









准备
1.下载crf++-0.58
2.训练数据train.txt
3.template 文件
4.测试数据test.txt
本文之讲述简单的操作步骤,
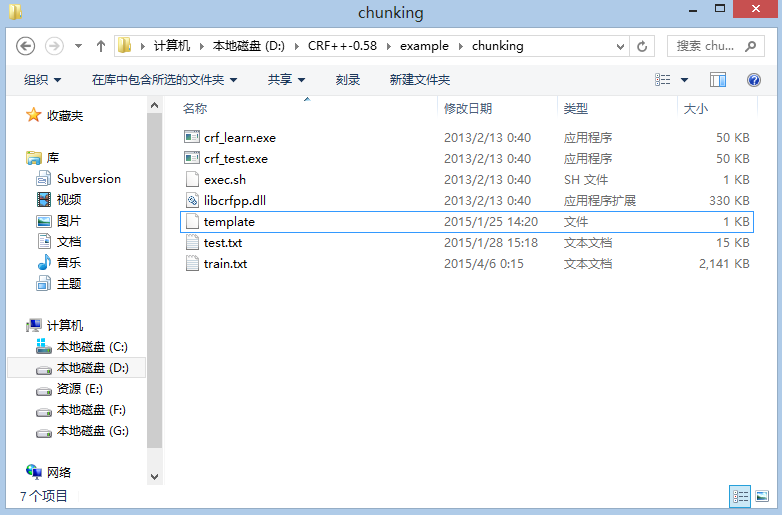
train.txt文件数据格式:
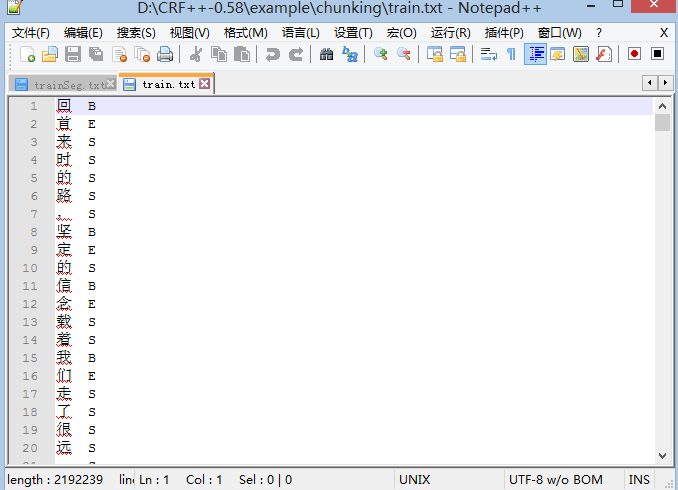
template文件
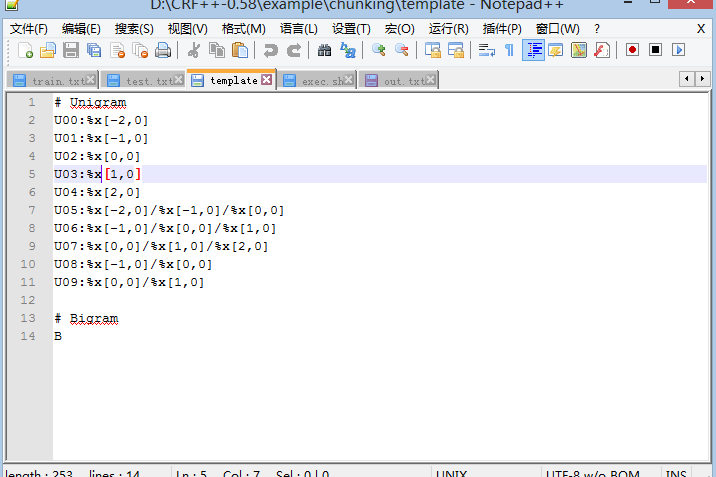
test.txt 文件数据格式
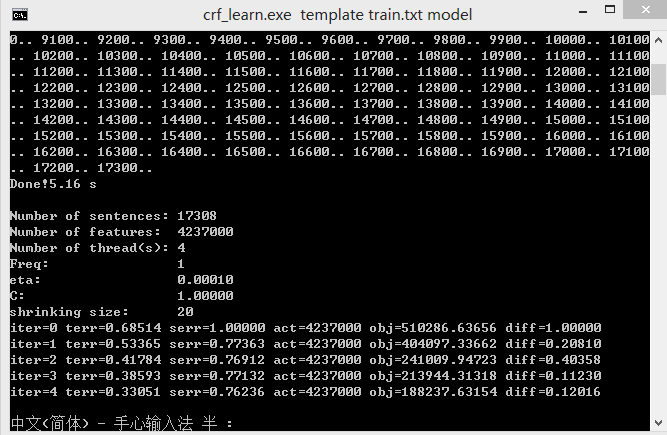
训练命令:
crf_learn template train.txt model
命令执行完成会在工作目录生成model文件,
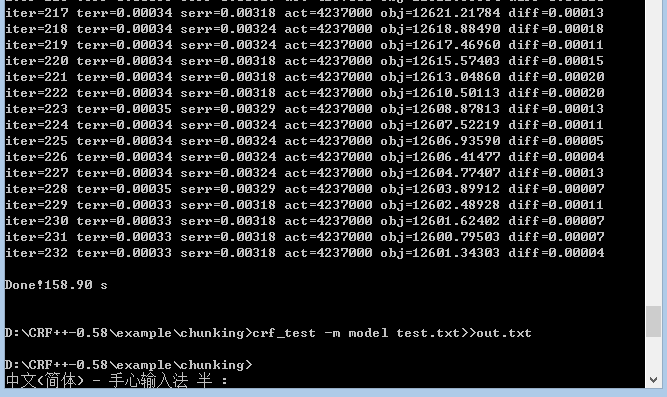
测试命令:
crf_test -m model test.data>>out.txt
命令执行完成会在工作目录生成out.txt, 内容为预测结果
测试结果:out.txt

训练参数:
例如:
crf_learn -a CRF-L1 -thread 10 template train.txt model
可选参数
-f, –freq=INT 使用属性的出现次数不少于INT(默认为1)
-m, –maxiter=INT 设置INT为LBFGS的最大跌代次数 (默认10k)
-c, –cost=FLOAT 设置FLOAT为代价参数,过大会过度拟合 (默认1.0)
-e, –eta=FLOAT 设置终止标准FLOAT(默认0.0001)
-C, –convert 将文本模式转为二进制模式
-t, –textmodel 为调试建立文本模型文件
-a, –algorithm=(CRF|MIRA)
选择训练算法, 默认为CRF-L2
-p, –thread=INT 线程数(默认1),利用多个CPU减少训练时间
-H, –shrinking-size=INT
设置INT为最适宜的跌代变量次数 (默认20)
-v, –version 显示版本号并退出
-h, –help 显示帮助并退出
几个很好的链接:crf分词解码过程理解
http://www.52nlp.cn/%E5%88%9D%E5%AD%A6%E8%80%85%E6%8A%A5%E9%81%933-crf-%E4%B8%AD%E6%96%87%E5%88%86%E8%AF%8D%E8%A7%A3%E7%A0%81%E8%BF%87%E7%A8%8B%E7%90%86%E8%A7%A3
crf模型格式说明
http://www.hankcs.com/nlp/the-crf-model-format-description.html
CRF分词的纯Java实现
http://www.hankcs.com/nlp/segment/crf-segmentation-of-the-pure-java-implementation.html

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









