







本文翻译并修订自Bastian Molkenthin的文章《Understanding and implementing CRC (Cyclic Redundancy Check) calculation》之部分内容
目录
1. 前言与概述
此文是本人终于找到时间探究CRC后得到的结果。在阅读了维基及其他一些文章之后,我始终感觉未能深入理解CRC。因此我决定写下这篇文章,试图覆盖所有我觉得比较困难的部分。这实际上也是我自己逐步去探索CRC的过程。请注意,本文不是一份关于CRC的综合性完全手册,并不会解释所有细节。本文可以作为一份补充性的、以实践为导向的应用笔记,用来与网上林林总总的说明进行对照参考。
概述:
首先,讨论CRC的总体构思及其功能。
其次,提供一些手算的示例,用以熟悉CRC的计算过程。
然后,基于以上的观察结果,从简易的方法过渡到更高效的算法,一步一步地展示CRC计算如何实现。
此时我们的重点在于对照手算过程,找到计算代码的关键点。使用的范例为一个CRC-8多项式。
最后,将获取的结论扩展到CRC-16。
2. CRC介绍
CRC (Cyclic Redundancy Check) 是一种用于检测数据是否存在不一致问题的校验和算法,例如数据传输过程中发生的位错误。通过CRC计算得到的校验和被附加到数据后面,以便接收者检查数据中是否存在错误。参考 [1] 了解CRC的简单介绍,参考 [4] 了解CRC更详尽一些的介绍。
CRC是基于除法的。实际输入的数据被解析为一个长的二进制比特流(被除数),除以一个固定的二进制数(除数)。这个除法运算所得的余数即为校验和的值。
看似简单,实际过程则稍显复杂。这些二进制数(除数与被除数)并不像整数那样计算,而是当作一个二进制多项式来对待。每个二进制数的每个比特位,作为该多项式的系数。
举个例子:
输入数据为
0x25 = 0010 0101
表示为
0*x7 + 0*x6 + 1*x5 + 0*x4 + 0*x3 + 1*x2 + 0*x1 + 1*x0
多项式除法与整数除法不同。此处并不赘言,只说明CRC所使用的算术是基于 XOR( 按位异或) 操作的。
- 被除数是完整的输入数据(解析为二进制位流)。
- 除数也称为生成多项式,是被所选用的CRC算法静态定义的一个多项式。CRC-n表示计算中使用一个固定的 (n+1) 位生成多项式。
- CRC校验和的值即为被除数 % 除数(求余操作所得到的余数)。
异或真值表
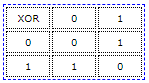
对于手动计算而言,在进行CRC计算(多项式除法)之前,n个bit 0被补充到输入数据后面。让我们进行一次计算示例。
示例1:
输入数据 0xC2 = b 11000010 \color{red}{11000010} 11000010,生成多项式(除数)我们使用 0x11D = b 100011101 \color{blue}{100011101} 100011101。
除数有9个bit(因此它是一个CRC-8多项式),所以先补充8个bit'0'到输入数据后面。
将除数最前面的'1' 与被除数的第一个 '1' 对齐,然后像在学校那样一步一步的做除法,对每一个bit执行XOR操作。
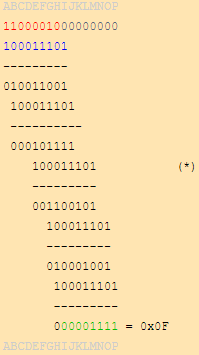
实际得到的CRC值即为0x0F(除法运算最后的余数)。
有用的结论:
- 每步操作中,除数最前面的
'1'永远和被除数的第一个'1'对齐。这意味着除数在每一步的操作中向右移动的位数并不仅限于1,有时会移动好几位(比如标星号* 的那一行)。(编者注:相当于每次右移1位的步骤重复进行好几次,这对于后面理解代码有帮助) - 计算重复进行,直到除数将实际输入数据的每一个bit(不包括实际数据后面追加的字节)都 “消零” 之后才停止下来。此处,实际数据是从第A列到第H列。到最后一步时,第H列和它之前的所有列都已经是
'0'了(编者注:高字节的0无意义所以没有全部写出来),所以计算停止。 - 余数(=CRC的值)即最后剩下的,处在补充的bit 0位置下方的值(第I列到第P列的值)。因为我们补充了n个bit,所以实际的CRC也是n个bit。
- 每一步操作中,只有余数是有意义的,除法所得的商我们根本不去管它。
2.1 CRC 校验
余数就是CRC的值,它将作为CRC数据随输入数据(实际数据)一起被发送给接收者。接收者可以计算接收数据(编者注:这里所说的接收数据指实际数据,不包括随实际数据一起发送的CRC数据)的CRC值,并拿这个值与接收数据中已经写明的CRC数据进行比较。
或者,更常用的办法是,接收者直接对接受到的全部数据(实际数据 + CRC数据)进行CRC计算,如果计算得到的CRC值为0,那就表示数据传送过程没有发生位错误。
让我们用举例来说明校验过程。
示例2:
发送数据(实际数据 + CRC)为b 11000010 \color{red}{11000010} 11000010 00001111 \color{green}{00001111} 00001111(编者注:这里继续使用示例1中所用的输入数据及CRC值),注意我们的数据中已经使用了8位的CRC,所以计算得到的CRC也是8位的。
生成多项式是被所选用的CRC算法静态定义的,因此接收者是事先知道的(编者注:这里继续使用示例1中所用的生成多项式)。

3. CRC移位寄存器的概念
我们已经看过了如何手动计算CRC校验和的值了,但是怎么用机器实现呢?
输入数据流通常都很长(位数超过1个bit),所以不可能像“输入数据%生成多项式”那样简单地做除法求余。计算必须分步进行,这就引出了移位寄存器的概念。
移位寄存器具有固定的宽度。
它能够将其存储的内容移动1位,即:向左边或右边移出一个bit,然后将一个新的bit移入到空出的位置上。
移位完成后,原MSB(最高有效位)被弹出寄存器,原MSB-1位置上的bit移动1位成为新的MSB,原MSB-2移动1位成为新的MSB-1,后面的bit同样如此这般操作。
最后,原LSB(最低有效位)的位置被空出来了,这样输入数据流的下一个bit便可以移入到寄存器内部了。
---- ---- ---- ---- ---- ----
<- | | | | | … | | | <-- (将输入数据的bit依次移入)
---- ---- ---- ---- ---- ----
使用移位寄存器进行CRC计算的大致过程如下:
- 将寄存器初始化为0。
- 将输入数据流的1个bit移入寄存器。若寄存器弹出的原MSB是一个’1’,则将寄存器的内容
(编者注:原MSB仍当作寄存器的内容一起参与计算)与生成多项式进行XOR操作(编者注:然后用所得结果去更新寄存器的内容)。 - 若输入数据流的所有bit都被处理过了,那么寄存器此时所包含的内容即为CRC值。
我们继续使用上面例子中的数据,将整个计算过程变得可视化。
CRC-8 移位寄存器示例:
输入数据 = 0xC2 = b11000010 (末尾补充8个bit 0后为b1100001000000000),生成多项式 = b100011101。
-
CRC-8 寄存器初始化为0。
---- ---- ---- ---- ---- ----
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | <-- b1100001000000000
---- ---- ---- ---- ---- ---- -
寄存器左移1位。原MSB是0,故不做任何操作,仅将输入数据的1个bit移入寄存器。
---- ---- ---- ---- ---- ----
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | <-- b100001000000000
---- ---- ---- ---- ---- ---- -
重复这些步骤直到MSB是1,此时的状态是下面这样:
---- ---- ---- ---- ---- ----
| 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | <-- b00000000
---- ---- ---- ---- ---- ---- -
寄存器左移1位,MSB(1)弹出。
---- ---- ---- ---- ---- ----
1 <- | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | <-- b0000000
---- ---- ---- ---- ---- ----
因为弹出的原MSB是1,故将寄存器的内容(连同已被弹出的原MSB)与生成多项式进行XOR操作: b110000100XORb100011101 = b010011001 = 0x99。丢弃MSB,新的CRC寄存器 = b10011001。此时的状态如下:
---- ---- ---- ---- ---- ----
| 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | <-- b0000000
---- ---- ---- ---- ---- ---- -
寄存器左移1位,MSB(1)弹出。同上所述, b100110010
XORb100011101 = b000101111 = 0x2F。
---- ---- ---- ---- ---- ----
| 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | <-- b000000
---- ---- ---- ---- ---- ---- -
寄存器左移,直到MSB的值为1。
---- ---- ---- ---- ---- ----
| 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | <-- b0000
---- ---- ---- ---- ---- ---- -
寄存器左移1位,MSB(1)弹出。同上所述, b101111000
XORb100011101 = b00110
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 85
85

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









