loss,也就是文本输出那块的损失,不加入,以及UM、LM标记单独的损失未加入时,均会导致效果下降,尤其是后者。
提示工程对最终效果存在较高敏感性。使用特定场景的提示模板时,能获得更高的效果,如多样性、长尾、长期兴趣等。
在零样本、小样本的任务迁移上,效果提升还是比较明显的,这得益于大模型本身的世界知识,类似“圣诞节”或“冬季取暖”之类的说法,模型能轻松识别出来。
在一个隐秘的角落,B.2的附录里面看,Qwen-7b和Qwen-1.8B的效果差距并不是很大,大家感受一下0.403->0.392,这个1.8B是个性价比之选了。
在附录里,作者给了很多实验结果,包括一些多模态的结果,从show case来看质量还是不错的。
个人总结
论文看完了,我总会逼着自己总结一些自己感受比较深的内容,以便把论文真正消化吸收。
文本+ID的输出模式,既能让tokenID被充分理解,也能加入文本对齐,把物料信息加入。很多时候我们做分类,通常会把类目本身的含义信息给忽略,此处便充分体现了类目信息的效用。
多模态信息注入。多模态的注入模式,现在来看还是非常朴实无华,经过表征后和其他模态信息融合便能形成,还是比较简单粗暴的。
大模型确实是支持多任务模式,为多任务这个议题注入了新的活力,一般我们日常做分类、实体抽取、摘要、翻译之类的任务也是通过prompt能快速出baseline,因此有理由相信现在的大模型确实有很强的多任务能力。
大模型的“世界知识”让他能很大程度做任务迁移,这里令我惊喜的是,论文里做的微调是全量的SFT,本应该被学偏的内容,在后续的迁移实验里仍旧有比较好的效果,说明模型的学偏程度应该比想象中要低,当然也可能和仍旧保留的LM Loss之类的任务有关了。(说不定,这种对比学习,起到了和冻结参数类似LoRA方面的效果)。
比较惊喜的是,在1.8B这个大小下能很大程度逼近7B的效果。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









