






 本文深入介绍了NIPS2012的AlexNet模型,探讨了其在ImageNet数据集上取得的显著成果。文章覆盖了AlexNet的设计原理,包括ReLU激活函数、多GPU训练策略、数据增强方法以及Dropout技术等关键组件。
本文深入介绍了NIPS2012的AlexNet模型,探讨了其在ImageNet数据集上取得的显著成果。文章覆盖了AlexNet的设计原理,包括ReLU激活函数、多GPU训练策略、数据增强方法以及Dropout技术等关键组件。
这篇文章非常经典,NIPS 2012的文章,讲了一些基础知识,介绍了Alex-net网络,使用深度神经网络在ImageNet上进行分类。
Abstract
本文训练了一个深度卷积神经网络,将ILSVRC-2010中1.2million的高分辨率图像数据分为1000类。测试结果,Top-1和Top-5的错误率分别为37.5%和17%,优于当时最优的水平。该神经网络包含60M参数和650K神经元,用5个卷积层(其中某些层与亚采样层连接)、三个全连接层(包括一个1Kw类的输出层)。为使训练更快,文章采用非饱和神经元,并利用了一个高效的GPU应用进行卷积运算。在全连接层中,为避免过拟合,文章采用了一种叫做“dropout”的方法。后来作者利用该种模型的变体参与了ILSVRC-2012(ImageNet Large Scale Visual Recognition Challenge)比赛,以Top-5错误率15.3%遥遥领先亚军的26.2%。
RELU 非线性特征
不用simgoid和tanh作为激活函数,而用ReLU作为激活函数的原因是:加速收敛。非饱和 比饱和激活函数在梯度下降时训练时间短,采用ReLu可以加快训练的时间。
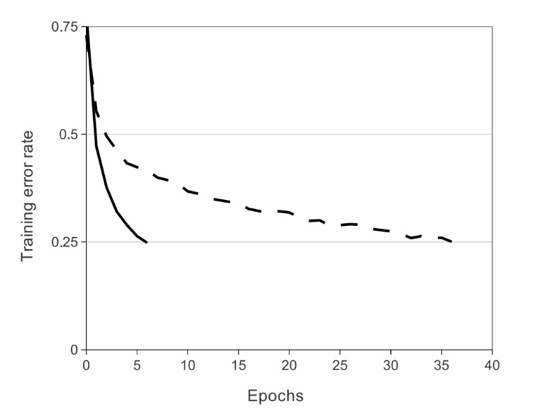
传统的输出激活函数一般都是双曲正切函数或者sigmod函数,在梯度下降训练时间上,饱和的非线性特性比非饱和非线性特性f (x) = max(0,x)更慢。于是文中用了Hinton 2010 ICML中论文中提到的修正线性单元(ReLU)。CNNs在利用ReLU进行训练几次之后明显比传统的tanh更快。图2中表示的在CIFAR-10数据集(注:CIFAR-10 数据集包括60000 32×32 彩图,共10 类, 每类6000-50000训练集,10000测试集)上使用4个卷积层将错误率降低到25%所需要的迭代次数。图中表明,在该规模下,传统的饱和神经元模型无法将其收敛。
Training on Multiple GPUs
由于单GTX 580只有3GB的内存,从而限制了网络的大小,所以文章使用了两个GPU。现在的GPU都能很好的进行相互之间的读写,不需要经过中介。文章在每个GPU上放1/2的神经元,但只有某些层才能进行GPU间的通信。在交叉验证时,选择连接的模式是一个问题,而这个也恰好允许通过精确的调整通信的数量使计算数量变成一个良好的值。
Local Response Normalization
本质上,LRN层也是为了防止激活函数的饱和的。
RELUs拥有很好的性能,它不需要将输入的数据标准化,就可以防止激活函数的饱和。在ReLU中,只要有一些训练数据能够产生输入,则神经元就能得到训练。然而,文章还发现了下面的局部标准化调度帮助泛化性能。
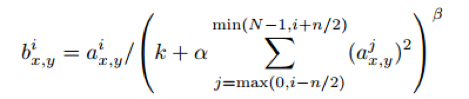
(我理解为通过正则化可以使得属兔的激活函数,更加靠近中间的数值,也就是获得比较大的导数。看了一些解析和博客,一些人认为LRN层的作用不大,同RELU重复,对性能提升也不是很大。)作者在文章中介绍说,LRN可以提高网络的泛化能力,错误率降低了两个点,从13%降到了11%。
Overlapping Pooling
CNNs的pooling层,是做降采样的,只会整合在同一kernel map的响铃层的输出。CNNs的Max-Pooling层(即LeCun的下采样层,只是这里使用的降采样,即将每个Kernel的最大值作为此次降采样的值,暂称为降采样层)是不会从上一层重复采样的。但是如果将上一层看做一个网格,每个网格相同边的距离为s,而每一次进行降采样将从网格中心为中心,采样z*z个像素。如果s=z,则与传统方法相同,而如果s
Overall Architecture
这是比较经典的CNN网络,网络包括八层(不包含最左端的输入层)。前五层是卷积层,剩下的三层是全连接的。全连接层中,有4096个神经元,即可以提取出4096维的特征。最后一个全连接层是输出层,包含1000种路径,即1000个分类标签。本网络将多项式线性回归的结果最大化,也就是将训练集预测正确的标签的对数概率最大化。(由图可知,共使用了两个GPU)
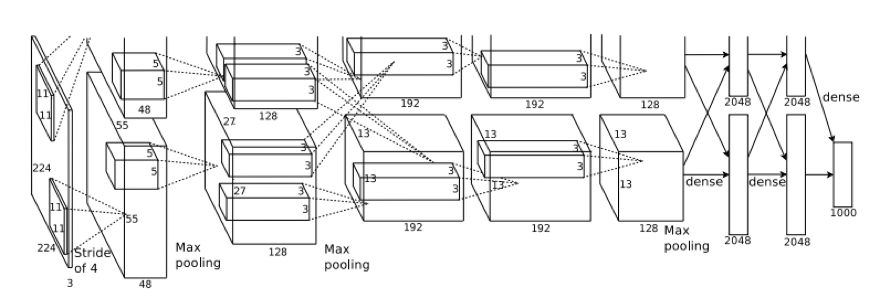
第二、四、五个卷积层只与上层在同一个GPU上的Kernel Map(下文称特征图)连接,第三个卷积层与第二个卷积层的所有特征图连接。全连接层的神经元与上一层的所有神经元连接(即改进二)。响应标准化层在第一和第二个卷积层之后(改进三),降采样层在响应标准化层和第五个卷积层之后(改进四)。而ReLU非线性公式在每个卷积层和全连接层都有应用(改进一)。
Data Augementation
数据加强使用了两种方法,方法一:对256*256的图片进行随机裁剪到224*224,然后进行水平翻转,那么相当与将样本倍增到((256-224)^2)*2=2048。测试时候,对左上、右上、左下、右下、中间做了5次crop,然后翻转,共10个crop,之后对结果求平均。方法二:对RGB空间做PCA姜维,然后对主成分做一个(0, 0.1)的高斯扰动,错误率下降了百分一。
Dropout
在前两个全连接层加入dropout之后,能防止过拟合。具体做法是:将将某些层隐藏,按照50%的概率输出0。这些隐藏的神经元不会参加CNN的forward过程,也不会参加back propagation过程。所以每次有输入时,该网络采样一个随机结构,但所有不同网络结构的相同层的权值相等。因为每个神经元不能依赖于其他神经元的存在,该模型也减少了神经元的相互作用,迫使神经元与其他神经元共同学习更多更有用的特征。
Results
在ILSVRC-2010的测试结果如表1,最终Top-1和Top-5的错误率分别为37.5%和17.0%。而当时比赛最好成绩为47.1%和28.2%,而之后文章得到的最好结果45.7%和25.7%。五个模型平均出来后,top1 38.1%和top5 16.4%。
思考与讨论
- 作者重新学习了整个网络,分析了网络每一层的输入输出,画出了网络模型。
- 这是比较经典的CNN模型,我们使用这个模型提取出了全连接层的特征,有4096维,是否可以将其降维,用于检索?
- 实验中没有使用任何无监督的学习,能够加入无监督或者半监督学习?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









