







今天在处理电脑文件时,发现去年自己部署及训练的过程记录,赶紧上传~
###源码:https://github.com/haotian-liu/yolact_edge
一、环境配置
1.建立一个python3下的环境,我建的是python3.8
2.安装1.6.0版本的pytorch和torchvision,
进入pytorch官网https://pytorch.org/get-started/previous-versions/
找到1.6.0的版本下载安装:(根据cuda版本选择安装)
Linux and Windows
# CUDA 9.2
conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=9.2 -c pytorch
# CUDA 10.1
conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=10.1 -c pytorch
# CUDA 10.2
conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=10.2 -c pytorch
# CPU Only
conda install pytorch==1.6.0 torchvision==0.7.0 cpuonly -c pytorch
这里我是cuda10.2,所以选择对应安装命令
3.安装TensorRT7.1.3.4,进入官网https://developer.nvidia.com/tensorrt选择7.1.3.4版本进行安装
安装torch2trt 0.1.0 ,进入官网https://github.com/NVIDIA-AI-IOT/torch2trt
按以下步骤安装下载好的TensorRT
tar xzvf TensorRT-${version}.${os}.${arch}-gnu.${cuda}.${cudnn}.tar.gz
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:<TensorRT-${version}/lib>
cd TensorRT-${version}/python
pip3 install tensorrt-*-cp3x-none-linux_x86_64.whl
cd TensorRT-${version}/uff
pip3 install uff-0.6.9-py2.py3-none-any.whl
cd TensorRT-${version}/graphsurgeon
pip3 install graphsurgeon-0.4.5-py2.py3-none-any.whl
按以下步骤安装torch2trt
git clone https://github.com/NVIDIA-AI-IOT/torch2trt
cd torch2trt
sudo python setup.py install --plugins
此处可能安装不成功,换命令:python setup.py/python setup.py install
4.安装所需依赖库:
# Cython needs to be installed before pycocotools
pip install cython
pip install opencv-python pillow matplotlib
pip install git+https://github.com/haotian-liu/cocoapi.git#"egg=pycocotools&subdirectory=PythonAPI"
pip install GitPython termcolor tensorboard
到此环境配置完成。
二、demo测试
1.图片测试:
# Display qualitative results on the specified image.
python eval.py --trained_model=weights/yolact_edge_54_800000.pth --score_threshold=0.3 --top_k=100 --image=my_image.png
# Process an image and save it to another file.
python eval.py --trained_model=weights/yolact_edge_54_800000.pth --score_threshold=0.3 --top_k=100 --image=input_image.png:output_image.png
# Process a whole folder of images.
python eval.py --trained_model=weights/yolact_edge_54_800000.pth --score_threshold=0.3 --top_k=100 --images=path/to/input/folder:path/to/output/folder
2.视频测试
# Display a video in real-time. "--video_multiframe" will process that many frames at once for improved performance.
# If video_multiframe > 1, then the trt_batch_size should be increased to match it or surpass it.
python eval.py --trained_model=weights/yolact_edge_54_800000.pth --score_threshold=0.3 --top_k=100 --video_multiframe=2 --trt_batch_size 2 --video=my_video.mp4
# Display a webcam feed in real-time. If you have multiple webcams pass the index of the webcam you want instead of 0.
python eval.py --trained_model=weights/yolact_edge_54_800000.pth --score_threshold=0.3 --top_k=100 --video_multiframe=2 --trt_batch_size 2 --video=0
# Process a video and save it to another file. This is unoptimized.
python eval.py --trained_model=weights/yolact_edge_54_800000.pth --score_threshold=0.3 --top_k=100 --video=input_video.mp4:output_video.mp4
测试中如果出现tensorRT加载失败的情况,关闭加速即可。在命令后加上--disable_tensorrt
三、训练自己的数据集
1.下载预训练权重文件
链接:https://pan.baidu.com/s/14zdlkneSjAClFmS-DQ4lQg
提取码:aaaa
下载好文件后新建一个weights的文件夹,把resnet50-19c8e357.pth放在这个文件夹下
2.制作自己的数据集
(1)准备好你的数据集,把你的数据集分成两份,一份放在yolact-master\data\coco\train2017文件下,作为训练集,一份放在yolact-master\data\coco\val2017文件夹下,作为测试集。
(2)将生成的.json文件和原图片放在相应文件夹里,最后的yolact-master\data\coco\train2017文件夹下长这样:

制作COCO格式的数据集
(1)cd到train2017文件夹下
(2)运行labelme2coco.py
源码如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import argparse
import glob
import json
import os.path as osp
import numpy as np
import labelme
import pycocotools.mask
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--img_dir', default='/home/lhb/下载/yolact_edge-master/data/coco-grape/train/', help='input annotated directory')
parser.add_argument('--label_name', default='/home/lhb/下载/yolact_edge-master/coco_grape/label.txt', help='labels file')
parser.add_argument('--img_type', default='jpg', help='jpg, png, bmp...')
args = parser.parse_args()
data = dict(images=[], annotations=[], categories=[])
class_name_to_id = {}
for i, line in enumerate(open(args.label_name).readlines()):
class_name = line.strip()
class_name_to_id[class_name] = i
data['categories'].append(dict(id=i, name=class_name))
print(f'Created class_name_to_id: {class_name_to_id}.\n')
class_name_to_id_key = list(class_name_to_id.keys())
label_files = glob.glob(osp.join(args.img_dir, '*.json'))
for image_id, label_file in enumerate(label_files):
print('Generating dataset from:', label_file)
with open(label_file) as f:
label_data = json.load(f)
img_h, img_w = label_data['imageHeight'], label_data['imageWidth']
data['images'].append(dict(file_name=label_file.split('/')[-1].replace('json', args.img_type),
height=img_h,
width=img_w,
id=image_id))
for shape in label_data['shapes']:
points = shape['points']
label = shape['label']
shape_type = shape.get('shape_type', None)
mask = labelme.utils.shape_to_mask((img_h, img_w), points, shape_type)
assert label in class_name_to_id_key, f'Error, {label} not in class_name_to_id.'
cls_id = class_name_to_id[label]
mask = np.asfortranarray(mask.astype(np.uint8))
mask = pycocotools.mask.encode(mask)
area = float(pycocotools.mask.area(mask))
bbox = pycocotools.mask.toBbox(mask).flatten().tolist()
data['annotations'].append(dict(id=len(data['annotations']),
image_id=image_id,
category_id=cls_id,
segmentation=[np.asarray(points).flatten().tolist()],
area=area,
bbox=bbox,
iscrowd=0))
with open(osp.join(args.img_dir, 'custom_ann.json'), 'w') as f:
json.dump(data, f)
print('Saved in: ' + osp.join(args.img_dir, 'custom_ann.json'))
(3)同样的步骤,cd到val2017文件夹下,然后运行labelme2coco.py得到instances_val2017.json文件,
将得到的instances_train2017.json和instances_val2017.json文件移动到annotations文件夹下
3.修改训练模型
一共修改三处:
修改一:我们需要自己定义我们数据集的种类和标签,比如我的标签只有一类“grape”,就修改如下:

修改二:在DATASET部分增加自己的数据集
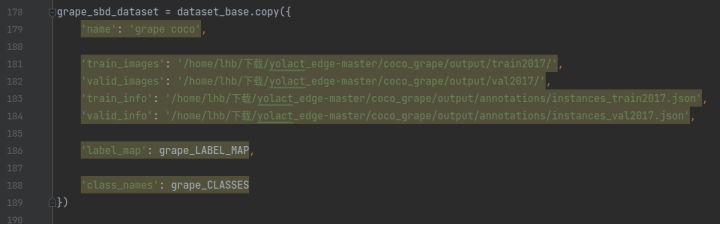
其中:
(1)name:你的数据集名字
(2)class_name:你的类的名称,就是你在修改一部分起的类名
(3)label_map:你的标签名称,就是你在修改一部分起的标签名称
(4)train_info:你训练集数据通过labelme2coco.py文件生成的.json文件所在位置
(5)train_images:你的训练集数据图片所在位置
(6)valid_info:你验证集数据通过labelme2coco.py文件生成的.json文件所在位置
(7)valid_images:你的验证集数据图片所在位置
修改三:在yolact_base_config基础上,构建yolact_edge_grape_config,格式参照yolact_edge_config,只不过这里要做更多修改,改掉一些默认的配置:
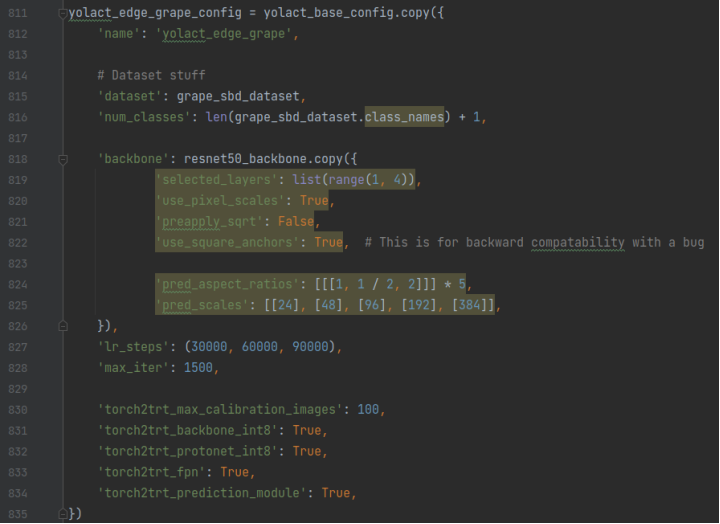
(1)name:自己定义的名字
(2)dataset:你在修改二中的dataset
(3)num_classes:在类别数的基础上要加1
(4)backbone:主干网络,写我写的这个就行
(5)max_iter:最大迭代次数,我写的1500是因为我想先做一个初步的尝试。
最后指定cfg为yolact_edge_pascal_config。

其他修改
如果电脑没有安装git,则需要在train.py中将这几行注释掉

参考博客:https://blog.csdn.net/qq_39056987/article/details/111614535
4.开始训练
python train.py --config=yolact_edge_grape_config --batch_size 4
训练后得到的权重在weights文件夹下,按二中将权重改为训练后的文件即可进行测试。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









