









⼀. is和==的区别
1. id()
通过id()我们可以查看到⼀个变量表⽰的值在内存中的地址.
s = 'alex'
print(id(s)) # 4326667072
s = "alex"
print(id(s)) # 4326667072
lst = [1, 2, 4]
print(id(lst)) # 4326685768
lst1 = [1, 2, 4]
print(id(lst1)) # 4326684360
# 结果⼀致, 但是在终端中是不⼀致的. 所以在python中,命令⾏代码和py⽂ 件中的代码运⾏的效果可能是不⼀样的
s1 = "@1 2 "
s2 = "@1 2 "
print(id(s1)) print(id(s2))
⼩数据池(常量池): 把我们使⽤过的值存储在⼩数据池中.供其他的变量使⽤.
⼩数据池给数字和字符串使⽤, 其他数据类型不存在.
对于数字: -5~256是会被加到⼩数据池中的. 每次使⽤都是同⼀个对象.
对于字符串:
1. 如果是纯⽂字信息和下划线. 那么这个对象会被添加到⼩数据池
2. 如果是带有特殊字符的. 那么不会被添加到⼩数据池. 每次都是新的
3. 如果是单⼀字⺟*n的情况. 'a'*20, 在20个单位内是可以的. 超过20个单位就不会添加 到⼩数据池中
注意(⼀般情况下): 在py⽂件中. 如果你只是单纯的定义⼀个字符串. 那么⼀般情况下都是会 被添加到⼩数据池中的. 我们可以这样认为: 在使⽤字符串的时候, python会帮我们把字符串 进⾏缓存, 在下次使⽤的时候直接指向这个字符串即可. 可以节省很多内存.
这个问题千万不要纠结. 因为官⽅没有给出⼀个完美的结论和定论.所以只能是⾃⼰摸索.
注意. is比较的就是id()计算出来的结果. 由于id是帮我 们查看某数据(对象) 的内存地址. 那么is比较的就是数据(对象)的内存地址.
最终我们通过is可以查看两个变量使⽤的是否是同⼀个对象.
== 双等表⽰的是判断是否相等, 注意. 这个双等比较的是具体的值.⽽不是内存地址
s1 = "哈哈"
s2 = "哈哈"
print(s1 == s2) # True
print(s1 is s2) # True 原因是有⼩数据池的存在 导致两个变量指向的是同⼀个对象
l1 = [1, 2, 3]
l2 = [1, 2, 3]
print(l1 == l2) # True, 值是⼀样的
print(l1 is l2) # False, 值是假的
总结:
is 比较的是地址
== 比较的是值
二、编码解码的问题
编码的补充
1. python2中默认使⽤的是ASCII码. 所以不⽀持中⽂. 如果需要在Python2中更改编码.
需要在⽂件的开始编写:
# -*- encoding:utf-8 -*-
2. python3中: 内存中使⽤的是unicode码.
编码回顾:
1. ASCII : 最早的编码. ⾥⾯有英⽂⼤写字⺟, ⼩写字⺟, 数字, ⼀些特殊字符. 没有中⽂,
8个01代码, 8个bit, 1个byte2. GBK: 中⽂国标码, ⾥⾯包含了ASCII编码和中⽂常⽤编码. 16个bit, 2个byte
3. UNICODE: 万国码, ⾥⾯包含了全世界所有国家⽂字的编码. 32个bit, 4个byte, 包含了
ASCII
4. UTF-8: 可变⻓度的万国码. 是unicode的⼀种实现. 最⼩字符占8位
1.英⽂: 8bit 1byte
2.欧洲⽂字:16bit 2byte
3.中⽂:24bit 3byte
综上, 除了ASCII码以外, 其他信息不能直接转换.
在python3的内存中. 在程序运⾏阶段. 使⽤的是unicode编码. 因为unicode是万国码. 什么内
容都可以进⾏显⽰. 那么在数据传输和存储的时候由于unicode比较浪费空间和资源. 需要把
unicode转存成UTF-8或者GBK进⾏存储. 怎么转换呢. 在python中可以把⽂字信息进⾏编码.
编码之后的内容就可以进⾏传输了. 编码之后的数据是bytes类型的数据.其实啊. 还是原来的
数据只是经过编码之后表现形式发⽣了改变⽽已.
bytes的表现形式:
1. 英⽂ b'alex' 英⽂的表现形式和字符串没什么两样
2. 中⽂ b'\xe4\xb8\xad' 这是⼀个汉字的UTF-8的bytes表现形式
字符串在传输时转化成bytes=> encode(字符集)来完成
s = "alex"
print(s.encode("utf-8")) # 将字符串编码成UTF-8
print(s.encode("GBK")) # 将字符串编码成GBK
结果:
b'alex'
b'alex'
s = "中"
print(s.encode("UTF-8")) # 中⽂编码成UTF-8
print(s.encode("GBK")) # 中⽂编码成GBK
结果:
b'\xe4\xb8\xad'
b'\xd6\xd0'
记住: 英⽂编码之后的结果和源字符串⼀致. 中⽂编码之后的结果根据编码的不同. 编码结果
也不同. 我们能看到. ⼀个中⽂的UTF-8编码是3个字节. ⼀个GBK的中⽂编码是2个字节.
编码之后的类型就是bytes类型. 在⽹络传输和存储的时候我们python是保存和存储的bytes类型. 那么在对⽅接收的时候. 也是接收的bytes类型的数据. 我们可以使⽤decode()来进⾏解
码操作. 把bytes类型的数据还原回我们熟悉的字符串:
s = "我叫李嘉诚"
print(s.encode("utf-8")) #
b'\xe6\x88\x91\xe5\x8f\xab\xe6\x9d\x8e\xe5\x98\x89\xe8\xaf\x9a'
print(b'\xe6\x88\x91\xe5\x8f\xab\xe6\x9d\x8e\xe5\x98\x89\xe8\xaf\x9a'.decod
e("utf-8")) # 解码
编码和解码的时候都需要制定编码格式.
s = "我是⽂字"
bs = s.encode("GBK") # 我们这样可以获取到GBK的⽂字
# 把GBK转换成UTF-8
# ⾸先要把GBK转换成unicode. 也就是需要解码
s = bs.decode("GBK") # 解码
# 然后需要进⾏重新编码成UTF-8
bss = s.encode("UTF-8") # 重新编码
print(bss)
作业:
现有主播字典信息zhubo={"卢本纬":12200,"冯提莫":18999,"金老板":2500000},按要求完成一下的操作
1、计算主播的平均工资
sum=0
for value in zhubo.values():
sum=sum+value
avg=sum/len(zhubo)
print(avg)2、删掉收益小于平均值的主播
再循环体内删除是不允许的,结果操作报如下错
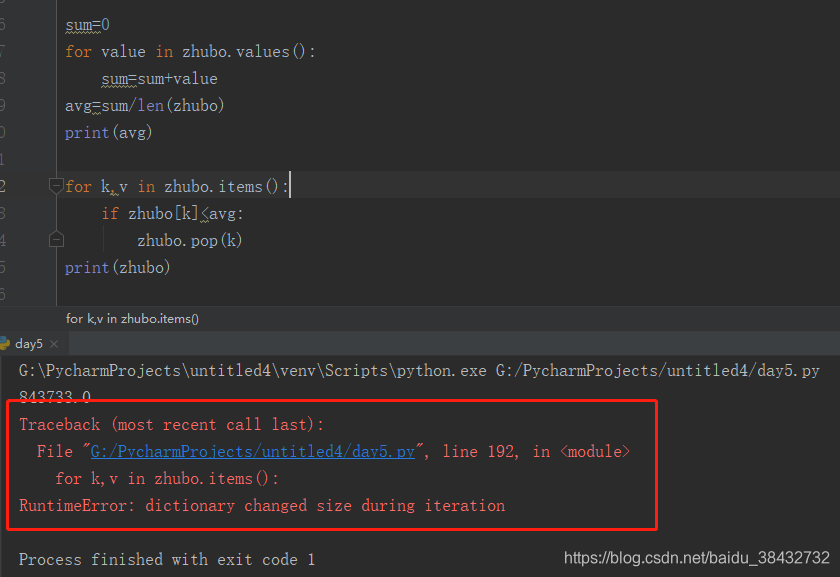
sum=0
for value in zhubo.values():
sum=sum+value
avg=sum/len(zhubo)
print(avg)
list=[]
for k,v in zhubo.items():
if zhubo[k]<avg:
list.append(k)
for i in list:
zhubo.pop(i)
print(zhubo)车牌号区域划分
cars=["鲁A32444","鲁812333","京88989M","黑C49678","黑46555","沪825041"]
locals={"沪":"上海","黑":"黑龙江","鲁":"山东","京":"北京"}
划分结果如下:{'上海': 1, '黑龙江': 2, '山东': 2, '北京': 1}
list=[]
dic={}
for i in cars:
list.append(i[0])
for k,v in locals.items():
if k not in list:
continue
else:
dic[v]=list.count(k)
print(dic)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











