







一、简介
有了上次爬取豆瓣短评的实战,我们爬取猫眼就有经验了,
环境:win10,notebook,python3.6,
整体步骤也是分析网页,爬取策略,代码编写,本地保存
二、网页分析
我不是药神猫眼主页:
http://maoyan.com/films/1200486
网页模式只能看数条评论,我们使用手机模式
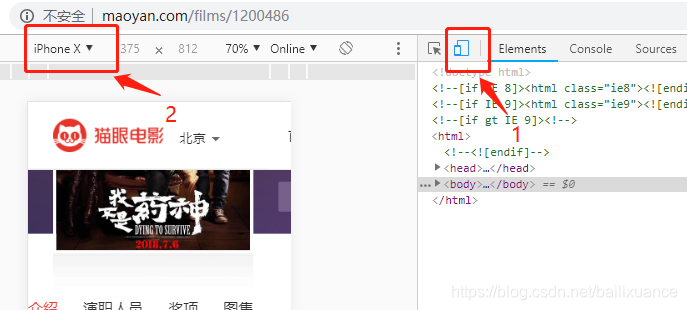
刷新网页,往下拉就是评论
4就是我们要找的url,但评论是动态更新的,
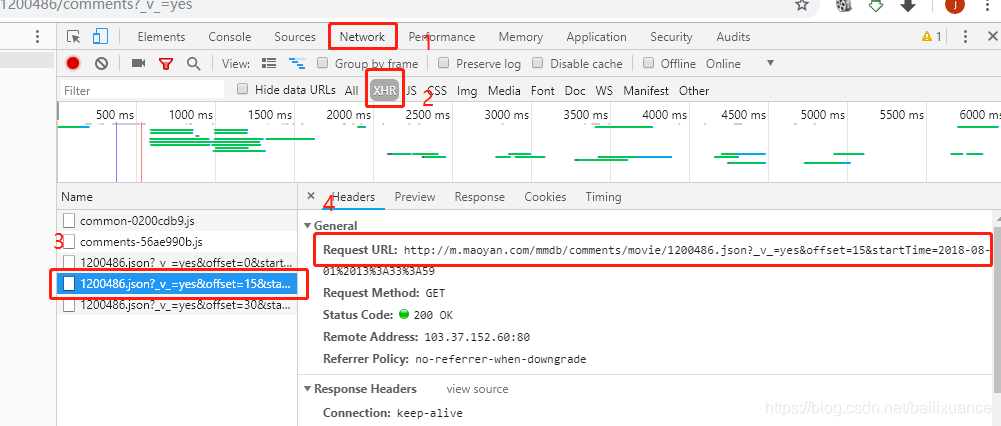
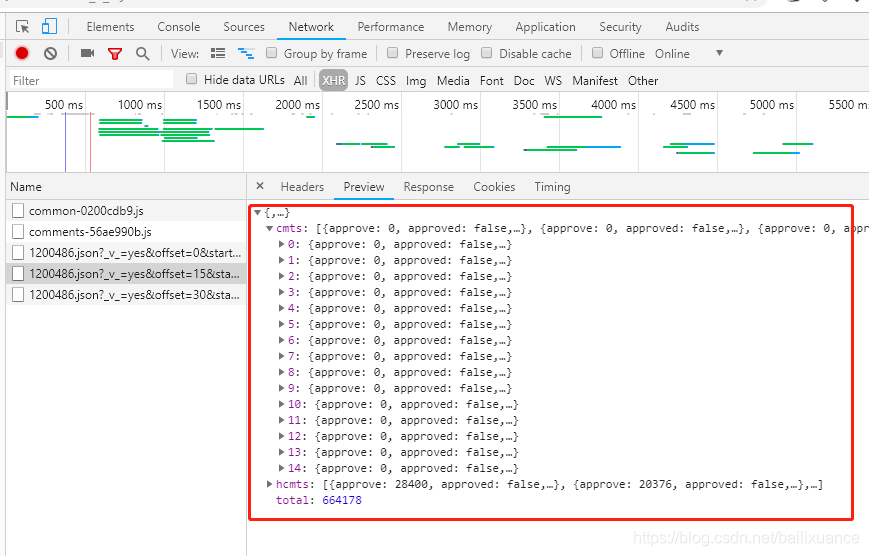
内容存放在cmts的字典中,因此需要使用json来解析
三,代码
需要的包:
import requests
import json
import csv
import time爬虫函数:
def getContent(requrl,headers,page):
resp = requests.get(requrl,headers=headers)
# 这里是content属性,不是text,
html_data = resp.content
if html_data is not None:
html_data.decode('utf-8')
jsonobj = json.loads(html_data)
if 'cmts' in jsonobj:
print("len(jsonobj['cmts']): ",len(jsonobj['cmts']))
# 获取评论信息
data_cmts = jsonobj['cmts']
for data_cmt in data_cmts:
# ID,性别,评论星级,点赞数,回复数,城市,日期,评论内容
datalist = []
# ID ,
if 'nickName' in data_cmt.keys():
datalist.append(data_cmt['nickName'])
else:
datalist.append('None')
# 性别
if 'gender' in data_cmt.keys():
datalist.append(data_cmt['gender'])
else:
datalist.append('None')
# 评论星级
if 'score' in data_cmt.keys():
datalist.append(data_cmt['score'])
else:
datalist.append('None')
# 点赞数
if 'approve' in data_cmt.keys():
datalist.append(data_cmt['approve'])
else:
datalist.append('None')
# 回复数
if 'reply' in data_cmt.keys():
datalist.append(data_cmt['reply'])
else:
datalist.append('None')
# 城市
if 'cityName' in data_cmt.keys():
datalist.append(data_cmt['cityName'])
else:
datalist.append('None')
# 日期
if 'time' in data_cmt.keys():
datalist.append(data_cmt['time'])
else:
datalist.append('None')
# 评论内容
if 'content' in data_cmt.keys():
datalist.append(data_cmt['content'])
else:
datalist.append('None')
with open('yaoshen.csv','a+',encoding='utf-8',newline='') as f:
writer = csv.writer(f)
writer.writerow(datalist)
else:
print("cmts不存在。。。")
else:
print("该页没有信息。。。")
return
调度函数:
def main():
headers = {
'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'
}
cookie = {
'cookie':'bid=7e5ajEcxNaY; __yadk_uid=a1NLl8PpDFtZBEzAVSe2HB6FU7jKF5k7; douban-fav-remind=1; gr_user_id=b29e78b2-99b3-4441-ba7c-c5473a7e2421; _vwo_uuid_v2=D47C02F69367694FF6C8B997080391FEB|953c360d550817fbfc37a453908dbe79; viewed="30179607_26638586"; ll="108288"; __utmc=30149280; __utmc=223695111; ps=y; ue="2371033494@qq.com"; douban-profile-remind=1; push_noty_num=0; push_doumail_num=0; __utmv=30149280.7521; __lfcc=1; __utmz=30149280.1543733441.18.11.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmz=223695111.1543733441.14.7.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1543739850%2C%22https%3A%2F%2Faccounts.douban.com%2Flogin%3Falias%3D2371033494%2540qq.com%26redir%3Dhttps%253A%252F%252Fmovie.douban.com%252Fsubject%252F26363254%252Fcomments%253Fstart%253D0%2526limit%253D20%2526sort%253Dnew_score%2526status%253DP%26source%3Dmovie%26error%3D1011%22%5D; _pk_ses.100001.4cf6=*; ap_v=0,6.0; __utma=30149280.866397823.1538479903.1543733441.1543739852.19; __utma=223695111.336122627.1538479903.1543733441.1543739852.15; __utmb=223695111.0.10.1543739852; __utmb=30149280.2.10.1543739852; __lncc_www.douban.com=1; ck=Bnh1; _pk_id.100001.4cf6=4bc8256252464f91.1538479903.13.1543742003.1543736841.; dbcl2="75219602:j+VXQyAhFDQ"'
}
for i in range(0,10000,15):
print("爬取第{0}页......".format(int(i)))
requrl = "http://m.maoyan.com/mmdb/comments/movie/1200486.json?_v_=yes&offset=" + str(i) + "&startTime=2018-08-01%2022%3A30%3A34'"
getContent(requrl,headers,i)
time.sleep(3)
print("爬到所有数据,爬虫结束")
main()四、结果分析
能爬到1000条评论,豆瓣500,不知道为什么有的老乱入,以后再找原因

















 1287
1287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









