







处理缺失值的意义
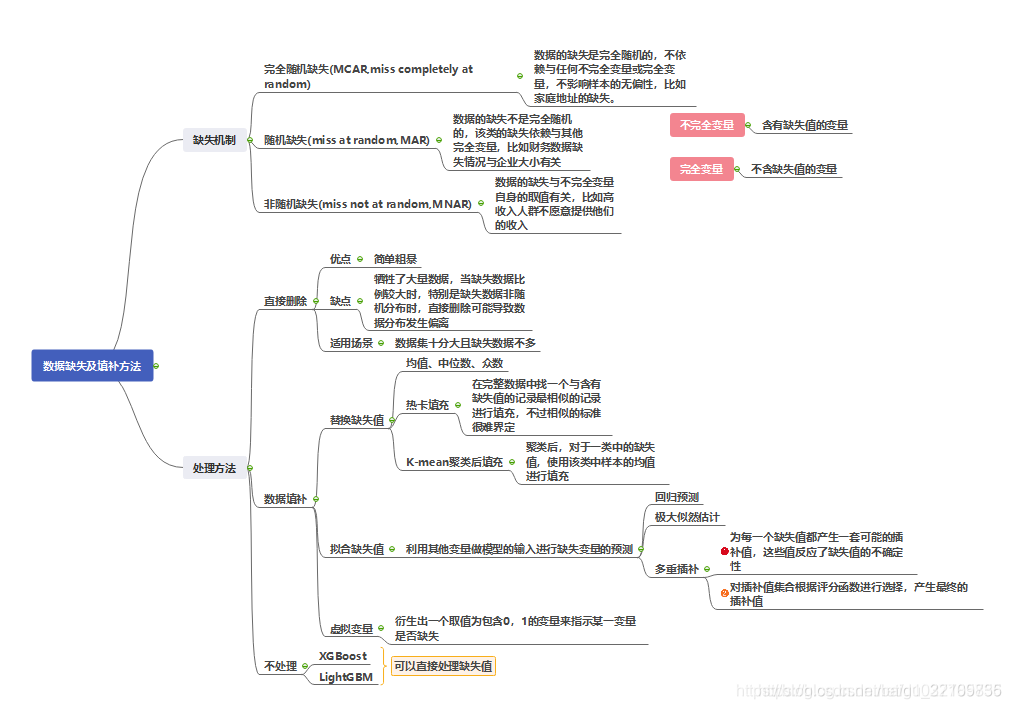
没有高质量的数据,就没有高质量的数据挖掘结果,数据值缺失是数据分析中经常遇到的问题之一。当缺失比例很小时,可直接对缺失记录进行舍弃或进行手工处理。但在实际数据中,往往缺失数据占有相当的比重。这时如果手工处理非常低效,如果舍弃缺失记录,则会丢失大量信息,使不完全观测数据与完全观测数据间产生系统差异,对这样的数据进行分析,你很可能会得出错误的结论。
为什么要进行空值处理?
- 系统丢失了大量的有用信息;
- 系统的不确定性更加显著,系统中的确定性成分更难把握;
- 包含空值的数据会使挖掘过程陷入混乱,导致不可靠的输出。
造成缺失值的原因
-
信息暂时无法获取。如商品售后评价、双十一的退货商品数量和价格等具有滞后效应。
-
信息被遗漏。可能是因为输入时认为不重要、忘记填写了或对数据理解错误而遗漏,也可能是由于数据采集设备的故障、存储介质的故障、传输媒体的故障、一些人为因素等原因而丢失。这个在很多公司恐怕是习以为常的事情。
-
获取这些信息的代价太大。如统计某校所有学生每个月的生活费,家庭实际收入等等。
-
系统实时性能要求较高。即要求得到这些信息前迅速做出判断或决策。
-
有些对象的某个或某些属性是不可用的。如一个未婚者的配偶姓名、一个儿童的固定收入状况等。
对缺失值的处理要具体问题具体分析,为什么要具体问题具体分析呢?因为属性缺失有时并不意味着数据缺失,缺失本身是包含信息的,所以需要根据不同应用场景下缺失值可能包含的信息进行合理填充。
“年收入”:商品推荐场景下填充平均值,借贷额度场景下填充最小值;
“行为时间点”:填充众数;
“价格”:商品推荐场景下填充最小值,商品匹配场景下填充平均值;
“人体寿命”:保险费用估计场景下填充最大值,人口估计场景下填充平均值;
“驾龄”:没有填写这一项的用户可能是没有车,为它填充为0较为合理;
”本科毕业时间”:没有填写这一项的用户可能是没有上大学,为它填充正无穷比较合理;
“婚姻状态”:没有填写这一项的用户可能对自己的隐私比较敏感,应单独设为一个分类,如已婚1、未婚0、未填-1。
空值处理的方法:
一、删除元组
将存在遗漏信息属性值的对象(记录)删除,从而得到一个完备的信息表。这种方法在对象有多个属性缺失值、被删除的含缺失值的对象与信息表中的数据量相比非常小的情况下是非常有效的。然而这种方法丢弃了大量隐藏在这些对象中的信息。在信息表中对象很少的情况下会影响到结果的正确性,可能导致数据发生偏离,从而引出错误的结论。
【总结】1. 删除数据的处理方法只适用于小部分数据存在缺失的情况;2. 若测练集中也存在缺失值,则不便删除。
二、数据补齐
这类方法是基于统计学原理用一定的值去填充空值,从而使信息表完备化。数据挖掘中常用的有以下几种补齐方法:
-
人工填写 (不推荐)
这个方法产生数据偏离最小,是填充效果最好的一种。当数据规模很大、空值很多的时候,该方法是不可行的。 -
特殊值填充 (类别属性缺失常用)
将空值作为一种特殊的属性值来处理,它不同于其他的任何属性值。如所有的空值都用“unknown”填充。一般例如类别属性缺失较多,则可令缺失部分单独作为一类,例如年龄、性别。 -
平均值、众数、上下文填充等统计数值填充 (连续属性-平均数\离散属性-众数,处理比较粗糙)
如果空值是数值属性,就使用该属性在其他所有对象的取值的平均值来填充该缺失的属性值.
如果空值是非数值属性,就根据统计学中的众数原理,用该属性在其他所有对象出现频率最高的值来补齐该缺失的属性值。 -
使用所有可能的值填充 (不了解)
这种方法是用空缺属性值的所有可能的属性取值来填充,能够得到较好的补齐效果。但是当数据量很大或者遗漏的属性值较多时,其计算的代价很大,可能的测试方案很多。 -
K最近邻法
先根据欧式距离或相关分析来确定距离具有缺失数据样本最近的K个样本,将这K个值加权平均来估计该样本的缺失数据。 -
期望值最大化方法(EM)
在缺失类型为随机缺失的条件下,假设模型对于完整的样本是正确的,通过观测数据的边际分布可以对未知参数进行极大似然估计。它一个重要前提:适用于大样本。有效样本的数量足够以保证ML估计值是渐近无偏的并服从正态分布。但是这种方法可能会陷入局部极值,收敛速度也不是很快,并且计算很复杂。 -
插补法 - 热卡填充-就近补齐思想
对于一个包含空值的对象,热卡填充法在完整数据中找到一个与它最相似的对象,然后用这个相似对象的值来进行填充。不同的问题选用不同的标准来对相似进行判定。最常见的是使用相关系数矩阵来确定哪个变量(如变量Y)与缺失值所在变量(如变量X)最相关。然后把所有变量按Y的取值大小进行排序。那么变量X的缺失值就可以用排在缺失值前的那个变量Y的数据来代替了。优点:概念上很简单,且与均值替换法相比,利用热卡填充法插补数据后,其变量的标准差与插补前比较接近。
缺点:操作太麻烦,比较耗时,而且在回归方程中,使用热卡填充法容易使得回归方程的误差增大,参数估计变得不稳定。 -
插补法 - 用模型预测
基于完整的数据集,建立回归方程(模型)。对于包含空值的对象,将已知属性值代入方程来估计未知属性值,以此估计值来进行填充。 -
插补法 - 多重插补(MICE)
多重插补(MI)是一种基于重复模拟的处理缺失值的方法,它从一个包含缺失值的数据集中生成一组数据完整的数据集(即不包含缺失值的数据集,通常是3-10个)。每个完整数据集都是通过对原始数据中的缺失数据进行插补而生成的。在每个完整的数据集上引用标准的统计方法,最后,把这些单独的分析结果整合为一组结果。
miceforest:使用Python中的随机森林进行快速插补: https://blog.csdn.net/upluck/article/details/111868990 -
插补法 - 其他插值法
插值不同于拟合。插值函数经过样本点,拟合函数一般基于最小二乘法尽量靠近所有样本点穿过。常见插值方法有拉格朗日插值法、分段插值法、样条插值法。
- 拉格朗日插值多项式:当节点数n较大时,拉格朗日插值多项式的次数较高,可能出现不一致的收敛情况,而且计算复杂。随着样点增加,高次插值会带来误差的震动现象称为龙格现象。
- 分段插值:虽然收敛,但光滑性较差。
- 样条插值:样条插值是使用一种名为样条的特殊分段多项式进行插值的形式。由于样条插值可以使用低阶多项式样条实现较小的插值误差,这样就避免了使用高阶多项式所出现的龙格现象,所以样条插值得到了流行。
(数值分析)各种插值法的python实现:https://blog.csdn.net/qq_20011607/article/details/81412985
三、不处理
直接在包含空值的数据上进行数据挖掘。这类方法包括贝叶斯网络、人工神经网络、lgb、xgb等,在模型内部对空值进行处理,根据损失函数来确定。
3.1 xgb 如何处理缺失值
xgboost处理缺失值的方法和其他树模型不同。根据作者Tianqi Chen的介绍,xgboost把缺失值当做稀疏矩阵来对待,本身的在节点分裂时不考虑的缺失值的数值。缺失值数据会被分到左子树和右子树分别计算损失,选择较优的那一个。如果训练中没有数据缺失,预测时出现了数据缺失,那么默认被分类到右子树。
四、 什么样的模型对缺失值更敏感?
主流的机器学习模型千千万,很难一概而论。但有一些经验法则(rule of thumb)供参考:
- 树模型对于缺失值的敏感度较低,大部分时候可以在数据有缺失时使用。
- 涉及到距离度量(distance measurement)时,如计算两个点之间的距离,缺失数据就变得比较重要。因为涉及到“距离”这个概念,那么缺失值处理不当就会导致效果很差,如K近邻算法(KNN)和支持向量机(SVM)。
- 线性模型的代价函数(loss function)往往涉及到距离(distance)的计算,计算预测值和真实值之间的差别,这容易导致对缺失值敏感。
- 神经网络的鲁棒性强,对于缺失数据不是非常敏感,但一般没有那么多数据可供使用。
- 贝叶斯模型对于缺失数据也比较稳定,数据量很小的时候首推贝叶斯模型。
总结来看,对于有缺失值的数据缺失值处理:
-
数据量很小,用朴素贝叶斯
-
数据量适中或者较大,用树模型,优先 xgboost
-
数据量较大,也可以用神经网络
-
避免使用距离度量相关的模型,如KNN和SVM
参考:[1] https://blog.csdn.net/u011630575/article/details/81394704
参考:[2] https://www.cnblogs.com/ljhdo/p/5086619.html

















 716
716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









