







python学习笔记—udf的使用
--------仅用于个人学习知识整理和sas/R语言/python代码整理
在spark sql中,可以使用udf(用户自定义函数)来把python函数转化为udf进行运算,下面直接上例子们吧!
- 直接运用在列中
from pyspark.sql.functions import udf
###python函数 定义
def sum_fuc(t,tt):
return t*tt
###udf 注册
spark.udf.register("sum_fuc_udf", sum_fuc)
sum_fuc_udf = udf(sum_fuc)
###使用udf
salesbyday=spark.read.parquet("/salesbyday/")\
.select('customer_id','price','quantity')\
.withColumn('sales',sum_fuc_udf('quantity','price'))
其实计算了quantity*price的数值

这里可以看到,udf默认返回一个string格式的值,其实是udf函数默认定义了StringType的原因,如果要修改,在udf中定义returnType为LongType


from pyspark.sql.functions import udf
from pyspark.sql.types import LongType
###python函数 定义
def sum_fuc(t,tt):
return t*tt
###udf 注册
spark.udf.register("sum_fuc_udf", sum_fuc,LongType())
sum_fuc_udf = udf(sum_fuc,LongType())
###使用udf
salesbyday=spark.read.parquet("/salesbyday/")\
.select('customer_id','price','quantity')\
.withColumn('sales',sum_fuc_udf('quantity','price'))
可以看到,这里返回值的类型变成了bigint

P.S. 关于返回值 有一篇写的很详细的文章供参考:
https://www.cnblogs.com/yurunmiao/p/4931095.html
- 运用在聚合函数中
from pyspark.sql.functions import udf
from pyspark.sql.types import LongType
###python函数 定义
def sum_fuc(t,tt):
return t*tt
###udf 注册
spark.udf.register("sum_fuc_udf", sum_fuc,LongType())
sum_fuc_udf = udf(sum_fuc,LongType())
###使用udf
salesbyday=spark.read.parquet("/salesbyday/")\
.select('customer_id','price','quantity')\
.withColumn('sales',sum_fuc_udf('quantity','price'))
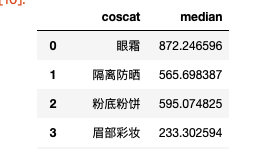
可以计算分组中位数
注释语法的使用详见以下链接:
https://github.com/icexelloss/spark/blob/328b2c4e09502a66939d47d6967ceea7ceab6c8c/python/pyspark/sql/functions.py#L2605-L2627
3.例子
有一个需求是,在一张datatable中的一列,每行都截取字符串,保留字符长度为32位(其中中文为两字符,英文和数值长度为1字符)
这个时候用udf可以完成对列的操作
###udf 通过转换编码 截取32位
from pyspark.sql.functions import pandas_udf, PandasUDFType
from pyspark.sql import Window
###这里try except是因为中文两字符,如果截取到了一个中文的一半字符,会报错,但是其实这个时候截取n-1就可以
def encoding_change(a):
n=32
try :
return str(a.encode('GBK')[:n],encoding = 'gbk')
except :
return str(a.encode('GBK')[:n-1],encoding = 'gbk')
df.udf.register("encoding_change_udf", encoding_change)
encoding_change_udf = udf(encoding_change)
change_name=data\
.withColumn('name',encoding_change_udf(col('name_raw')))















 1802
1802











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









