






决策树是一种基本的分类与回归的方法,这里只讨论其分类过程。
分类决策树模型由结点和有向边组成,结点分为内部结点和叶结点,内部结点代表代表一个特征或属性,叶结点代表分类结果。根节点包含着所有的属性,从根节点开始,对实例通过某一特征进行测试,根据测试结果将实例分配到其子节点,如此递归地生成一棵决策树。
最后的决策树可用if-then规则来描述。对于三个特征的样本,从根节点到叶结点的一条路径可描述为“若特征A=***,特征B=***,特征C=***,则该样本属于***类”。
决策树的本质是从样本数据集中归纳出一组分类规则,与训练集不矛盾的决策树可能有很多种,我们要找的是一棵与训练集矛盾较小且具有很好泛化能力的决策树。对于生成的决策树,为了避免过拟合的问题,需要进行剪枝。
因此,决策树学习分为三步骤:特征选择、决策树的生成、剪枝。
1.1 特征选择
特征选择在于选取对训练数据有分类能力的特征,通常特征选择的准则是信息增益或信息增益比。
信息增益需要用到熵的定义:

熵越大,随机变量的不确定性也就越大。
特别地,若变量只取0和1时,则熵为:
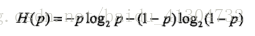
对于二维随机变量中的条件熵:

有了这两个概念,就可以得出信息增益的定义了:
特征A对数据集D的信息增益,定义为数据集D的熵减去特征A的条件下,数据集D的条件熵:

计算信息增益的算法流程如下:

信息增益比:解决了信息增益会受到数据集D的熵的大小扰动的问题,定义如下:
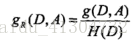
1.2 决策树的生成
经典的决策树生成算法有ID3和中出4.5算法。
ID3:

该算法容易产生过拟合。
C4.5算法:

区别就是两种算法对特征划分的依据不同,ID3算法按信息增益来划分特征,C4.5算法按信息增益比来划分特征,是对ID3算法的一个升级。
1.3 决策树的剪枝
剪枝是为了避免决策树的过拟合现象,分为预剪枝和后剪枝。
预剪枝:在选定特征准备划分的时候,先计算划分前与划分后的泛化能力,若划分后的泛化能力小于划分前的泛化能力,则直接将当前节点判定为叶结点。
后剪枝:整棵决策树生成以后,自下而上进行剪枝,剪去当前叶结点,将其父结点划分为新的叶结点,若这一剪枝过程可以提高整个决策树的泛化能力,则进行剪枝,否则禁止剪枝。














 339
339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









