








摘要:
- 主要工作1 收集了一个很大的数据集并且有丰富的标签信息(compcar)
- 主要工作2 基于以上的数据集做的(car model classification、car model verification、 attribute prediction) 主要围绕细粒度分类和验证,都是基于CNN的方法
CompCar数据集
数据集来源Web-Nature和Surveillance-nature,即从网上和监控上,网上的数据集包括163个car makes,1716个car model 几乎涵盖近10年的商业car model,并且有超过136727个entire car27618个car parts,并且这些图像大部分都有attributes和view points的标签,监控图像有44481个主要是来自卡口的前脸照相,同样卡口车辆也标注有bounding box model color这些标签。
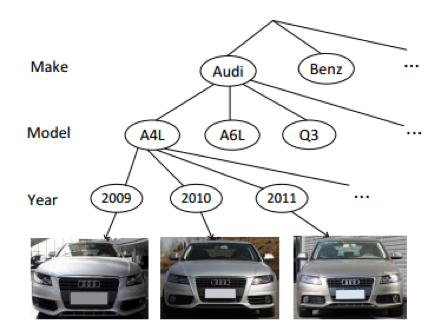
1. Car Hierarchy ,包括了3层,车辆的品牌,模型和出场时间。树形结构如下图所示:
2.Car Attributes 5种属性maximum speed(最快时速) displacement(排量) number of doors(车门数) number of seats (车座数) type of car(车类别)。包括了12种车型,包括MPV, SUV, hatchback, sedan, minibus, fastback, estate, pickup, sports,crossover, convertible, and hardtop convertible,如下图所示。

3.Viewpoints 共5个视角:front(正面) rear(后面) side(侧面)front-side(前侧)rear-side (尾侧) AllView
4.Car Parts 车灯进气口尾灯 仪表盘方向盘等等共8种parts
实验
一共设计了三个实验,car model classification、car model verification、 attribute prediction(即精细车辆分类,属性预测和车辆认证)。作者从CompCars选择了78,126张图片,并将数据库分成了三部分,PartI包含431个车型共30,955张整车图像及20,349张车辆局部图像。PartII包含111个车型共4,454张图像。PartIII包含1,145个车型共22,236张图像。车辆分类使用PartI,属性预测使用PartI训练,PartII测试,车辆认证使用PartIII。训练使用Overfeat模型,ImageNet预训练,使用车辆图像微调。
实验1 Fine-Grained Classification 在这个细粒度分类中,作者将同一款车在不同年限上的model是看成一个类别的,因此他把总共是实现了431个car model 的分类。分类时,一共使用了5个视角,“front (F)”, “rear (R)”, “side (S)”, “front-side (FS)”, “rearside (RS)”, and “All-View”,使用FS和RS效果较好,使用全部的视角,效果最好。

Cars parts模型的扩展性能较好,在网络图像上训练的模型用于监控图像获取的数据获得较好的识别结果。对于车辆局部图像,分别使用8个部位的车辆图像对CNN进行训练,实验结果显示“尾灯”的效果最好,使用投票方法对8个部位的识别效果进行综合评判,也得到了比较好的结果,如下表。

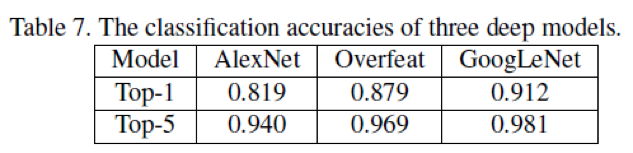
模型同AlexNet,GoogleNet车型识别结果的对比,如下表所示:
车辆属性预测 Attribute Prediction
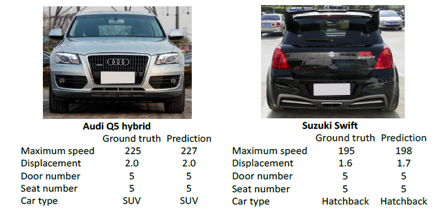
对最大速度,排量,车门数目,座位数目以及车型进行预测,其中最大速度,排量是连续值,下图显示了几张图片的预测结果。
车辆认证
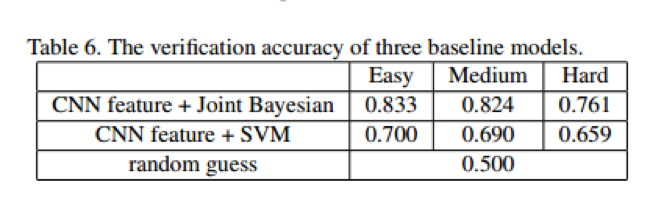
作者根据人脸的验证流程做车脸验证。使用实验1中的分类模型提取特征,之后在数据集二上使用Joint Bayesian训练认证模型。最后使用数据集三进行测试。测试数据分为了易,中,难三个级别,每部分包含2000对图像,其中1000对正样本,1000对负样本。
Joint Bayesian在人脸认证上首先应用,将特征x公式化为两个高斯变量之和,即
x=μ+ε
μ是身份信息,ε是类内方差。Joint Bayesian估计两物体的联合概率,即P(x1,x2|HI),P(x1,x2|HE),两个概率的方差服从高斯分布。测试时,使用估计似然比
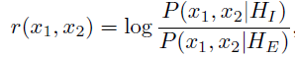
第二个方法是CNN+SVM,SVM使用图像对的特征作为输入,是一个二值分类器。1表示匹配图像对,0表示未匹配。100,000图像对训练。下图显示了使用CNN+Joint Bayesian认证的结果性能,结果显示CNN+Bayes性能更好
















 6126
6126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









