






1.docker获取postgreSQL
在 Docker 上创建 Postgres 数据库,打开您的终端并运行此命令 👇🏾
$ docker run --name postgres-docker -e POSTGRES_PASSWORD=postgres -p 5432:5432 -d postgres它能做什么:
-
它从DockerHub拉取
PostgresDocker 镜像, -
将
POSTGRES_PASSWORD环境变量值设置为postgres, -
将 (
--name) Docker 容器命名为postgres-docker, -
将容器的内部
5432端口映射到外部5432端口,因此我们可以从外部进入它, -
并使我们能够在后台运行 Docker 容器(
-d)。来源
检查数据库容器是否正在运行 👇🏾
$ docker ps通过终端与您的数据库交互 👇🏾
$ docker exec -it postgres-docker bash
//使用exec,我们以分离模式-it进入 postgres-docker 容器并开始运行其 bash 应用程序 (bash)。我们可以:
-
登录
psql -U postgres -
创建表
CREATE TABLE users (id INTEGER PRIMARY KEY, name VARCHAR); -
显示数据库中的表
\dt
2.使用 IntelliJ 连接到正在运行的数据库容器
-
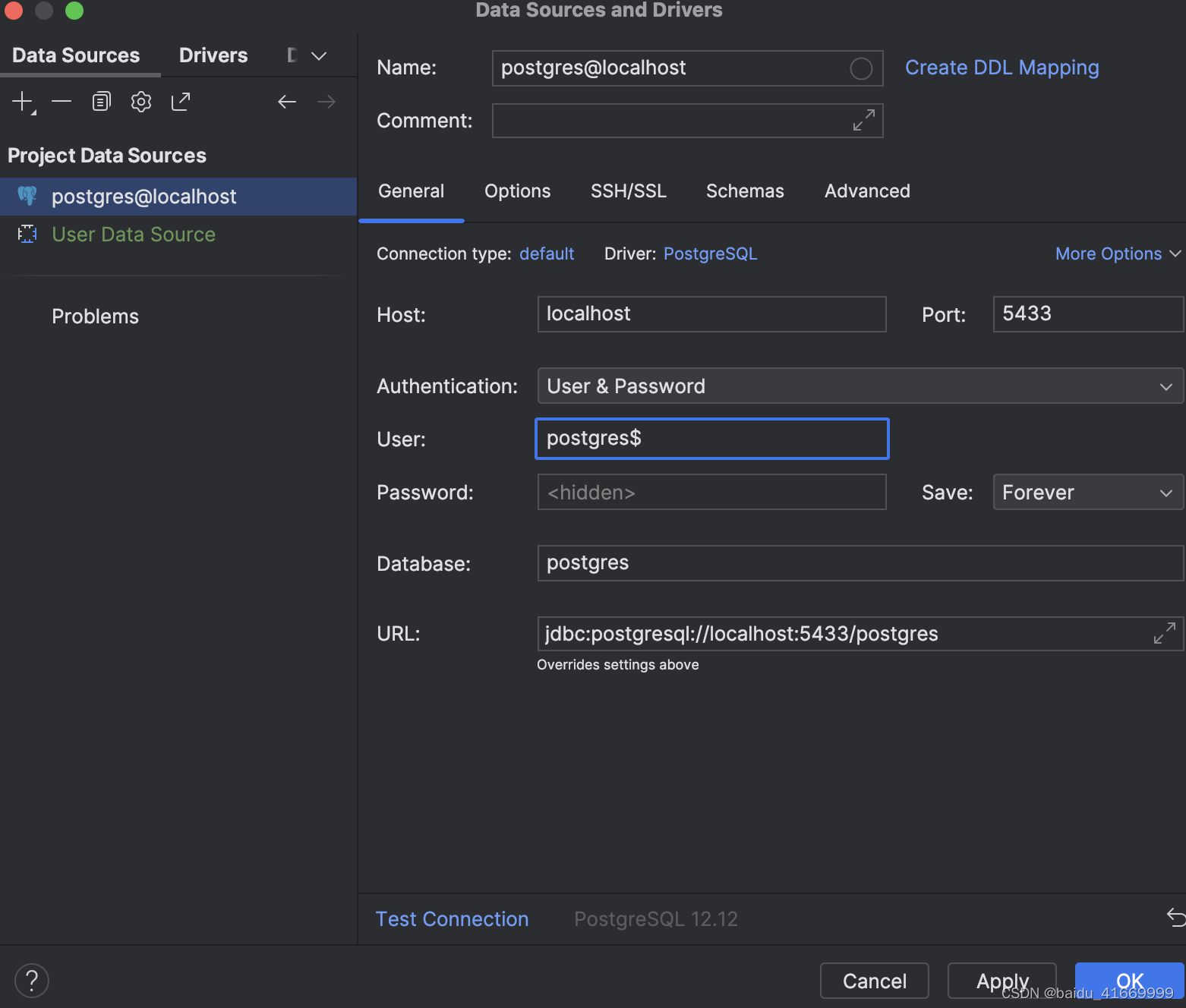
在数据库工具窗口(视图|工具窗口|数据库)中,单击数据源属性图标。
-
在数据源和驱动程序对话框中,单击添加图标 (+) 并选择 PostgreSQL。
-
JPA 是指 Java Persistence API,即 Java 的持久化规范,一开始是作为 JSR-220 的一部分。
JPA 的提出,主要是为了简化 Java EE 和 Java SE 应用开发工作,统一当时的一些不同的 ORM 技术。一般来说,规范只是定义了一套运作的规则,也就是接口,而像我们所熟知的Hibernate 则是 JPA 的一个实现(Provider)。
JPA 定义了什么,大致有:
- ORM 映射元数据,用来将对象与表、字段关联起来
- 操作API,即完成增删改查的一套接口
- JPQL 查询语言,实现一套可移植的面向对象查询表达式
SpringDataJPA 是 SpringFramework 对 JPA 的一套封装,主要呢,还是为了简化数据持久层的开发。
- 提供基础的 CrudRepository 来快速实现增删改查
- 提供一些更灵活的注解,如@Query、@Transaction
基本上,SpringDataJPA 几乎已经成为 Java Web 持久层的必选组件。
3.Spring Boot项目结构
3.1 目录结构
java:Java程序开发目录,其中***Application文件是Spring-boot的入口程序;
resources:资源文件目录,其中static文件夹:存放静态文件,如css,js,图片等资源;templates文件夹:存放Web页面的模板文件;application.properties:项目配置文件,如服务端口、数据库配置等
test:测试程序目录
pom.xml:Maven项目管理文件,用于构建Maven项目的各种配置信息,如项目信息,Java版本信息、项目依赖,插件等等(这里面的依赖都是根据勾选的依赖自动生成的)。
在 application.properties 添加数据库连接配置。
## 数据源配置 (DataSourceAutoConfiguration & DataSourceProperties)
spring.datasource.url=jdbc:postgresql://localhost:...
spring.datasource.username=...
spring.datasource.password=...
# Hibernate 原语
spring.jpa.properties.hibernate.dialect = org.hibernate.dialect.PostgreSQLDialect
# DDL 级别 (create, create-drop, validate, update)
spring.jpa.hibernate.ddl-auto = update
# 指定为 update,这样框架会自动帮我们创建或更新表结构。在jpa中,ddl-auto共分为四种:
spring.jpa.hibernate.ddl-auto = create ----每次启动SpringBoot程序时,没有表会新建表格,表内有数据会清空;
spring.jpa.hibernate.ddl-auto = create-drop ----每次启动SpringBoot程序时,会清空表数据;
spring.jpa.hibernate.ddl-auto = update ---- 每次启动SpringBoot程序时,没有表格会新建表格,表内有数据不会清空,只会更新;
spring.jpa.hibernate.ddl-auto = validate ---- 每次启动SpringBoot程序时,会校验实体类字段与数据库字段的类型是否相同,不同则会报错;
3.2 数据库层(DAO层)
数据库层(DAO层)主要面向数据库底层,负责CRUD等操作,该层包括映射数据库表的实体类,和包含Repository仓库的数据访问接口层。
package payroll;
import java.util.Objects;
import jakarta.persistence.Entity;
import jakarta.persistence.GeneratedValue;
import jakarta.persistence.Id;
//@GeneratedValue(strategy = GenerationType.IDENTITY)
//设定主键增长策略:IDENTITY表示采用数据库原生的自增方式,
//@ManyToOne(fetch = FetchType.LAZY, optional = false)
//@ManyToOne 描述了一个多对一的关系,这里声明了其关联的"作者“实体,
//LAZY 方式指的是当执行属性访问时才真正去数据库查询数据;
//@JoinColumn 在这里配合使用,用于指定其关联的一个外键。
//@JoinColumn(name = "author_id", nullable = false)
@Entity//用于映射数据库表
class Employee {
@Id //表示该属性作为表的主键
private @Id @GeneratedValue Long id; Long 对应MySQL数据库 bigint 类型
@Column(nullable = false, unique = true, length = 20) //列字段,非空且唯一,字符最大长度20
private String name;
@Column(nullable = false, length = 20) //列字段,非空,字符最大长度20
private String role;
public Employee() {}
public Employee(String name, String role) {
this.name = name;
this.role = role;
}
...
}创建数据接口访问层(repository仓库),也叫持久层
基本是继承于 JpaRepository或CrudRepository的接口。
◼JPA 提供了操作数据库的接口。在开发过程中继承和使用这些接口,可简化持久化开发工作。
◼ Spring能够找到自定义接口,并生成代理类,在开发过程中可以不写相关SQL操作,由代理类自动生成。
◼ JPA接口:JpaRepository
package payroll;
import org.springframework.data.jpa.repository.JpaRepository;
interface EmployeeRepository extends JpaRepository<Employee, Long> {
}
// JpaRepository 自动实现了很多内置的CURD方法
// 这些方法以后可直接调用,例如:
// List<T> findAll();
// Optional<T> findById(id);
// User save(user);
// void delete(user);
// void deleteById(id);
// long count();
// boolean existsById(id);
3.3 业务层(Service层)
业务层包括主要面向具体业务,实现具体功能,其在DAO层之上,处理控制器层的需求,实现对应功能。Service 的实现相对简单,仅仅是调用持久层实现数据操作,通过调用DAO层的UserRespository的函数实现具体的业务。
@Service //声明类为服务实现类
public class UserServiceImp implements UserService {
@Qualifier
private EmployeeRepository employeeRepository;
@Override
public List<Employee> getUserList() {
return employeeRepository.findAll(); //直接调用Repository内置的CURD方法
}
@Override
public Employee findUserById(Long id) {
return employeeRepository.findById(id).get();
//findById(id)返回的是Optional类(一个可以为null的容器对象)
//如果Optional容器中存在对象,则调用get()方法返回该对象
}
@Override
public void save(User user) {
userRepository.save(user); //直接调用Repository内置的CURD方法
}
...
}
3.4 控制器层(Web层)
控制器层面向Controller层,其主要通过调用业务层实现的具体业务,Controller层调用服务层业务(Service层)负责业务调度,在这一层,一个方法所体现的是一个可以对外提供的功能。
package payroll;
import java.util.List;
import org.springframework.web.bind.annotation.DeleteMapping;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.PutMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RestController;
@RestController
class EmployeeController {
private final EmployeeRepository repository;
EmployeeController(EmployeeRepository repository) {
this.repository = repository;
}
// Aggregate root
// tag::get-aggregate-root[]
@GetMapping("/employees")
List<Employee> all() {
return repository.findAll();
}
// end::get-aggregate-root[]
@PostMapping("/employees")
Employee newEmployee(@RequestBody Employee newEmployee) {
return repository.save(newEmployee);
}
// Single item
@GetMapping("/employees/{id}")
Employee one(@PathVariable Long id) {
return repository.findById(id)
.orElseThrow(() -> new EmployeeNotFoundException(id));
}
@PutMapping("/employees/{id}")
Employee replaceEmployee(@RequestBody Employee newEmployee, @PathVariable Long id) {
return repository.findById(id)
.map(employee -> {
employee.setName(newEmployee.getName());
employee.setRole(newEmployee.getRole());
return repository.save(employee);
})
.orElseGet(() -> {
newEmployee.setId(id);
return repository.save(newEmployee);
});
}
@DeleteMapping("/employees/{id}")
void deleteEmployee(@PathVariable Long id) {
repository.deleteById(id);
}
}3.5 高级用法
1自定义查询
使用 findByxxx 这样的方法映射已经可以满足大多数的场景,但如果是一些"不确定"的查询条件呢?
我们知道,JPA 定义了一套的API来帮助我们实现灵活的查询,通过EntityManager 可以实现各种灵活的组合查询。那么在 Spring Data JPA 框架中该如何实现呢?
1.首先创建一个自定义查询的接口:
public interface BookRepositoryCustom {
public PageResult<Book> search(String type, String title, boolean hasFav, Pageable pageable);
}
2.接下来让 BookRepository 继承于该接口:
@Repository
public interface BookRepository extends JpaRepository<Book, Long>, BookRepositoryCustom {
...
3.最终是 实现这个自定义接口,通过 AOP 的"魔法",框架会将我们的实现自动嫁接到接口实例上。
具体的实现如下:
public class BookRepositoryImpl implements BookRepositoryCustom {
private final EntityManager em;
@Autowired
public BookRepositoryImpl(JpaContext context) {
this.em = context.getEntityManagerByManagedType(Book.class);
}
@Override
public PageResult<Book> search(String type, String title, boolean hasFav, Pageable pageable) {
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery cq = cb.createQuery();
Root<Book> root = cq.from(Book.class);
List<Predicate> conds = new ArrayList<>();
//按类型检索
if (!StringUtils.isEmpty(type)) {
conds.add(cb.equal(root.get("type").as(String.class
), type));
}
//标题模糊搜索
if (!StringUtils.isEmpty(title)) {
conds.add(cb.like(root.get("title").as(String.class
), "%" + title + "%"));
}
//必须被收藏过
if (hasFav) {
conds.add(cb.gt(root.get("favCount").as(Integer.class
), 0));
}
//count 数量
cq.select(cb.count(root)).where(conds.toArray(new Predicate[0]));
Long count = (Long) em.createQuery(cq).getSingleResult();
if (count <= 0) {
return PageResult.empty();
}
//list 列表
cq.select(root).where(conds.toArray(new Predicate[0]));
//获取排序
List<Order> orders = toOrders(pageable, cb, root);
if (!CollectionUtils.isEmpty(orders)) {
cq.orderBy(orders);
}
TypedQuery<Book> typedQuery = em.createQuery(cq);
//设置分页
typedQuery.setFirstResult(pageable.getOffset());
typedQuery.setMaxResults(pageable.getPageSize());
List<Book> list = typedQuery.getResultList();
return PageResult.of(count, list);
}
private List<Order> toOrders(Pageable pageable, CriteriaBuilder cb, Root<?> root) {
List<Order> orders = new ArrayList<>();
if (pageable.getSort() != null) {
for (Sort.Order o : pageable.getSort()) {
if (o.isAscending()) {
orders.add(cb.asc(root.get(o.getProperty())));
} else {
orders.add(cb.desc(root.get(o.getProperty())));
}
}
}
return orders;
}
}
2连接池
在生产环境中一般需要配置合适的连接池大小,以及超时参数等等。
这些需要通过对数据源(DataSource)进行配置来实现,DataSource也是一个抽象定义,默认情况下SpringBoot 1.x会使用Tomcat的连接池。
以Tomcat的连接池为例,配置如下:
spring.datasource.type=org.apache.tomcat.jdbc.pool.DataSource
# 初始连接数
spring.datasource.tomcat.initial-size=15
# 获取连接最大等待时长(ms)
spring.datasource.tomcat.max-wait=20000
# 最大连接数
spring.datasource.tomcat.max-active=50
# 最大空闲连接
spring.datasource.tomcat.max-idle=20
# 最小空闲连接
spring.datasource.tomcat.min-idle=15
# 是否自动提交事务
spring.datasource.tomcat.default-auto-commit=true
https://tomcat.apache.org/tomcat-8.5-doc/jdbc-pool.html
















 328
328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









