






 本文讲述了使用OpenCompass进行大模型评测的步骤,涉及环境配置、模型部署和在C-Eval数据集上的性能展示。
本文讲述了使用OpenCompass进行大模型评测的步骤,涉及环境配置、模型部署和在C-Eval数据集上的性能展示。
OpenCompass大模型评测
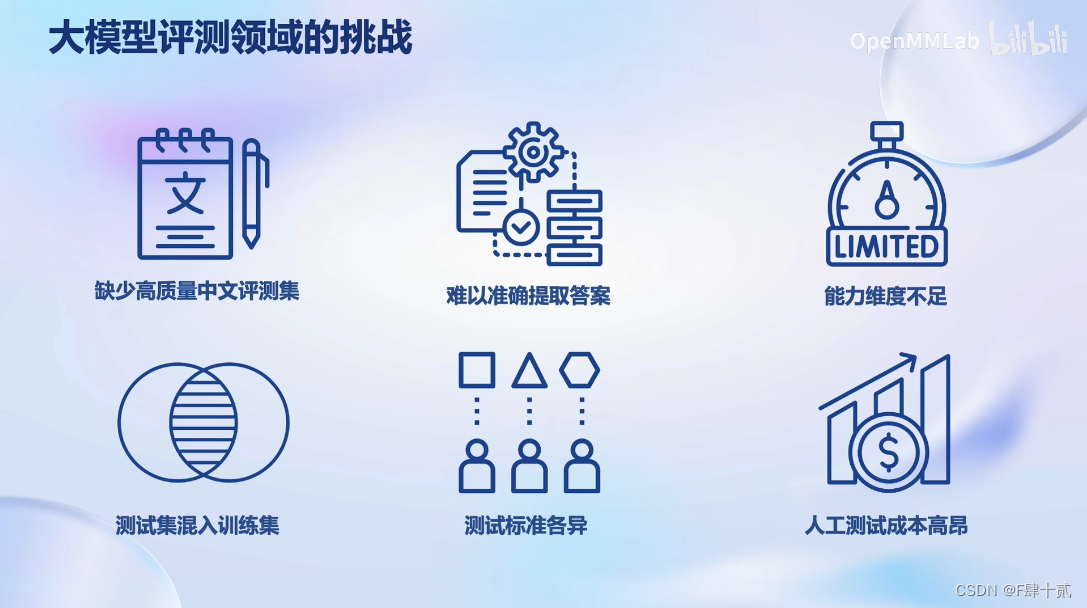
这一课的内容主要是介绍一下为什么要评测,还有如何评测,最后再介绍了一下OpenCompass评测工具。
关于评测的三个问题
- 为什么需要评测?
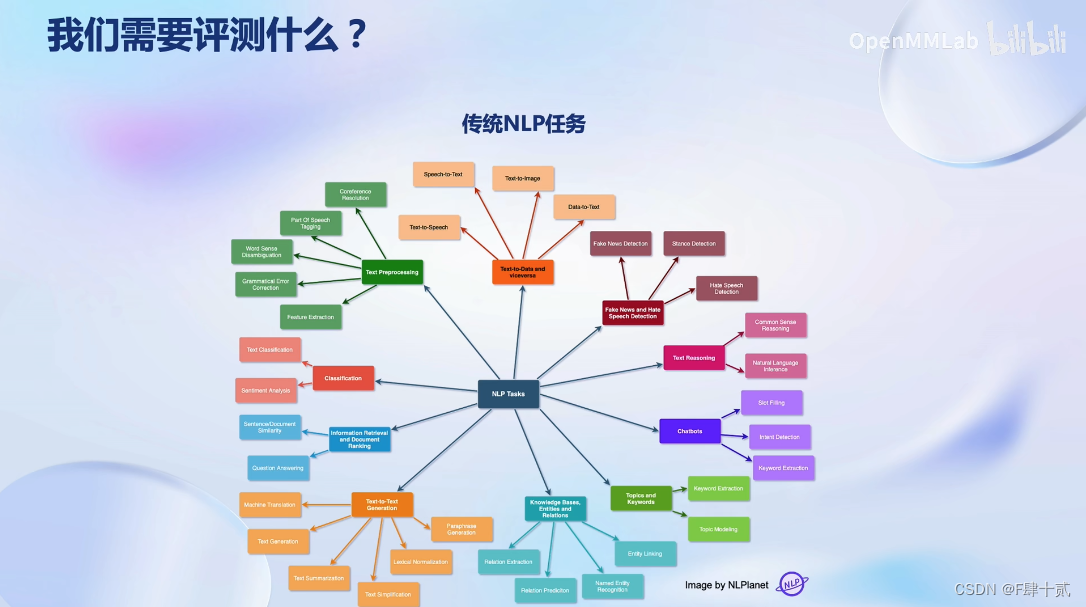
- 我们需要测什么?
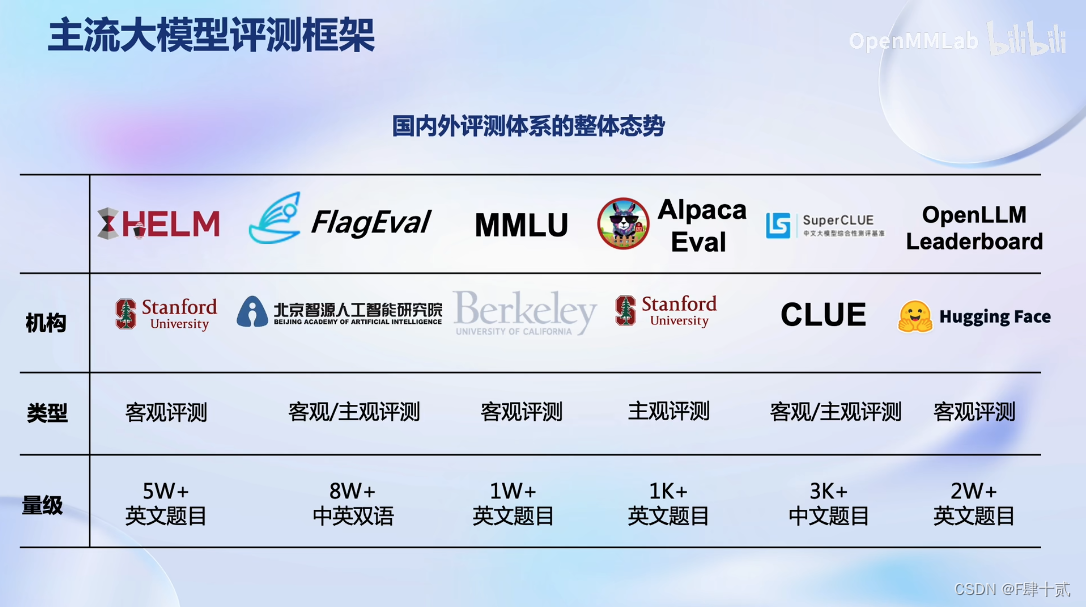
- 怎么样测试大语言模型?











基础作业
- 使用 OpenCompass 评测 InternLM2-Chat-7B 模型在 C-Eval 数据集上的性能
- 第一步是安装环境,按照官方文档进行,很顺利就能部署好
- 第二步是准备评测数据这里的ceval是服务器中准备好了的,解压就行
- 第三步启动评测
-
python run.py --datasets ceval_gen --hf-path /share/temp/model_repos/internlm-chat-7b/ --tokenizer-path /share/temp/model_repos/internlm-chat-7b/ --tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True --model-kwargs trust_remote_code=True device_map='auto' --max-seq-len 2048 --max-out-len 16 --batch-size 4 --num-gpus 1 --debug
-
命令行参数解析
--datasets ceval_gen \
--hf-path /share/temp/model_repos/internlm-chat-7b/ \ # HuggingFace 模型路径
--tokenizer-path /share/temp/model_repos/internlm-chat-7b/ \ # HuggingFace tokenizer 路径(如果与模型路径相同,可以省略)
--tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True \ # 构建 tokenizer 的参数
--model-kwargs device_map='auto' trust_remote_code=True \ # 构建模型的参数
--max-seq-len 2048 \ # 模型可以接受的最大序列长度
--max-out-len 16 \ # 生成的最大 token 数
--batch-size 2 \ # 批量大小
--num-gpus 1 # 运行模型所需的 GPU 数量
--debug
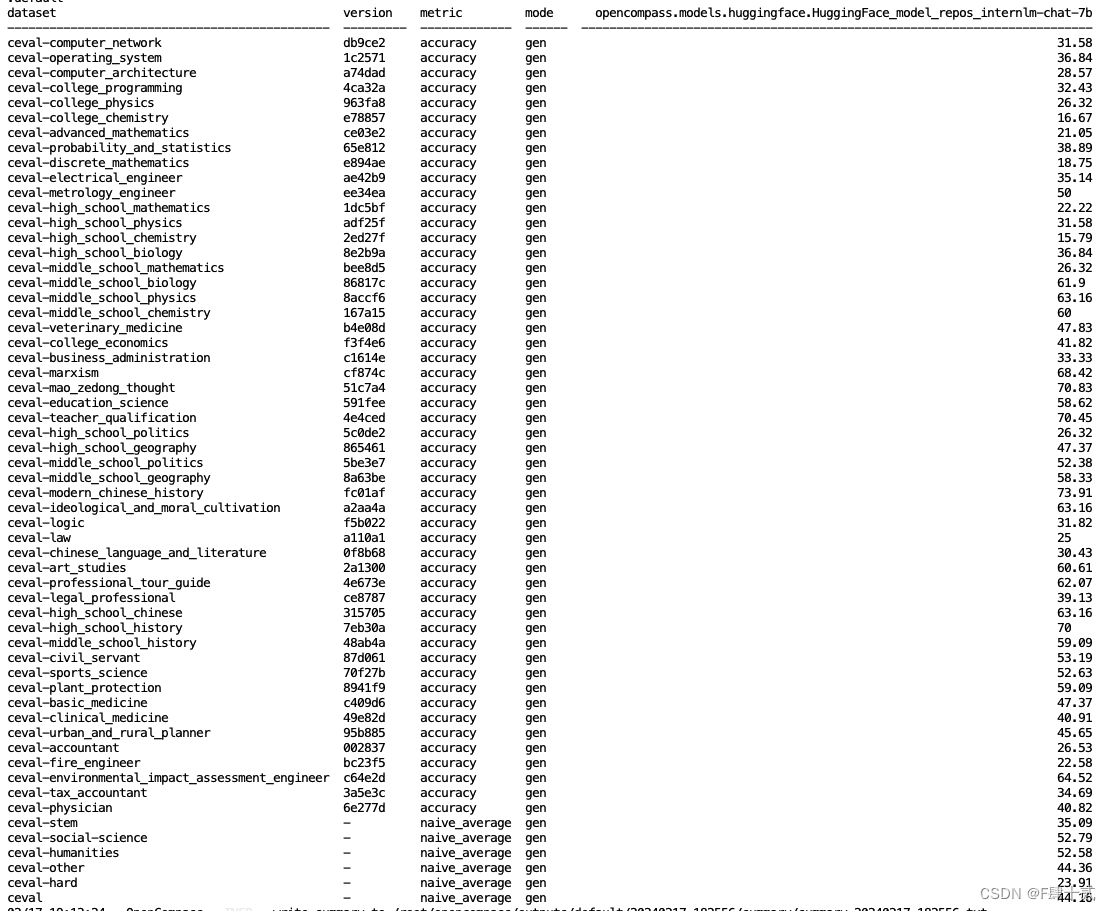
运行完后的结果如下图
进阶作业
- 使用 OpenCompass 评测 InternLM2-Chat-7B 模型使用 LMDeploy 0.2.0 部署后在 C-Eval 数据集上的性能















 570
570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









