







写在前面:没有用过es,来学习一下。
下载文件
es官网链接的下载地方,我下载的是 window
window
下载往后拉也有步骤: 1下载and解压 Elasticsearch 2 Run bin/elasticsearch (or bin\elasticsearch.bat on Windows)
3 游览器输出 http://localhost:9200/ 4出现信息(视频的老师说,cmd执行 会出现start,但是我没看到,可能是没发现,敲链接也出来了)
至此,算是有了。Ps:执行3的时候需要jdk1.8,但是有电脑里有1.7和1.8,查看版本的时候报错has value '1.8',but'1.7' is required',解决方法看了这篇,就解决了
在本地启动集群的方式:
1 bin/elasticserach (默认配置)
2 bin/elasticsearch -Ehttp.port=8200 -Ehttp.data=node2 (修改对外的端口和存储地址)
3 bin/elasticsearch -Ehttp.prot=7200 -Epath.data=node3 (同上)
我起了3个cmd,输入了上面的命令。打来3页页面,都起来了,虽然name都一样
验证节点是否组成集群→通过api去看:
localhost:8200/_cat/nodes (可以看到明细)
localhost:8200/_cat/nodes/?v (可以看到明细+标题解释 master *代表主节点)
看class相关的→localhost:8200/_cluster/stats (可以看到详情信息)
安装插件
安装elasticsearch-head-master插件,github上的一个mobz开头那个。下载后直接解压缩。
视频里的老师直接进去了之后 npm install 之后就 npm run start 看出起好了返回了url,游览器输入出现了

但是我这里一直报错

然后 npm install 也不行,问了前端的小姑凉说你install失败是因为没有镜像,下载不下东西 自然也就没有grunt了,然后发来了公司的镜像地址,复制进去执行,等等就下载好了,然后在run,终于返回http://localhost:9100/,菜鸡哭唧唧。
然后可以看到 集群健康值:未连接
es 和 head 是2个独立的进程,2个访问有跨域问题,要修改2个配置
es目录下 config文件夹下elasticsearch.yml文件 在最后加入下面2行:
http.cors.enabled: true
http.cors.allow-origin: "*"
可能是一开始看的其他的视频,弄了下es,所以启动的es可以,启动head可以,但就是集群连接不上,head连接的时候,es这里还报错。no known master node, scheduling a retry ;master-not-discovered-exception。最后把es的删掉了,重新解压了文件,在.yml的文件加上上面2句,然后启动,终于看了started!!!![]()
然后集群就连接上了,那个报错弄了好久,菜鸡哭唧唧。
分布式安装(扩容)
主master的设置,elasticsearch.yml里添加:
cluster.name: xxx
node.name: master
node.master: true
network.host: 127.0.0.1
保存退出,刷新head,就可以看到master![]()
随从的节点:新建文件夹es-slave1,把es的压缩包解压在里面,然后在了elasticsearch.yml文件加上:
cluster.name: xxx
node.name: slave1
network.host: 127.0.0.1
http.prot: 8200 //不配置默认是9200 会和 主master 冲突
discovery.zen.ping.unicast.hosts: ["127.0.0.1"] //找到master,不配就会找不到
然后启动es-salve1的es,刷新head
(注意一定要重新解压es的压缩包,而不要复制之前的改个名字。新建slaver2,也是上面那个流程)
Elasticsearch常用术语
index 索引 (可以理解为mysql里的数据库)
Type 索引中的数据类型 (可以理解为mysql里的table,表的概念)
Document 文档数据 (相当于一行记录)
Field 字段,文档的属性
Query DSL 查询语法
Elasticsearch CRUD
查询语法:
1 Query String GET /accounts/persom/_search?q=xxx
2 Query DSL GET /accounts/person/_search{
"query":{"match":{"name":"xxx"}}}
索引创建
head里面索引,选择新建索引。分片数和副本数可以指定的。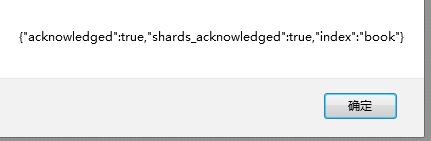
在概览可以看到。有很多数字框框都是es的分片,粗的框框是分片,细的是备份。细的是粗的的备份。这样创建是:非结构化创建。怎么知道它是什么样的创建呢,在概览里,索引→信息,点 索引信息,看关键词 mappings 有没有值,没有值就是非结构化创建。然后结构化创建,在head里复合查询里输入,也可以用postman,有点复杂数据,手打json。直接按照老师了的输入,照样的输入了一样的。
插入
自动产生文档id插入

指定文档id插入
指定的id就是上面 movies/movie/1 加上指定的id,然后用put请求,就可以了,右边返回的id也是你定义的1.
在head里的数据浏览可以看到插入的数据

修改
直接修改文档

脚本修改文档
url和上面的是一样的,内容不一样
{
"script": {
"lang": "painless",
"inline": "ctx._source.title = params.title",
"params": {
"title": "HelloWorld"
}
}
}感觉有点麻烦。。。
删除
删除文档

删除索引

head里也可以直接操作删除
查询
get ip:prot/索引/类型/指定的id --指定搜索
post ip:prot/索引/_search -- 全局搜索 body体内可以写详细的

took 代表请求消耗的6毫秒
hits 返回的所有结果,默认返回10条
具体的一些查询,写在了Sense里,在Sense的文章里,指路→Sense插件的里查询。
实践:整合springboot+es
pom文件 加了 对应的依赖
按照老师说的,建一个配置类,但是我的![]()
报红,后来别的文章说 :官方已经明确表示在ES 7.0版本中将弃用TransportClient客户端,且在8.0版本中完全移除它
看来配置只能看其他的文章了
感觉烂尾了,5月弄得,9月了先发出来吧,日后还会有机会吗,小皮卡,















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









