







生物信息学系列博客索引
生物信息学(1)——双序列比对之Needleman-Wunsch(NW)算法详解及C++实现
生物信息学(2)——双序列比对之Smith-Waterman(SW)算法详解
生物信息学(3)——双序列比对之BLAST算法简介
生物信息学(4)——多序列比对之CLUSTAL算法详解及C++实现
生物信息学(5)——基于CUDA的多序列比对并行算法的设计与代码实现
项目gitee地址,内附源码、论文等文档信息
1. BLAST算法简介
动态规划算法如生物信息学(1)与生物信息学(2)两篇提到的NW与SW算法肯定能得到最优解(最优分为全局最优与局部最优),但是要计算一个庞大的得分矩阵。随着序列的增长,复杂度会平方级别的升高。因此,时间开销和空间开销就会很大。动态规划需要计算出(seq1+1)×(seq2+1)大小的矩阵,但绝大多数数字其实在回溯时是没有用到的,如果能够只计算最终回溯路径附近的一些单元的话,与整个矩阵全部算完,效果近似。
从一个局部来启发,找到一个方法贴近回溯路径,即找到大概会在什么地方匹配,然后顺着这个核心往两边拓展序列,这样比对就可以高效的进行,这就是BLAST算法的实现思想。
Blast算法的全称是(Basic Local Alignment Search Tool),中文叫做基本局部相似性比对搜索工具,在1990年由Altschul等人提出,其并不确保能找到最优解,但尽力在更短时间内找到足够好的解,算法有Seeding、Matching、Extending三个步骤。
2. BLAST三个步骤
(1) Seeding
需要把比对的序列(Query Sequence)按照一定长度拆分成多个连续’seed words’,通常来说对于蛋白质序列是以三个氨基酸为一个 seed word, DNA 碱基序 列以 11 个长度为一个 seed word,由 Query Sequence 转换为 seed word 过程如图 2-9。seed 的长度越小,最终的比对准确率就越高,所需要的时间也越长。例如 对于一个蛋白质序列 PQFEFG,设定 seed word 长度为 3,那么就可以依次形成 四个 seed word,分别为 PQF、QFE、FEF、EFG。

(2) Matching
将目标序列与参考序列进行索引,找到 seed 相同的地方,得到每个 seed word 在参考比对序列对应的位置,即找到本序列与目标数据库序列相似部分。
(3) Extending
拓展目标序列,拓展利用 SW 或者 NW 算法向两边延伸,拓展 seed word 长 度,直到得分低于设定阀值,获取到最长的序列,即为目标结果序列。拓展过程 如下图。有点抽象,不过大概意思差不多。
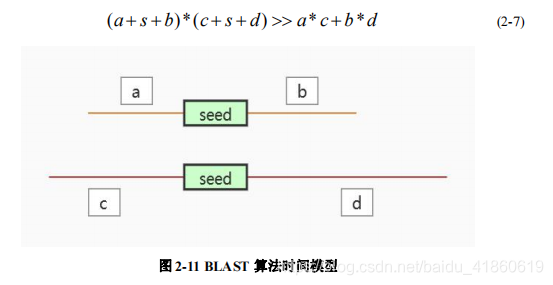
Blast 算法通过 Seeding-and-Extending 策略,如公式(2-7)与图 2-11 所示,能 极大的减小了时空复杂度,提高了算法运行的时间,是双序列比对效果最好的算 法之一。
3. 双序列比对算法总结
3.1 Needleman-Wunsch算法
创新的将动态规划的思想引入到生物信息学中,通过回溯特殊的得分矩阵,能有效的将两个序列进行全局比对,但是有巨大的时空复杂度。
3.2 Smith-Waterman算法
化简了Needleman-Wunsch算法得分矩阵的求得方式,杜绝负值的出现,简化计算过程,且通过回溯,能获取到序列比对的局部最优解。
3.3 BLAST算法
基于启发式思想的算法,通过通过Seeding-and-Extending策略,能极大的减小了时空复杂度,提高了算法运行的时间,是双序列比对效果最好的算法之一。
4. 奇怪的内容
BLAST其实是一个双序列比对工具,一直以算法称他,我解释为,此工具提供了一种解决问题的思路与方法。
BLAST主要用于对一条序列进行同源性分析,即测试这条序列应该是个什么序列,主要是将未知序列通过双序列比对,与数据库已经存在的大量序列进行两两比对,分析相似度,得出结论。
所以一条序列与很多条序列两两比对,依旧属于双序列比对的范畴。而下一篇要介绍的多序列比对算法CLUSTAL是多条序列一起比对,目的是观察整个基因家族的进化方向与遗传规律。
总结
如果有什么问题,请私信联系我或者在评论区留言
码字不易,若有帮助,给个关注和赞呗




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











