







在日常的开发过程中,避免不了对数据库的读写操作,这里写一下REPLACE INTO、INSERT INTO和INSERT IGNORE INTO的用法。(还没有写完,先去吃饭 等我回来整理。。。)
我们新建一张user表,字段id、name,id是自增的主键,name添加唯一索引
一、INSERT INTO 用法
这个语句大家一定不太陌生,就是对表插入一条数据,注意:唯一索引数据和 ID 不能重复,要不然就会报: Duplicate entry 'XXX' for key 'XXXX'。
二、INSERT IGNORE INTO
这个语句就可以避免上面出现的唯一索引重复,是不会报主键重复的问题。执行过程:如果数据重复,就忽略,否则就会插入。
但是我们的问题是什么情况下是数据重复?忽略操作,什么情况下才会插入?
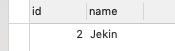
现在数据库有一条数据。1. 我们先执行ID+Name的语句:

我们看出如果Id+Name是完全一样的,就会完全忽略本次操作。
2.执行只有Id的sql

3.只有Name的sql

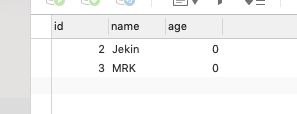
我们看的出Id决定了数据是否是同一条数据。但是在一张表里没有主键的时候,唯一索引就决定了数据是否更新
二、REPLACE INTO用法
根据唯一索引的唯一性,如果存在该唯一索引,则执行更新操作,如果不存在则插入。
执行的过程:删除老数据,新增一条新的数据。所以这个操作就非常的危险,Id更新前后是发生的。
PS:但是如果插入的数据中同时包含了ID+唯一索引?我们知道ID通常是特殊的唯一索引

新建一张User表,id是自增的主键,name建了唯一索引。
我们新建一条数据:INSERT INTO user(name) values('TOM');
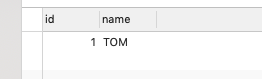
OK ,数据库一条数据。
现在我们使用REPLACE INTO 语句试一下:REPLACE INTO user(id,name) values(1,'Jekin');
Affected rows: 2
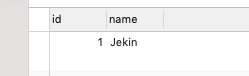
OK ,ID没有发生变化,name已经更新成Jekin。
接下来我们不加Id执行一下!
SQL: REPLACE INTO user(name) values('Jekin'); Message:Affected rows: 2, Time: 0.007000s
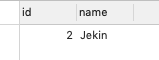
ID现在变成2了,所以在日常的开发中,我们可以通过REPLACE INTO语句快速的实现saveOrUpdate操作,但是应该根据实际的情况,考虑到ID的变化。
说到saveOrUpdate操作 还有一种写法,insert into table(...) values(...) ON DUPLICATE KEY UPDATE name = values(name)















 791
791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









