







2.1条件熵
条件熵H ( Y ∣ X ) ,表示在已知随机变量X的条件下,随机变量Y的不确定性程度。
随机变量X给定的条件下,随机变量Y的条件熵H(Y|X)。
H
(
Y
∣
X
)
=
∑
x
∈
X
p
(
x
)
∗
H
(
Y
∣
X
=
x
)
H(Y∣X) = ∑_{x∈X}p(x)*H(Y∣X=x)
H(Y∣X)=x∈X∑p(x)∗H(Y∣X=x)
举个例子,有下面这么一组数据。
#分类属性
labels=[‘年龄’,‘有工作’,‘有自己的房子’,‘信贷情况’]
yearsOldLabel = {0: ‘青年’, 1: ‘中年’, 2: ‘老年’ }
jobLabel = {0: ‘无工作’, 1: ‘有工作’}
houseLabel = {0: ‘无房子’, 1: ‘有房子’}
creditLabel = {0: ‘一般’, 1: ‘好’, 2: ‘非常好’ }
loadLabel = {‘yes’: ‘批贷’, ‘no’: ‘拒贷’}
#数据集合
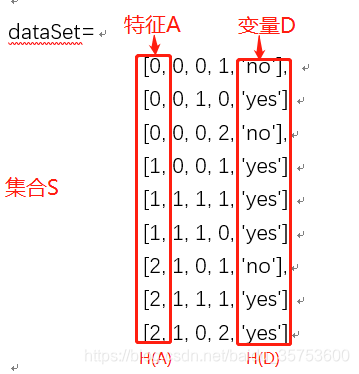
dataSet=[
[0, 0, 0, 1, ‘no’],
[0, 0, 1, 0, ‘yes’],
[0, 0, 0, 2, ‘no’],
[1, 0, 0, 1, ‘yes’],
[1, 1, 1, 1, ‘yes’],
[1, 1, 1, 0, ‘yes’],
[2, 1, 0, 1, ‘no’],
[2, 1, 1, 1, ‘yes’],
[2, 1, 0, 2, ‘yes’]]
假如Y= loadLabel
X= yearsOldLabel
那么H(Y∣X)表示X(年龄列)已知的条件下,变量Y(是否批贷)的熵。
H(Y∣X)
= p(X=0)*H(Y| X=0) + p(X=1)*H(Y| X=1) + p(X=2)*H(Y| X=2)
= 3/9 * (-2/3 * log
2
_2
2(2/3) -1/3 * log
2
_2
2(1/3)) + 3/9 * (-1 * log
2
_2
2 1) + 3/9 * (-1/3 * log
2
_2
2(1/3) -2/3 * log
2
_2
2(2/3))
= 0.612
2.2信息增益
信息增益的计算公式如下所示。
g(D,A)=H(D)−H(D|A)
说明:以求解变量D为目的的数据集合S,特征A是数据集合中的其中一个特征。在特征A给定的条件下,目标变量D的条件熵记为H(D|A)。
比如上面例子中,D就是loadLabel = {‘yes’: ‘批贷’, ‘no’: ‘拒贷’},特征A可以是yearsOldLabel、jobLabel、houseLabel或者creditLabel等的任何一个。
假如A=yearsOldLabel,那么上例中
g(D,A)= (-3/9 * log
2
_2
2(3/9) - 6/9 * log
2
_2
2(6/9)) - 0.612 = 0.918 - 0.612 = 0.306
2.3信息增益比
信息增益比的计算公式如下所示。
g
R
_R
R(D,A) = g(D,A) / H(A)
H
(
A
)
=
−
∑
v
∈
A
(
n
u
m
(
S
v
)
/
(
n
u
m
(
S
)
)
l
o
g
2
(
n
u
m
(
S
v
)
/
(
n
u
m
(
S
)
)
H(A) = -∑_{v∈A} (num(S_v)/(num(S)) log_2(num(S_v)/(num(S))
H(A)=−v∈A∑(num(Sv)/(num(S))log2(num(Sv)/(num(S))
假如A=yearsOldLabel,那么上例中
g
R
_R
R(D,A) =0.306 / (3 * (-3/9 * log
2
_2
2(3/9))) = 0.193
H(D) 和 H (A) 的求解要区分开。














 2250
2250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









