







学习目标:
学会elstaticsearch基本使用,熟悉docker部署
提示:因为elstaticsearch对版本的要求比较严格,以及各个版本的es对于他的一些api是不一样的。所以大家尽量和我保持一致 elasticsearch:7.14.0 和 kibana:7.14.0(这个和navicat差不多,就是一个操作es的一个软件,但是尽量和es版本保持一样) 有的人使用的压缩包安装的,但是我们为了省事情。这里就用docker的方式进行安装,也会给大家讲解一些我知道的docker的命令。先在自己的电脑上安装docker desktop这个软件。应用商店应该就可以下载
1. docker中安装elstaicsearch和kibana
# 安装es7.14.0
docker pull elasticsearch:7.14.0
# 安装kibana7.14.0
docker pull kibana:7.14.0
#安装完成后,查看已经安装了哪些镜像
docker images
kibana中默认的访问端口是5601
elsticsearch的api端口是9200,他的通信端口是9300

2. 通过docker-compose 使用安装好的镜像
如果我们已经安装上了docker desktop的话,docker中就已经安装好了docker-compose了,如果没有安装这个软件的话,你们就需要自行安装一下这个docker-compose了。
# docker run -d (后台应用) -p 9200(宿主):9200(容器) -p9300:9300 (这个相当于宿主机的9200映射容器的9200端口) 镜像:版本
# 下面的这个命令就是docker运行es镜像的命令的一个例子
docker run -d -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.14.0
# 运行kibana
docker run -d -p 5601:5601 kibana:7.14.0
# 查看已经启动了的容器
docker ps
这里给大家说一下,本来我们这里是可以不用到docker-compose进行安装的,直接通过上面的命令直接运行的。但是,通过后面的学习,我们还要安装分词器,还有集群部署等,所以这里我们就直接跳过这种方式安装运行了,直接用docker-compose安装,就一步到位了。
因为当我们把容器停掉的话,容器中的数据就会丢失,所以我们要通过本地的文件映射到容器中。这里我们先把容器中的一个配置文件复制出来。这里继续给大家说几个docker中的命令。
# 从容器中复制文件 -> 宿主机中
docker cp [镜像id:文件路径|文件夹路径/] [宿主机文件路径|书主机文件夹路径/]
# 从宿主中复制文件 -> 容器中
docker cp [宿主机文件路径|书主机文件夹路径/] [镜像id:文件路径|文件夹路径/]
# 从cmd中进入容器中
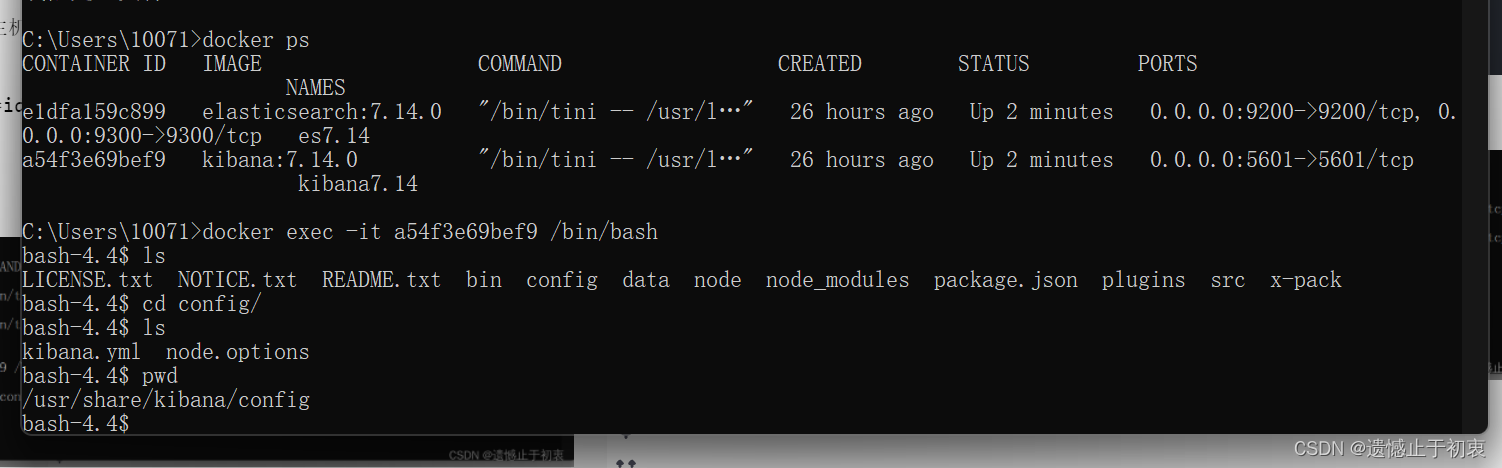
docker exec -it 容器名称/容器id /bin/bash
因为我之前是不是从docker-compose方式运行的,所以是通过上面复制的方式,把kibana的配置文件复制出来的。不过大家也可以直接自己新建一个kibana.yml文件。直接写,也没有多少
server.host: "0"
server.shutdownTimeout: "5s"
elasticsearch.hosts: [ "http://elasticsearch:9200" ]
monitoring.ui.container.elasticsearch.enabled: true
3.编写docker-compose
我们先新建一个文件夹。里面新建一个文件夹,里面新建一个docker-compose.yml的文件。 这里还需要下载一个分词器,ik分词器,后面我们再介绍这个是干什么的。这里先去github上面下载下来。然后解压放在这个新建的文件夹中,并且同时新建一个date的空文件夹
ik分词器

把这个下载下来,同样放到和kibana.yml中的同级目录下面。
docker-compose.yml文件
# 相当于我们使用docker命令的版本是3的
version: "3"
#services相当于下面会写几个服务
services:
#es服务名称随便起
elasticsearch:
#容器名称
container_name: "es7.14"
#使用哪个镜像
image: elasticsearch:7.14.0
#宿主机端口:容器端口 映射
ports:
- "9200:9200"
- "9300:9300"
# 因为我们要做数据持久话,所以我们需要把es中的data数据文件夹映射到宿主机上。 其中的data目录就就是es的数据存放的目录。所以为了持久化,我们再宿主机上面新建一个data目录,而那个ik目录是我们上面下载的那个分词器的目录,先这么配置上,我们待会在做解释
volumes:
- ./ik:/usr/share/elasticsearch/plugins/ik
- ./data:/usr/share/elasticsearch/data
#环境采用单例模式,这里还可以配置其他的环境参数。比如说jvm大小什么的
environment:
- "discovery.type=single-node"
# 网络,因为一个容器会给我们创建一个网络,所以我们这里采用公用的网络,这个网络在下面有申明,然后这两个容器就可以通过服务名称直接访问。
networks:
- "share"
kibana:
image: kibana:7.14.0
container_name: "kibana7.14"
ports:
- "5601:5601"
networks:
- "share"
# 配置kibana的配置文件
volumes:
- ./kibana.yml:/usr/share/kibana/config/kibana.yml
# 申明一个公共的网络share
networks:
share:
文件目录
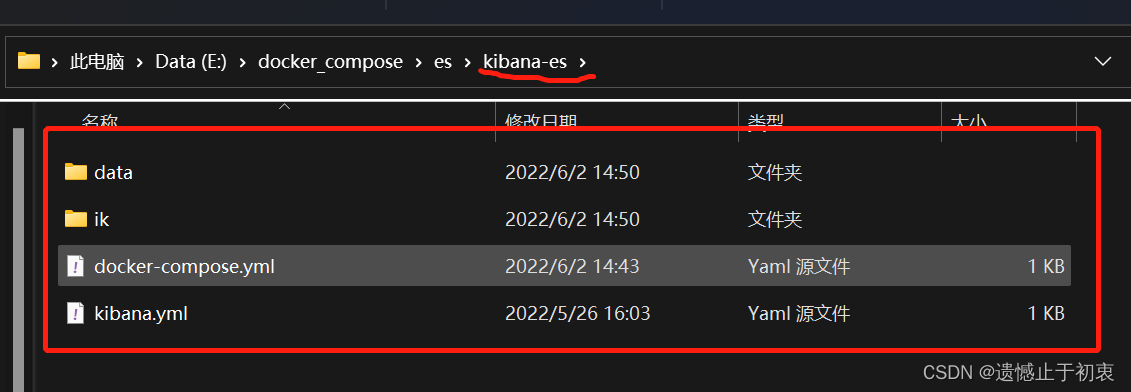
至此,所有的准备工作就已经结束了。
# 这里说一个启动docket-compose的启动命令
# 在你的文件目录下输入命令,会启动docker-compose.yml 这个文件,
docker-compose up -d
#如果你的文件不叫docker-compose.yml 可以用下面的这个命令启动
docker-compose -f 文件 up -d
#关闭同时删除容器
docker-compose down
docker-compose -f 文件 down
docker start 容器ID #启动容器
docker stop 容器ID #停止容器
docker restart 容器ID #重启容器
docker kill 容器ID #杀掉容器
docker logs -f 镜像id 查看docker镜像运行的日志
docker ps # 查看当前运行的镜像
然后我们启动我们制做好的配置文件。启动容器执行上面的那个docker-compose up -d
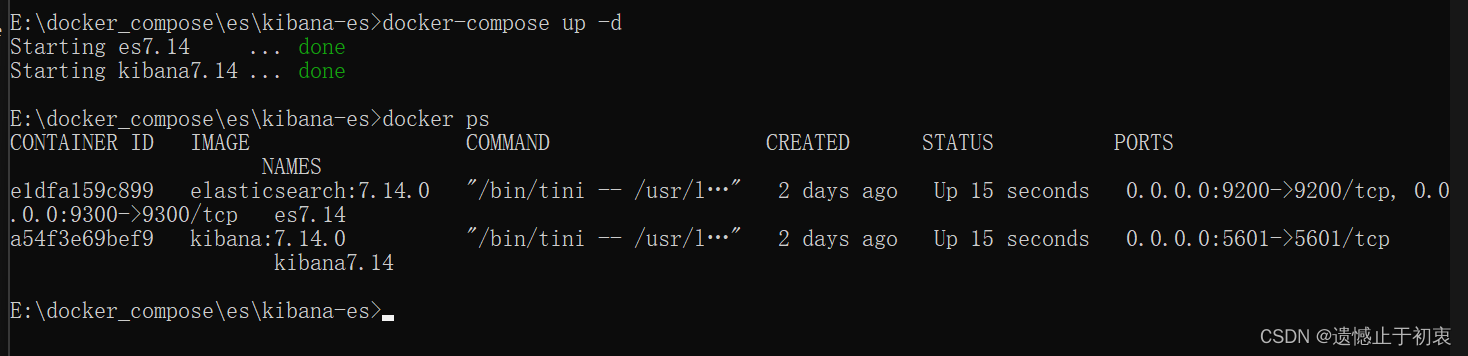
然后就可以通过 http://localhost:5601/app/home#/ 访问kibana了
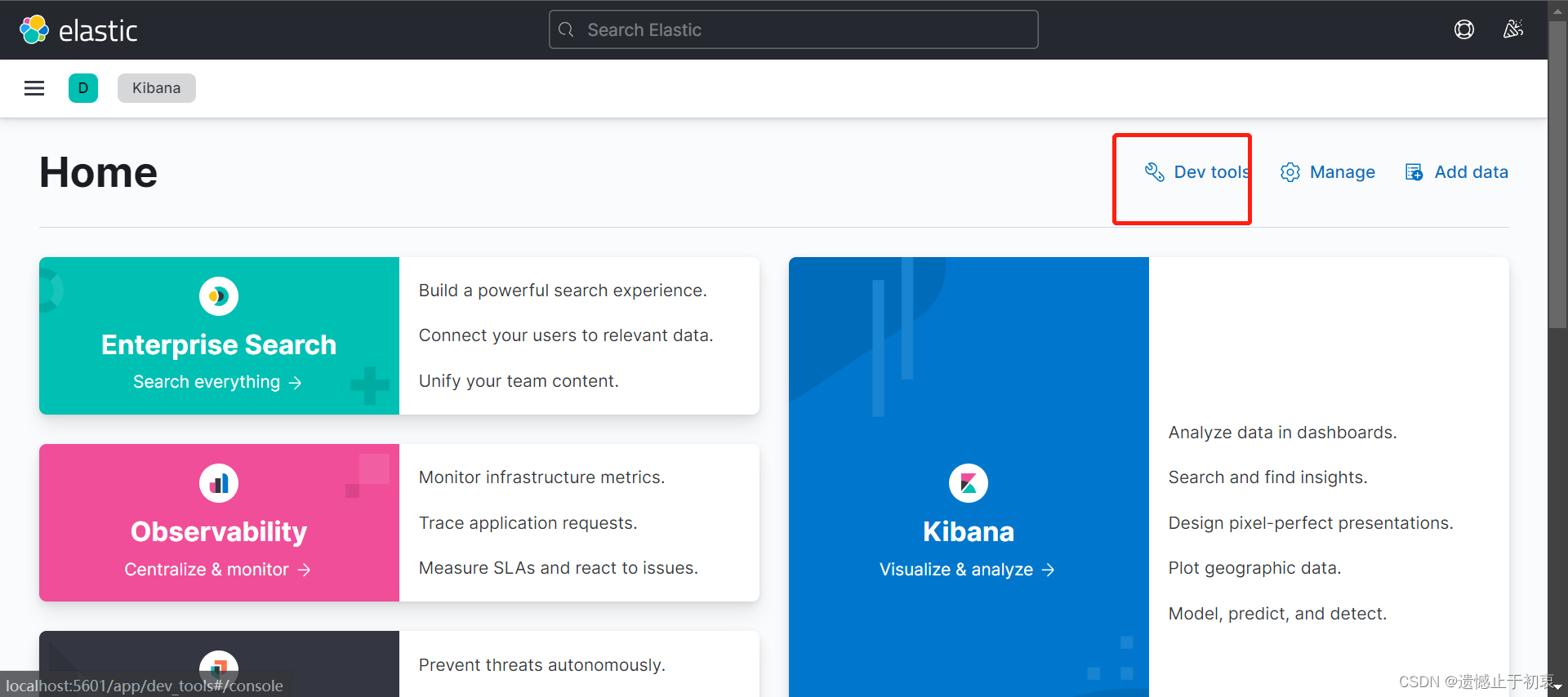
点击dev tools 进如编辑模式
4 学习elstaticsearch
4.0 es是非关系型的数据库(姑且叫数据库吧),他的数据是基于文档的形式的json串格式的数据。
4.1 我们先介绍一下es的几个概念,这里可以类比mysql中的概念学习一下。
- 索引(相当于MySQL中表的概念)
- 映射(相当于MySQL中表字段的概念)
- 文档(相当于MySQL中表中数据的概念)
4.2 说一下几个基本的数据类型
4.2.1、主要数据类型(这几个也是最常用到的)
string类型:text,keyword(默认不会被分词),wildcard
数字类型:long, integer, short, byte, double, float, half_float, scaled_float
日期类型:date
布尔类型:boolean
Binary:Binary
范围类型:integer_range, float_range, long_range, double_range, date_range, ip_range
4.2.2、复杂数据类型
Object:单个JSON对象
Nested:JSON对象数组
5 ElstaticSearch的curd
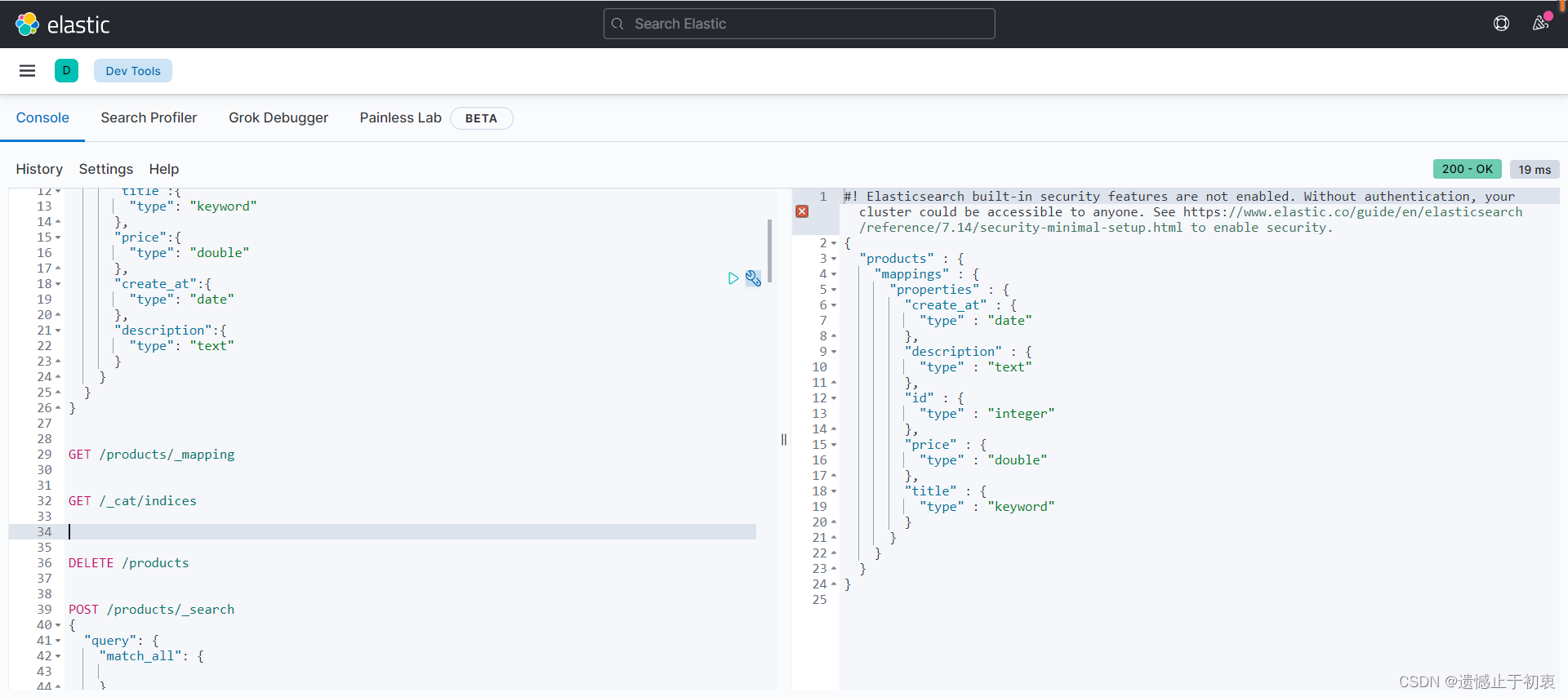
5.1 首先我们应该创建一个索引,索引名为products,数据映射为title(keyword),id(keyword),price(double),create_at(date),description(text)
es中的文档是有默认映射id的,这个id是_id 如果我们不指定,他是会给我们用uuid自动生成一个的,如果我们不指定id,指定了_id的话,es会自动的把_id放入到id中
#查看目前存在的索引
GET /_cat/indices
#查看索引对应的映射信息
GET /products/_mapping
#查看多个索引
GET /test_007,test_008
#查看所有索引
GET /*
#查看title对应的映射情况
GET /products/_mapping/field/title
#删除索引
DELETE /products
#新建一个索引
PUT /products
{
"mappings": {
"properties": {
"title":{
"type": "keyword"
},
"price":{
"type": "double"
},
"create_at":{
"type": "date"
},
"description":{
"type": "text"
},
"id":{
"type": "integer"
}
}
},
"settings": {
#一个副本,相当于这里会把数据复制一份出来
"number_of_replicas": 1,
#三个分片,这里的意思就是说会把数据近乎平均的放在三个分片中
"number_of_shards": 3
}
}
5.2 对索引中的数据进行增删改查
先说几个查询的格式,方便我们查看
#查询_id为1的文档
GET /products/_doc/1
#查询所有文档,默认已经分页了,每页大小为10
GET /products/_search
{
"query": {
"match_all": {}
}
}
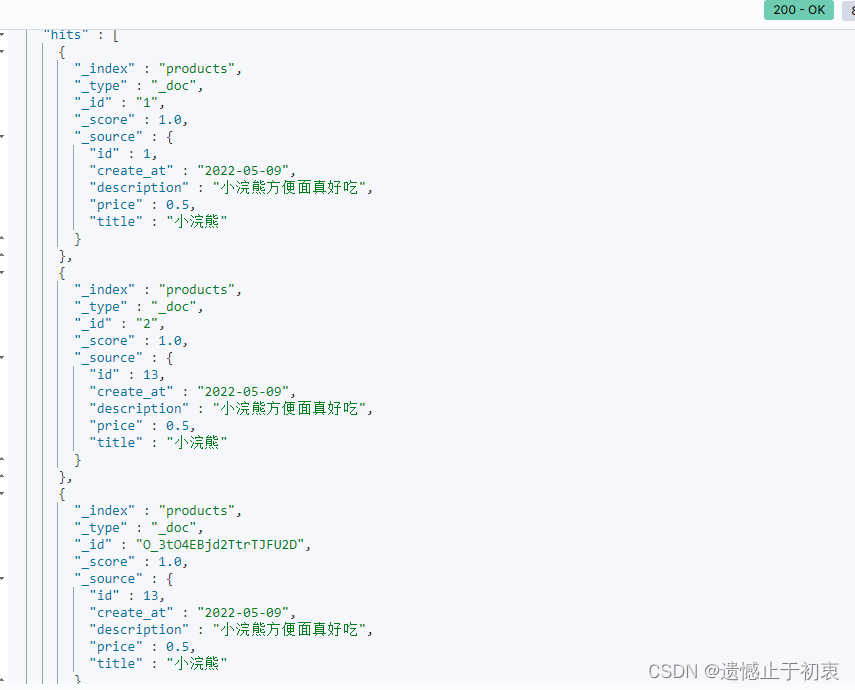
增加一条数据
# 新建一个文档,并指定_id为2,id为13
POST /products/_doc/2
{
# 下面这个id是真实文档的id,而上面的这个1是 _id的一个值
"id":13,
"create_at":"2022-05-09",
"description":"小浣熊方便面真好吃",
"price":0.5,
"title":"小浣熊"
}
#这个是不指定_id值的文档增加方式
POST /products/_doc
{
"id":13,
"create_at":"2022-05-09",
"description":"小浣熊方便面真好吃",
"price":0.5,
"title":"小浣熊"
}
查询结果:
修改上面我们新增的文档
#对指定数值的_id进行覆盖。看样子和上面的那个新增是一样的
POST /products/_doc/1
{
"title":"小浣熊熊",
"description":"小浣熊熊方便面真好吃"
}
# 对指定的数值的_id进行修改,不是覆盖
POST /products/_doc/2/_update
{
"doc":{
"title":"小狗熊",
"description":"小浣熊熊方便面真好吃"
}
}
删除指定文档
#根据_id值删除指定文档
DELETE /products/_doc/1
上面说的都是单个文档的操作,这里我们说几个批量操作的语法
#下面的操作可以同时包含多个,比如说可以全部都是增加,也可以全部是修改,和删除。
#这里需要注意的是要严格遵守这里的代码格式。因为这里是严格要求json的格式的。
POST /products/_doc/_bulk
{"index":{"_id":"6"}}
{"id":6,"create_at":"2020-05-05","title":"干脆面","description":"干脆面不能煮着吃","price":0.5}
{"update":{"_id":4}}
{"doc":{"title":"老干妈和老干爹"}}
{"delete":{"_id":5}}
#这里给你们一个数据的demo,下面查询的时候,方便有数据可查
POST /products/_doc/_bulk
{"index":{"_id":"1"}}
{"id":1,"create_at":"2020-05-18","title":"鱼豆腐","description":"鱼豆腐一般和火锅一起吃","price":4.8}
{"index":{"_id":"2"}}
{"id":2,"create_at":"2020-05-19","title":"韭菜","description":"韭菜可以做成韭菜包子","price":7.5}
{"index":{"_id":"3"}}
{"id":3,"create_at":"2020-05-20","title":"老乡方便面","description":"其实这个东西挺好吃的","price":1.5}
{"index":{"_id":"4"}}
{"id":4,"create_at":"2020-05-21","title":"麻辣香锅","description":"感觉就是麻辣拌","price":20.5}
{"index":{"_id":"5"}}
{"id":5,"create_at":"2020-05-22","title":"麻辣烫","description":"小号版本的麻辣水煮菜","price":18.5}
{"index":{"_id":"6"}}
{"id":6,"create_at":"2020-05-23","title":"海底捞火锅","description":"这他妈真贵","price":207.5}
{"index":{"_id":"7"}}
{"id":7,"create_at":"2020-05-24","title":"韩国泡面","description":"其实泡面起源于中国","price":2.5}
{"index":{"_id":"8"}}
{"id":8,"create_at":"2020-05-25","title":"中国泡菜","description":"泡菜起源于中国","price":11.5}
{"index":{"_id":"9"}}
{"id":9,"create_at":"2020-05-26","title":"玉米粒","description":"今天吃了玉米粒子,真好吃","price":13.5}
{"index":{"_id":"10"}}
{"id":10,"create_at":"2020-05-27","title":"酸奶","description":"今天中午喝了一个加蜂蜜的酸奶","price":14.5}
{"index":{"_id":"11"}}
{"id":11,"create_at":"2020-05-28","title":"烤串","description":"这个周末,我准备约人去吃烤串","price":104.5}
重头戏:查询,说几个常用的吧,需要记忆,都是语法格式(记得把上面的数据重新弄一编,下面要做搜索)
match_all 查询
#全文查询
POST /products/_search
{
"query": {
#查询全部
"match_all": {}
},
#这里代表从第0页开始,es已经默认给我们分页了,如果我们不写。这里也是0
"from": 0,
#这里代表每页20条,es默认是10条
"size": 20,
#加一个排序字段,学过mysql应该懂
"sort": [
{
"id": {
"order": "asc"
}
}
]
}
这里说个概念吧。es中有分词的一个概念,就像我们百度的时候,随便输入一个词,他会把你的词给你分开,然后在去进行匹配,搜索包含你分开的这些词语。在es中是自带分词器的。如果是碰到中文,自带的分词器,会把中文按字进行拆分的,如果是英文单词他会按照一个单词一个单词的拆分开进行分词的。之前让大家装了一个ik分词器,他是可以帮我们对汉字可以不单单是拆分成单个字。还可以拆出一些组合的词语
#可以执行一下这句话。看一下
POST /_analyze
{
#这个代表采用ik分词器,如果想看默认的,就改成standard。
"analyzer": "ik_max_word",
#被分词的内容
"text": "中华人民共和国国歌"
}
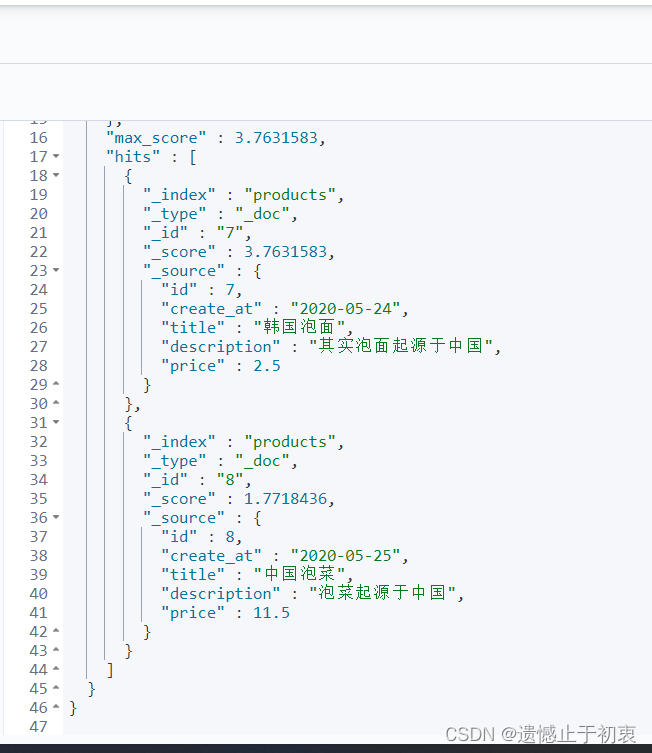
match查询,match查询是先对搜索词进行分词,然后在去文档中对已经分好的词进行搜索,默认的分词器是standard,
POST /products/_search
{
"query": {
"match": {
"description": "泡面"
}
}
}
可以看到有”泡“和”面“字的都被搜索出来了。
match_phrase查询。这个同样是进行匹配但是这个对于搜索词是不分词的。
POST /products/_search
{
"query": {
"match_phrase": {
"description": "泡面"
}
}
}
match_phrase_prefix,这个是匹配字段以某值开头的,也是对搜索词不分词
POST /products/_search
{
"query": {
"match_phrase_prefix": {
"description": "其实"
}
}
}
范围查询(对价格进行范围查询搜索) 关键词 range,里面我就说多加了一个排序
POST /products/_search
{
"query": {
"range": {
"price": {
"gte": 5,
"lte": 20
}
}
},
"sort": [
{
"id": {
"order": "asc"
}
}
]
}
这里讲几个es中的逻辑符号must(and) should(or) must_not(!)
POST /products/_search
{
"query": {
# 这是布尔查询,true/false 也就是说这个。必须的填写
"bool": {
# 下面这个条件就是说must里面中的组合的连接条件是and
"must": [
{"match": {
"description": "水煮菜"
}}
]
}
}
}
6 补充点
在es中除了上面的几种类型,还有几个 array,object,nested
1.先说这个array,这个类型可以不用申明,基本上所有的数据类型都可以申明成为数组类型的,只不过需要保证的数组中所有的数据类型得是一样的。
#创建一个索引
PUT /test
{
"mappings": {
"properties": {
"data1":{
"type": "text",
"analyzer": "ik_max_word"
},
"data2":{
"type": "date",
"format": "yyyy-MM-dd"
}
}
},
"settings": {
"number_of_replicas": 1,
"number_of_shards": 3
}
}
# 比如说在增加的时候可以这么写
POST /test/_doc
{
"data1":["我是大美女","我是大帅哥"],
"data2":["2002-12-13","2022-12-13"]
}
2.object这个是需要申明类型的,这个object是一个对象的类型,这里需要注意的是List中的object不允许彼此独立地索引查询。也就是说在数组中的对象,只要几个对象联合起来满足条件就可以被搜索出来
#新建一个索引
PUT /test1
{
"mappings": {
"properties": {
"data":{
"type": "object"
}
}
}
}
#新建几条数据
POST /test1/_doc/1
{
"data": [
{
"name": "es6",
"age": 1
},
{
"name": "es7",
"age": 2
}
]
}
POST /test1/_doc/2
{
"data": [
{
"name": "es7",
"age": 1
},
{
"name": "es6",
"age": 2
}
]
}
#在搜索一下 name=es6 and age=1 看下面这个,按照想的,应该只会搜出来一条
#但是,执行下面这句话的时候可以看出来,查询出来两条,这就可以理解为什么上面说的
#List中的object不允许彼此独立地索引查询
POST /test1/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"data.name": {
"value": "es6"
}
}
},{
"term": {
"data.age": {
"value": "1"
}
}
}
]
}
}
}
3.这里在看nested这个类型,这个类型也是对象类型,但是这个和上面object的区别就是在list做数组的时候允许作为独立索引出现进行查询。
4.在es中如果我们想做根据查询出的结果进行跟新和删除怎么操作呢
#下面的查询条件这里就不讲了,和上面的查询是一样的
#根据查询出的结果进行跟新
POST /test/_update_by_query
{
"query": {
"match_all": {}
},
"script": {
"source": "ctx._source.data1 = params.name",
"lang": "painless",
"params" : {
"name":"我是帅哥"
}
}
}
#根据查询出的结果批量删除
POST /test/_doc/_delete_by_query
{
"query": {
"match_all": {
}
}
}
这里也讲一下es中比较特别的倒排索引,有倒排索引就是正向索引,在mysql中的查询就是需要根据id来查询到数据,或者是我们通过其他条件进行查询的时候,也会有回表的这种操作,也还是变相的通过id进行查询。而在es中则不然,他是通过对数据进行分词,作为“索引”。在去关联id的。 这里我们通过一个例子来说明。
例子:
id:1 content :我们要好好吃饭
id:2 content: 我们要好好读书
| token | 倒排列表 |
|---|---|
| 我们 | 1,2 |
| 要 | 1,2 |
| 好好 | 1,2 |
| 吃饭 | 1 |
| 读书 | 2 |
通过上表我们不难看出倒排索引其实是包含两个部分的,其中第一个部分是索引项token,第二个是索引列表。而其中索引项其实又包含几个属性。
文档:Doc Id - 包含此Token的文档id
词频:TF - 单词在文档中出现的次数,用于相关性评分
位置:Position - 单词在文档中分词的位置,用于phrase query
偏移:Offset - 记录单词开始结束的位置,实现高亮显示
| 单词 | Doc Id | TF | Position | Offset |
|---|---|---|---|---|
| 吃饭 | 1 | 1 | 1 | <5,7> |
这里给大家推荐一个系列文章讲得非常不错,都是高级用法,可以看看
文章链接
















 2630
2630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









