









1. Numpy
首先将分别介绍 numpy 数组的简单创建、随机创建、遍历和运算,同时给出相应代码示例。首先确保你已经安装了 numpy 库,如果没有安装,可以使用 pip install numpy 进行安装。
import numpy as np
# 从 Python 列表创建数组
arr1 = np.array([1, 2, 3, 4, 5])
print("从列表创建的数组:", arr1)
# 使用 arange 函数创建数组,类似于 Python 的 range 函数
arr2 = np.arange(0, 10, 2) # 从 0 到 10,步长为 2
print("使用 arange 创建的数组:", arr2)
# 使用 linspace 函数创建数组,生成指定区间内的等间距数组
arr3 = np.linspace(0, 1, 5) # 在 0 到 1 之间生成 5 个等间距的数
print("使用 linspace 创建的数组:", arr3)

2. 随机创建 numpy 数组
numpy.random 模块提供了多种函数用于创建随机数组,像 np.random.rand() 、 np.random.randn() 、 np.random.randint() 等。
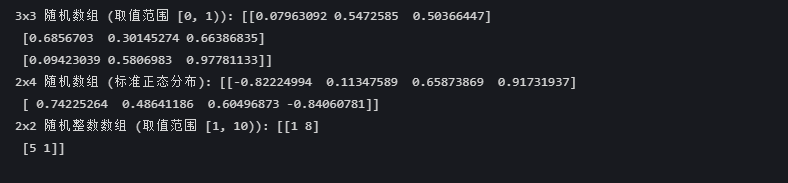
# 创建一个 3x3 的随机数组,元素取值范围在 [0, 1) 之间
random_arr1 = np.random.rand(3, 3)
print("3x3 随机数组 (取值范围 [0, 1)):", random_arr1)
# 创建一个 2x4 的随机数组,元素服从标准正态分布
random_arr2 = np.random.randn(2, 4)
print("2x4 随机数组 (标准正态分布):", random_arr2)
# 创建一个 2x2 的随机整数数组,元素取值范围在 [1, 10) 之间
random_arr3 = np.random.randint(1, 10, size=(2, 2))
print("2x2 随机整数数组 (取值范围 [1, 10)):", random_arr3)
3. 遍历 numpy 数组
可以使用嵌套的 for 循环来遍历多维数组,也能使用 np.nditer() 函数进行高效遍历。
arr = np.array([[1, 2, 3], [4, 5, 6]])
# 使用嵌套 for 循环遍历数组
print("使用嵌套 for 循环遍历:")
for row in arr:
for element in row:
print(element, end=' ')
print()
# 使用 np.nditer() 遍历数组
print("使用 np.nditer() 遍历:")
for element in np.nditer(arr):
print(element, end=' ')
print()

4. numpy 数组运算
numpy 数组支持多种运算,包括算术运算、矩阵运算等。
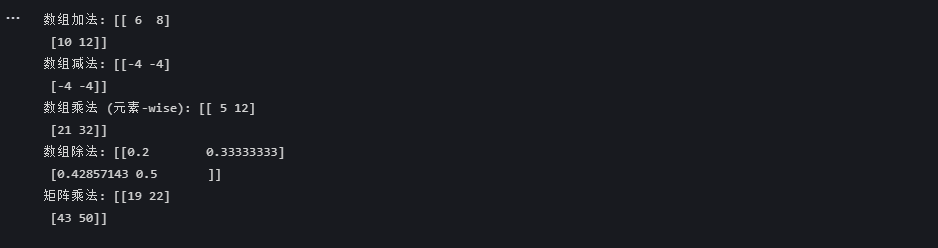
arr_a = np.array([[1, 2], [3, 4]])
arr_b = np.array([[5, 6], [7, 8]])
# 算术运算
print("数组加法:", arr_a + arr_b)
print("数组减法:", arr_a - arr_b)
print("数组乘法 (元素-wise):", arr_a * arr_b)
print("数组除法:", arr_a / arr_b)
# 矩阵乘法
print("矩阵乘法:", np.dot(arr_a, arr_b))
这些示例展示了 numpy 数组常见的创建、遍历和运算操作,你可以根据实际需求对代码进行调整。
numpy 数组支持多种索引方式,下面分别介绍一维、二维和三维 numpy 数组的索引方法。
一维数组索引
一维 numpy 数组的索引方式和 Python 列表类似,可以通过下标来访问元素,下标从 0 开始,也支持负数索引。
import numpy as np
# 创建一维数组
arr1d = np.array([10, 20, 30, 40, 50])
# 访问单个元素
print("第一个元素:", arr1d[0]) # 输出第一个元素
print("最后一个元素:", arr1d[-1]) # 输出最后一个元素
# 切片操作
print("从索引 1 到 3 的元素:", arr1d[1:4]) # 包含起始索引,不包含结束索引[)
print("从索引 2 到最后的元素:", arr1d[2:]) #[2:-1]
print("前 3 个元素:", arr1d[:3]) #[0:3)

二维数组索引
二维 numpy 数组可以看作是由行和列组成的矩阵,索引时需要指定行和列的下标。
import numpy as np
# 创建二维数组
arr2d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 访问单个元素
print("第二行第三列的元素:", arr2d[1, 2]) # 行索引为 1,列索引为 2
# 访问整行或整列
print("第二行的元素:", arr2d[1]) # 访问第二行
print("第三列的元素:", arr2d[:, 2]) # 访问第三列
# 切片操作
print("前两行的前两列元素:\n", arr2d[:2, :2])

三维数组索引
三维 numpy 数组可以看作是多个二维数组的堆叠,索引时需要指定三个维度的下标,分别对应层、行和列。
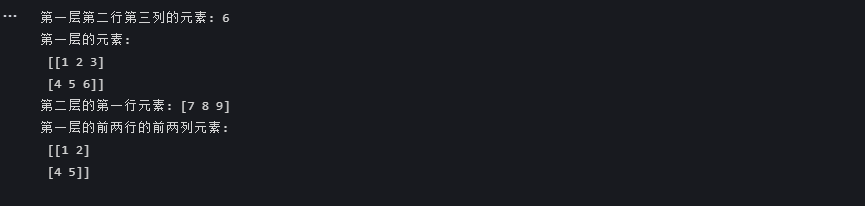
import numpy as np
# 创建三维数组
arr3d = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])
# 访问单个元素
print("第一层第二行第三列的元素:", arr3d[0, 1, 2]) # 层索引为 0,行索引为 1,列索引为 2
# 访问某一层的元素
print("第一层的元素:\n", arr3d[0])
# 访问某一层的某一行
print("第二层的第一行元素:", arr3d[1, 0])
# 切片操作
print("第一层的前两行的前两列元素:\n", arr3d[0, :2, :2])
上述代码展示了不同维度 numpy 数组的索引方式,根据具体需求灵活运用这些索引方法来访问数组中的元素。
Shap库
SHAP(SHapley Additive exPlanations)值是一种用于解释机器学习模型预测结果的方法,由博弈论中的Shapley值概念引申而来。下面从多个方面深入理解SHAP值。
1. 基本概念
在博弈论里,Shapley值用于公平分配合作博弈中的总收益。在机器学习模型解释场景中,每个特征就像博弈中的参与者,模型的预测结果是总收益,SHAP值则衡量每个特征对预测结果的贡献。
2. 核心思想
SHAP值的核心目标是为每个特征分配一个值,这个值表示该特征在特定预测中对模型输出的影响。对于一个预测结果,所有特征的SHAP值之和加上模型的基线预测值,就等于该预测结果。
3. 计算原理
计算SHAP值的过程本质上是在所有可能的特征组合下,评估某个特征加入前后模型预测结果的变化,然后对这些变化求平均。
4. 优点
- 一致性 :如果一个特征在不同的数据点和模型中对预测结果的影响是一致的,那么其SHAP值也会保持一致。
- 局部准确性 :所有特征的SHAP值之和能准确地还原模型的预测结果。
- 全局可解释性 :通过对多个样本的SHAP值进行汇总分析,可以得到特征在全局层面的重要性。
5. 局限性
- 计算复杂度高 :精确计算SHAP值的时间复杂度是指数级的,当特征数量较多时,计算成本会非常高。
- 依赖数据分布 :SHAP值的计算依赖于数据的分布,不同的数据分布可能会导致不同的SHAP值。
6. 应用场景
- 模型解释 :帮助理解模型在单个样本和全局层面上的决策过程。
- 特征选择 :通过SHAP值的大小来评估特征的重要性,从而选择重要的特征。
7. 代码示例
以下是使用 shap 库计算和可视化SHAP值的简单示例:
import shap
import xgboost
import pandas as pd
# 读取 heart.csv 文件
file_path = r'e:\2025_python\csv\heart.csv'
data = pd.read_csv(file_path)
# 分离特征和目标变量
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
# 训练 XGBoost 模型
model = xgboost.XGBRegressor().fit(X, y)
# 创建 SHAP 解释器
explainer = shap.Explainer(model)
shap_values = explainer(X)
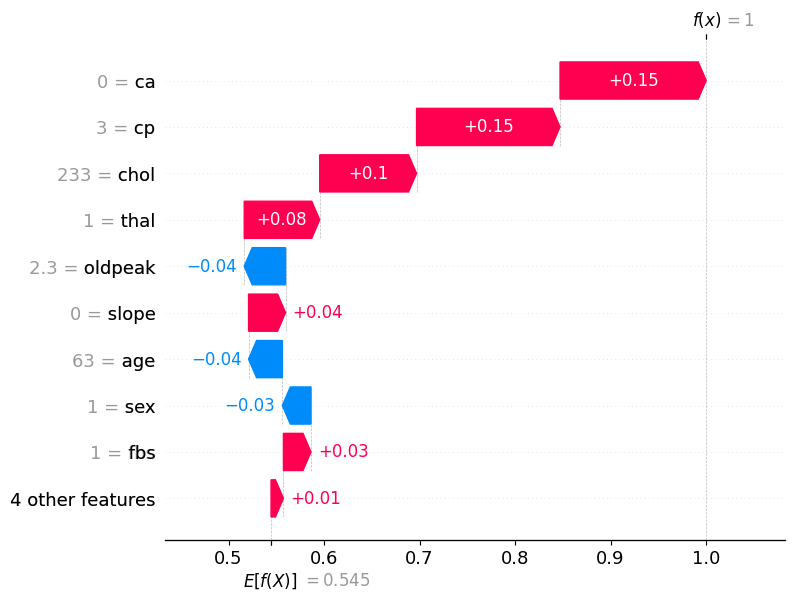
# 可视化第一个样本的 SHAP 值
shap.plots.waterfall(shap_values[0])
总结
- Numpy 数组索引 :使用不同维度 numpy 数组索引方式访问元素。
- Shap 库介绍
为每个特征分配值,所有特征 SHAP 值与基线预测值之和等于模型预测结果。通过评估特征加入前后模型预测变化求平均得出,给出计算公式。优点有一致性、局部准确性和全局可解释性;缺点是计算复杂度高且依赖数据分布。可用于模型在单个样本和全局层面的决策过程解释,还能通过 SHAP 值大小进行特征选择。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









