






1、时间戳问题
使用Hive数据平台取数时踩的一个和时间戳相关的小坑,记录下来,相当于在坑前插个小旗,让大家尽量避免掉到同样的坑里。
比如,数据库sda.application_detail表中数据如下:
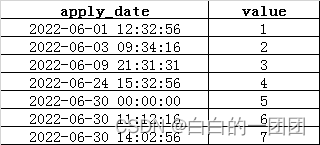
现在我们想取出所有6月份的数据,sql语句是这样写的:
select * from sda.application_detail
where apply_date>=date'2022-06-01' and apply_date<=date'2022-06-30'
看起来没什么问题,但当我们看取数结果的时候,发现结果如下:
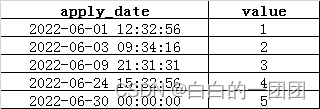
漏掉了6月30号的最后两条数据,为什么呢?问题出在where后面的apply_date<=date’2022-06-30’,这个条件并不像我们想象的那样,先把apply_date转换成不带时分秒的日期‘2022-06-30’,然后用转换后的日期和date’2022-06-30’做比较。实际上,虽然我们这样写了日期转换,但它实际上还是用原始的时间戳‘2022-06-30 11:12:16’和时间戳‘2022-06-30 00:00:00’作比较。所以当我们写成apply_date<=date’2022-06-30’时,最后两条数据就被过滤掉了,而‘2022-06-30 00:00:00’的这条记录会保留在我们的结果里面。
所以想要完整取到6月份的数据,可以用以下两种方式去写sql:
方式一,日期往后延一天:
select * from sda.application_detail
where apply_date>=date'2022-06-01' and apply_date<date'2022-07-01'
方式二,都转换成时间戳:
select * from sda.application_detail
where unix_timestamp(apply_date)>=unix_timestamp('2022-06-01 00:00:00')
and unix_timestamp(apply_date)<=unix_timestamp('2022-06-30 23:59:59')
第二种方式虽然可以精确到时分秒,但运行速度没有第一种方式快。
2、执行顺序问题
sql执行顺序:
from
join
on
where
group by
avg,sum等聚合函数
select
having
distinct
order by
在使用 row_number() over()函数时候,over()里头的分组以及排序的执行晚于 where、group by、order by的执行
limit















 1701
1701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









