







目录
前言
随着人工智能的发展,大数据时代到来。面对大型的数据和模型训练时,我们不可避免的需要使用多GPU进行训练,接下来我将简单介绍pytorch中如何使用多GPU进行并行训练。pytorch中有两种方式进行多卡训练:
你将学习到在PyTorch中如何使用多GPU进行并行训练。在PyTorch中使用多GPU训练神经网络模型是非常简单的,PyTorch已经为我们封装好一个 nn.DataParallel 类来进行多GPU训练。
一、Pytorch多GPU并行训练的两种方式
1、DataParallel(DP)
DataParallel实现较为简单,但所有的loss都在主卡上计算,负载不均衡的问题比较严重。
2、DistributedDataParallel(DDP)
DistributedDataParallel可以支持一机多卡训练也可以支持多机多卡训练,官方也建议使用新的DistributedDataParallel,但是实现相对较为复杂。
以后有时间可以再详细讲一下如何用这种分布式的并行方法进行训练。本文主要讲解如何使用DataParallel进行GPU并行。
二、查看显卡资源&将数据放入GPU中
1.查看显卡资源
通过输入nvidia-smi命令查看显卡的编号和使用情况
nvidia-smi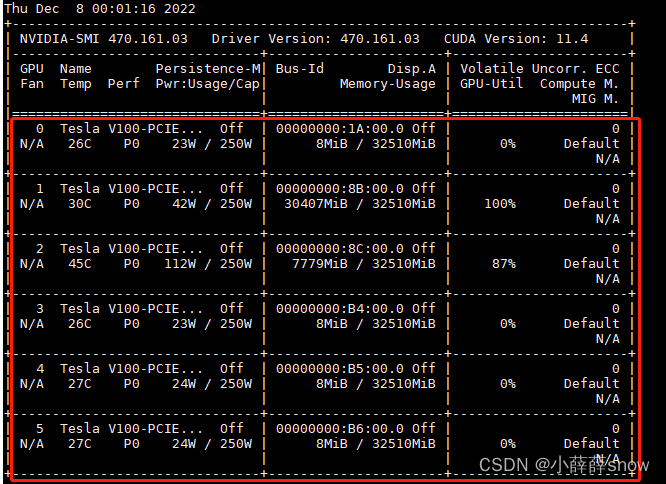
2、将数据放到GPU上
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '4,5' #指定GPU编号
device = torch.device("cuda") #创建单GPU对象
net.to(device=device) #将网络放到GPU
x_train = Variable(train,requires_grad=True).to(device=device,dtype=torch.float32) #把训练变量放到GPU三、 使用DataParallel进行多GPU训练
1、导入库
import torch#深度学习的pytoch平台
import torch.nn as nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torch.utils.data import TensorDataset2、声明GPU
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '4,5' #指定编号为4,5的GPU参与训练3、定义网络
以下定义网络作为示例:
class DNN(nn.Module):
def __init__(self,layers):
super().__init__()
'Initialise neural network as a list using nn.Modulelist'
self.linears = nn.ModuleList([nn.Linear(layers[i], layers[i+1]) for i in range(len(layers)-1)])
self.elu = nn.ELU()
def forward(self,d):#d就是整个网络的输入
if torch.is_tensor(d) != True:
d = torch.from_numpy(d)
a = d.float()
for i in range(len(layers)-2):
z = self.linears[i](a)
a = self.elu(z)
a = self.linears[-1](a)
return a4、定义网络参数
最重要的!!!在这里把模型放到GPU里!!!
使用 nn.DataParallel 打包模型,然后用 nn.DataParallel 的 model.to(device) 把模型传送到多块GPU中进行运算。
#一些基本参数变量的确定以及数据格式的转换
device = torch.device("cuda")
epochs = 1000 #迭代次数
initial_lr1 = 0.0005 #学习率
layers = [4,50,50,50,50,50,50,50,50,50,1] #网络每一层的神经元个数
net = DNN(layers)
net = nn.DataParallel(net)
net.to(device=device)
optimizer = torch.optim.Adam(net.parameters(), lr=initial_lr1) #优化器
mseloss = nn.MSELoss(reduction='mean') #损失函数,这里选用的是MSE。训练过程不需要再改变,保持自己原来的代码就OK。
总结
利用DataParallel进行多GPU训练还是很简单的,只需要在一开始导入库的时候分配好使用几块GPU,然后把模型用DataParallel进行包装就可以完成。

















 1385
1385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











