







(一)JSC与WebCore
先看一下官方的基本介绍,短短几句就塞满了关键字。
SquirrelFish,正式名称是JavaScriptCore,包括register-based(基于寄存器的虚拟机), direct-threaded, high-level bytecode engine(字节码引擎).它使用基于内置copy propagation(复制性传播算法)的一次性编译器(one-pass compiler),能够延迟从语法树(Syntax Tree)上生成字节码(Bytecodes)。
由此可见JavaScriptCore实现的复杂度。做为一个正在努力学习的菜鸟,我愿意给自己这样一个挑战,通过记录和总结学习内容,分成两个大的段落从内部视角来解析JavaScriptCore。首先是基础篇,目的是了解JavaScriptCore是如何与WebKit一起工作的,会涉及一些JavaScript引擎的一些基本概念。然后是高级篇,尝试解释JavaScriptCore中的核心技术,如Byte Code Compiler, JIT, VM以及GC等。
内容或许会显得晦涩,如果只是想简单地了解浏览器JS引擎的一些基本内容,推荐读读下面的文章。它们对于理解后面的内容也会非常有帮助。相对于这些资料,这个系列则侧重于从基础及从实例来分析JSC的实现。没办法做到高层次,只能追求贴近实现。
JavaScriptCore, WebKit的JS实现(一)
JavaScriptCore, WebKit的JS实现(完)
当然,JavaScript的知识是必不可少的,推荐阅读一篇(JavaScript核心指南),如果有时间可以深入学习一下其中提到的链接。
一. JavaScriptCore与WebCore
两者的关系可以简单的用下图来表示:
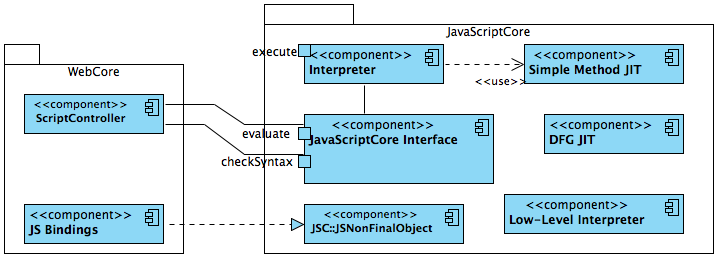
JSC为WebCore提供两个重要功能:
1. JS脚本的解析执行 (ScriptController)
主要是通过调用JavaScriptCore提供的两个C接口来实现的, checkSyntax和evaluate.
2. DOM节点的JS Bindings
DOM节点所对应的JS Bindings都可以回溯到JSC::JSNonFinalObject,再到JSObject,以实现和JSC绑定在一起。
*关于JS Binding,可以先看一下这篇文章: 为JavaScript Binding添加新DOM对象的三种方式及实作。至于JSC实现的细节,以后再展开。
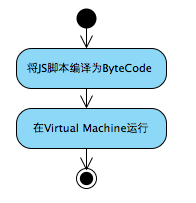
二. JavaScriptCore基本工作过程
JSC最简单的执行过程如下,再如之后JIT等在这个基础上的优化。
三. JavaScript脚本的执行
以下分层说明脚本执行的步骤。 对于涉及到编译及执行的细节,则在后续解释。
3.1 接口层的交互
JSC和其它几个主要的JS Engine一样,都是一个库,通过提供简单的API来供调用者使用。
从JSC接口来看,一个完整的JavaScript脚本的解析执行过程,可以概述以下:
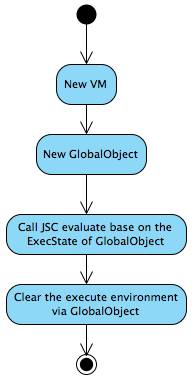
过程很简单,可是很明显有些关键词必须要理解一下,如VM, Global Object, ExecState. 它们的关系也可以通过一张图来解释:
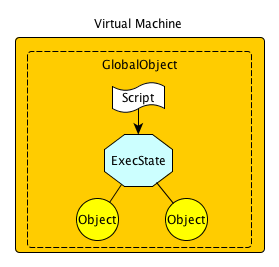
VM -> Virtual Machine, JavaScript要借助于一个运行时(Runtime)环境来运行。 SpiderMonkey就称之为Runtime.
GlobalObject -> 脚本执行时的全局对象。一个全局负责组织管理执行环境以及各个子对象。
ExecState -> 用于记录脚本执行上下文或环境, 也由GlobalObject管理。SpiderMoney以及Apple封装后的JavaScriptCore.framework都称之为上下文(Context). 可以将其视为一个执行脚本的对象来理解,只是它所产生和使用的Objects是共享的,并可以由GlobalObject来访问。
JS解释器各自实现的方式略有不同,JSC是由一个全局变量(Global Object)来创建上下文环境(ExecState), 而SpiderMonkey则是由执行上下文来创建全局变量。但无论哪种实现,全局变量和上下文都一一对应的,虽然原则上是允许一对多的情况出现。
最后看下JSC执行JS脚本的接口定义, 就很好理解了:
JSValue evaluate(ExecState* exec,constSourceCode& source,JSValue thisValue,JSValue* returnedException);
*thisValue就是JavaScript的this, 代表的是执行者, 但不一定是创建者。
*使用JSC的示例代码,可以看看WebKit里的jsc.cpp就可以了。
*如果觉得没有讲清楚,建议读读这里(JavaScript核心指南)。
3.2 JSC API执行脚本的步骤
下图是JSC API函数evaluate的活动图:
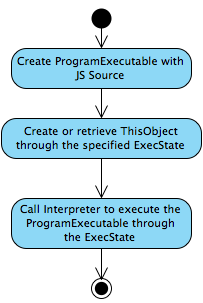
重点在于它会使用要执行的脚本内容建立一个ProgramExecutable对象,然后调用Interpreter执行这个代表脚本的ProgramExecutable对象。
ProgramExecutable和Interpreter都是JSC核心类,ProgramExecutable负责编译代码为ByteCode,属于解释器功能组, 而Interpreter则负责解析执行ByteCode,则属于VM功能组.
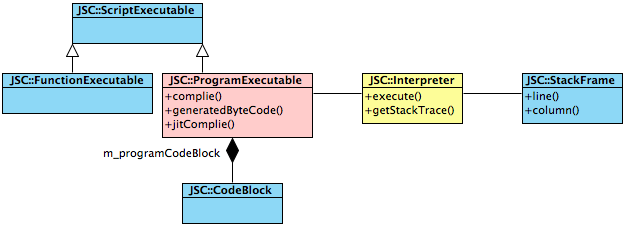
*Interpreter提供的两个dump函数对于分析代码也很有用, dumpCallFrame和dumpRegisters。
再往下的内容,就是一个编译和执行的过程,后续再深入。
四. DOM Bindings的响应
实现上的解析在这里:
以及另一篇可以加深理解:
为JavaScript Binding添加新DOM对象的三种方式及实作
(二)解释器基础与JSC核心组件
这一篇主要说明解释器的基本工作过程和JSC的核心组件的实现。
作为一个语言,就像人在的平时交流时一样,当接收到信息后,包含两个过程:先理解再行动。理解的过程就是语言解析的过程,行动就是根据解析的结果执行对应的行为。在计算机领域,理解就是编译或解释,这个已经被研究的很透彻了,并且有了工具来辅助。而执行则千变万化,也是性能优化的重心。下面就来看看JSC是如何来理解、执行JavaScript脚本的。
解释器工作过程
JavaScriptCore基本的工作过程如下:
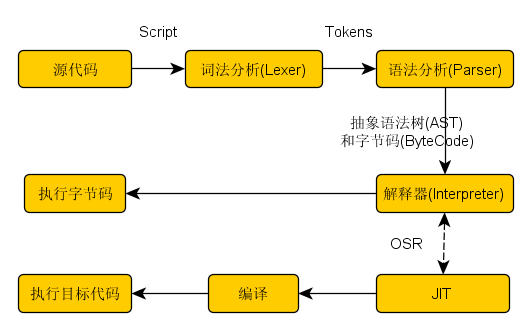
对于一个解释器,首先必须要明确所支持的语言, JSC所支持的是EMCAScript-262规范。
词法分析和语法分析就是理解的过程,将输入的文本转为一种它可以理解的语义形式(抽象语法树), 或者更进一步的生成供后续使用的中间代码(字节码,ByteCode)。
解释器就是负责执行解析输出的结果。正因为执行是优化的重心,所以有JIT来提高执行效能。根据资料,V8还会优化Parser的输出,省去了bytecode, 当解释器有能力直接基于AST执行。
词法分析及语法分析,最著名的工具就是lex/yacc,以及后继者flex/bison(The LEX&YACC Page)。它们为很多软件提供了语言或文本解析的功能,相当强大,也很有趣。虽然JavaScriptCore并没有使用它们,而是自行编写实现的,但基本思路是相似的。
词法分析(lexer),其实就是一个扫描器,依据语言的定义,提取出源文件中的内容变为一个个语法可以识别的token,比如关键字,操作符,常量等。在一个文件中定义好规则就可以了。
语法分析(paser), 它的功能就是根据语法(token的顺序组合),识别出不同的语义(目标操作)。
比如:
i=3;
经过lexer可能被识别为以下的tokens:
VARIABLE EQUAL CONSTANT END
经过parser一分析,就了解这是一个"赋值操作,向变量i赋值常量3"。随后再调用对应的操作加以执行。
如果你对lexer和parser还不太熟悉,可参考的资料很多,这里有一个基本的入门指引:Yacc与Lex快速入门。
关于解释器和JIT的说明在第3节。
执行的基础环境(Register-based VM)
JSC解析生成的代码放到一个虚拟机上来执行(广义上讲JSC主身就是一个虚拟机)。JSC使用的是一个基于寄存器的虚拟机(register-based VM),另一种实现方式是基于栈的虚拟机(stack-based VM)。两者的差异可以简单的理解为指令集传递参数的方式,是使用寄存器,还是使用栈。
相对于基于栈的虚拟机,因为不需要频繁的压、出栈,以及对三元操作的支持,register-based VM的效率更高,但可移植性相对弱一些。
所谓的三元操作符,其中add就是一个三元操作,
add dst, src1, src2
功能是将src1与src2相加,将结果保存在dst中。dst, src1,src2都是寄存器。
为了方便和<<深入理解Java虚拟机>>中的示例进行对比,也利用JSC输出以下脚本的ByteCode如下:
- [ 0] enter
- [ 1] mov r0, Cell: 0133FC40(@k0)
- [ 4] put_by_id r0, a(@id0), Int32: 100(@k1)
- [ 13] mov r0, Cell: 0133FC40(@k0)
- [ 16] put_by_id r0, b(@id1), Int32: 200(@k2)
- [ 25] mov r0, Cell: 0133FC40(@k0)
- [ 28] put_by_id r0, c(@id2), Int32: 300(@k3)
- [ 37] resolve_global r0, a(@id0)
- [ 43] resolve_global r1, b(@id1)
- [ 49] add r0, r0, r1
- [ 54] resolve_global r1, c(@id2)
- [ 60] mul r0, r0, r1
- [ 65] ret r0
*参考: JSC字节码规格 (WebKit没有及时更新,只做为参考,最新的内容还是要看代码.)
而基于栈的虚拟机的生成的字节码如下:
- 0: bipush 100
- 2: istore_1
- 3: sipush 200
- 6: istore_2
- 7: sipush 300
- 10: istore_3
- 11: iload_1
- 12: iload_2
- 13: iadd
- 14: iload_3
- 15: imul
- 16: ireturn
可以帮助理解它们之间的差异。
核心组件
*这部分基本上译自WebKit官网的JavaScriptCore说明的前半部分。
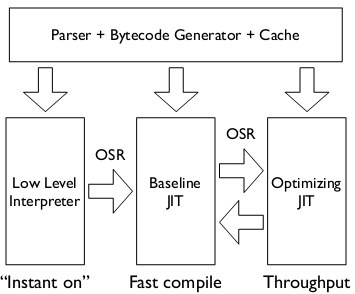
JavaScriptCore 是一个正在演进的虚拟机(virtual machine), 包含了以下模块: lexer, parser, start-up interpreter (LLInt), baseline JIT, and an optimizing JIT (DFG).
Lexer 负责词法解析(lexical analysis) , 就是将脚本分解为一系列的tokens. JavaScriptCore的 lexer是手动撰写的,大部分代码在parser/Lexer.h 和 parser/Lexer.cpp 中.
Parser 处理语法分析(syntactic analysis), 也就是基于来自Lexer的tokens创建语法树(syntax tree). JavaScriptCore 使用的是一个手动编写的递归下降解析器(recursive descent parser), 代码位于parser/JSParser.h 和 parser/JSParser.cpp .
LLInt, 全称为Low Level Interpreter, 负责执行由Paser生成的字节码(bytecodes). 代码在llint/ 目录里, 使用一个可移植的汇编实现,也被为offlineasm (代码在offlineasm/目录下), 它可以编译为x86和ARMv7的汇编以及C代码。LLInt除了词法解析和语法解释外,JIT编译器所执行的调用、栈、以及寄存器转换都是基本没有启动开销(start-up cost)的。比如,调用一个LLInt函数就和调用一个已经被编译原始代码的函数相似, 除非机器码的入口正是一个共用的LLInt Prologue(公共函数头,shared LLInt prologue). LLInt还包括了一些优化,比如使用inline cacheing来加速属性访问.
Baseline JIT 在函数被调用了6次,或者某段代码循环了100次后(也可能是一些组合,比如3次带有50次枚举的调用)就会触发Baseline JIT。这些数字只是大概的估计,实际上的启发(heuristics)过程是依赖于函数大小和当时内存状况的。当JIT卡在一个循环时,它会执行On-Stack-Replace(OSR)将函数的所有调用者重新指向新的编译代码。Baseline JIT同时也是函数进一步优化的后备,如果无法优化代码时,它还会通过OSR调整到Baseline JIT. BaseLine JIT的代码在 jit/ . 基线JIT也为inline caching执行几乎所有的堆访问。
无论是LLInt和Baseline JIT者会收集一些轻量级的性能信息,以便择机到更高一层级(DFG)执行。收集的信息包括最近从参数、堆,以及返回值中的数据。另外,所有inline caching也做了些处理,以方便DFG进行类型判断,例如,通过查询inline cache的状态,可以检测到使用特定类理进行堆访问的频率。这个可以用于决定是否进入DFG (文中称这个行为叫speculation, 有点赌一把的意思,能优化获得更高的性能最好,不然就退回来)。在下一节中着重讲述JavaScriptCore类型推断。
DFG JIT 在函数被调用了至少60次,或者代码循环了1000次,就会触发DFG JIT。同样,这些都是近似数,整个过程也是趋向于启发式的。DFG积极地基于前面(baseline JIT&Interpreter)收集的数据进行类型推测,这样就可以尽早获得类型信息(forward-propagate type information),从而减少了大量的类型检查。DFG也会自行进行推测,比如为了启用inlining, 可能会将从heap中加载的内容识别出一个已知的函数对象。如果推测失败,DFG取消优化(Deoptimization),也称为"OSR exit". Deoptimization可能是同步的(某个类型检测分支正在执行),也可能是异步的(比如runtime观察到某个值变化了,并且与DFG的假设是冲突的),后者也被称为"watchpointing"。 Baseline JIT和DFG JIT共用一个双向的OSR:Baseline可以在一个函数被频繁调用时OSR进入DFG, 而DFG则会在deoptimization时OSR回到Baseline JIT. 反复的OSR退出(OSR exits)还有一个统计功能: DFG OSR退出会像记录发生频率一样记录下退出的理由(比如对值的类型推测失败), 如果退出一定次数后,就会引发重新优化(reoptimization), 函数的调用者会重新被定位到Baseline JIT,然后会收集更多的统计信息,也许根据需要再次调用DFG。重新优化使用了指数式的回退策略(exponential back-off,会越来越来)来应对一些奇葩代码。DFG代码在dfg/.
任何时候,函数, eval代码块,以及全局代码(global code)都可能会由LLInt, Baseline JIT和DFG三者同时运行。一个极端的例子是递归函数,因为有多个stack frames,就可能一个运行在LLInt下,另一个运行在Baseline JIT里,其它的可能正运行在DFG里。更为极端的情况是当重新优化在执行过程被触发时,就会出现一个stack frame正在执行原来旧的DFG编译,而另一个则正执行新的DFG编译。为此三者设计成维护相同的执行语义(execution semantics), 它们的混合使用也是为了带来明显的效能提升。
*如果想要观察它们的工作,可以在WebKit中的子工程jsc的jsc.cpp中,使用JSC::Options添加一部分log输出.
参考阅读:
虚拟机随谈(一): 解释器,树遍历解释器,基于栈与基于寄存器,大杂烩 http://rednaxelafx.iteye.com/blog/492667
(三)从脚本代码到JIT编译的代码实现
前面说了一些解析、生成ByteCode直至JIT的基本概念,下面是对照JavaScriptCore源代码来大致了解它的实现。
从JS Script到Byte Code
首先说明Lexer, Parser和ByteCode的生成都是由ProgramExecutable初始化过程完成的。先在JSC的API evaluate()中会创建ProgramExecutable并指定脚本代码。然后传入Interpreter时,再透过CodeCache获取的UnlinkedProgramCodeBlock就是已经生成ByteCode后的Code Block了。
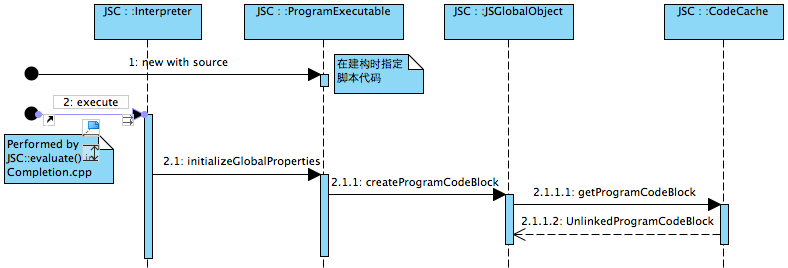
下图是CodeCache调用Parser和ByteCodeGenerator的序列图:
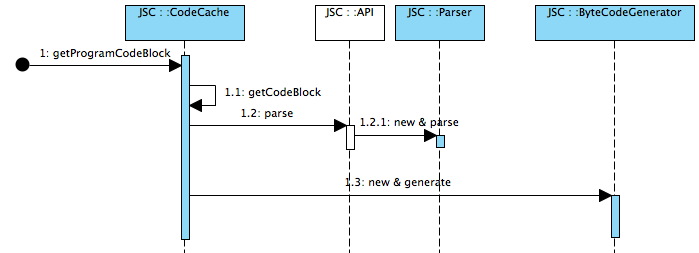
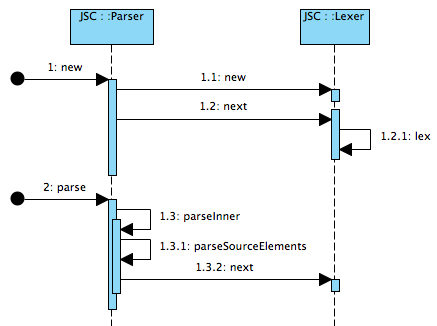
而Lexer则是在Parser过程中调用的,如下图:
再从类图来观察所涉及的几个类之间的关系:

关于CodeBlock、UnlinkedCodeBlock和ScriptExecutable
CodeBlock可以理解为代码管理的类,按类型分为GlobalCodeBlock, ProgramCodeBlock, FunctionCodeBlock及EvalCodeBlock, 与之对应的UnlinkedCodeBlock和ScriptExecutable也有相似的继承体系,如下所示:
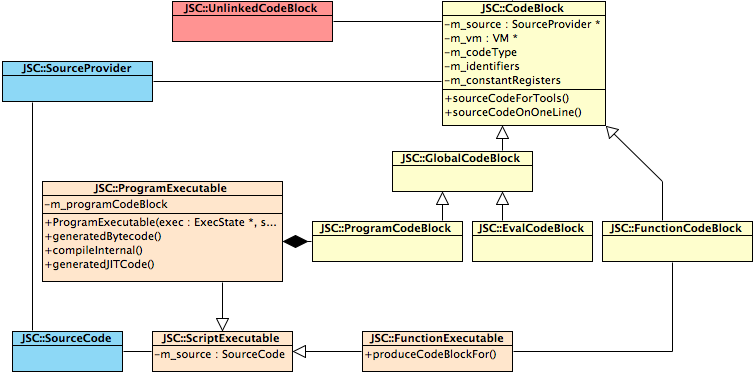
UnlinkedCodeBlock存储的是编译后的ByteCode,而CodeBlock则会用于LLint和JIT。
ProgramExecutable则可以理解为当前所执行脚本的大总管,从其名字上可以看出来是代表一个可执行程序。
它们的作用也很容易理解。
关于LLint的slow path
前面说过了LLint是基于offlineasm的汇编语言,这里只是介绍一下它的slow path. 为了处理一些操作,需要在LLint执行指令时调用一些C函数进行扩展处理,比如后面要说明的JIT统计功能,LLint提供一个调用C函数的接口,并将所有会被调用的C函数称为slow path,如下图所示:
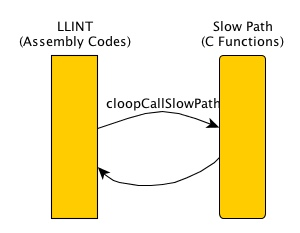
代码可以在LowLevelInterpreterXXX.asm中看到。所以可以C函数声明看到带有SLOW_PATH的宏。
关于JIT优化的触发
首先JSC使用的是基于计数器的热点探测方法。前面提到函数或循环体被执行若干次后会触发JIT, 首先这个次数是可以通过JSC::Options中的thresholdForOptimizeSoon来设定的。然后在LLint在执行循环的ByteCode指令loop_hint和函数返回指令ret时会调用slow path中的C函数,进行次数统计和判断,过程如下:
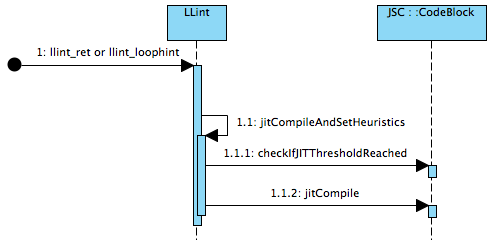
其中会根据checkIfJITThresholdReached()返回结果来决定是否进行jitCompile.一旦要进行JIT编译时,也是根据当前CodeBlock的类型,而执行针对不同函数或代码段的优化。下面显示的是对一个频繁使用的函数进行JIT编译的操作:
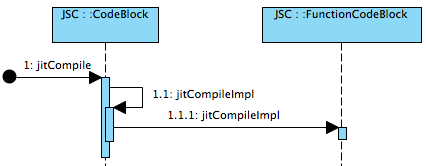
其中计数的功能并非由CodeBlock直接实现,而是通过ExecutionCounter来管理的。主要关系如下:
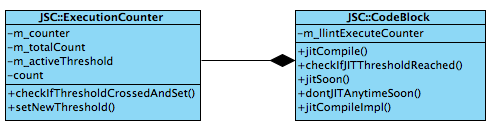
(四) 页面解析与JavaScript元素的执行
很多地方都已经介绍了JavaScript在浏览器是如何被执行的,这里介绍一下WebKit是如何实现的。主要涉及JS的async,defer及普通脚本的解析与执行过程的代码实现。
1. 概要说明
先概要说明一下浏览器如何执行JavaScript的。 首先浏览器的页面解析器(Document Parser)遇到<script>就会发起下载(脚本内容在页面内的就不用下载了)。然后针对不同情况执行的方式有所不同:
. async (在script标签中启用了async属性)
这是异步执行,下载时不会阻塞Document Parser, 当JavaScript被加载完成后就会开始执行。
. defer (在script标签中启用了defer属性)
这个是推迟执行,下载时同样不会阻塞Document Parser, 会放到Document Parser完成页面解析后才会执行。
. 对于引用外部的脚本文件,下载时Document Parser会被阻塞至脚本执行完。
. 如果页面中有Style Sheet还没有解析成功, 则脚本会被阻塞直到Style Sheet下载并解析完成。
因为阻塞会严重影响页面解析的性能,所以也是浏览器优化的重点:
a. WebKit引入Preload Scanner允许在下载时尝试继续处理后面的资源。 [LINK] 不过随着网络的提速,这个优化的效果应逐渐减弱。
b. FireFox实现异步HTML解析,WebKit也2013年年初实现了一个轻量级版本(只将tokenizer多线程化)。
2. WebCore中执行JavaScript
2.1 主要功能划分
WebCore中关于JavaScript的元素的解析与执行,个人把相关类分成两个主要的类别:
页面解析功能和JS执行功能。
页面解析类别的侧重于在HTMLDocumentParser解析页面过程中管理脚本的创建、规划执行策略等。这一部分细节功能比较复杂,在W3C中有专门的定义,WebKit中的实现很多地方也注上了所参考的章节。
JS执行类别基于Document和Frame来管理JS执行环境,并同JSC协作执行JS脚本。
下面是一个总览, 黄色背景的类属于为页面解析类别,红色背景的部分则归到执行类别。
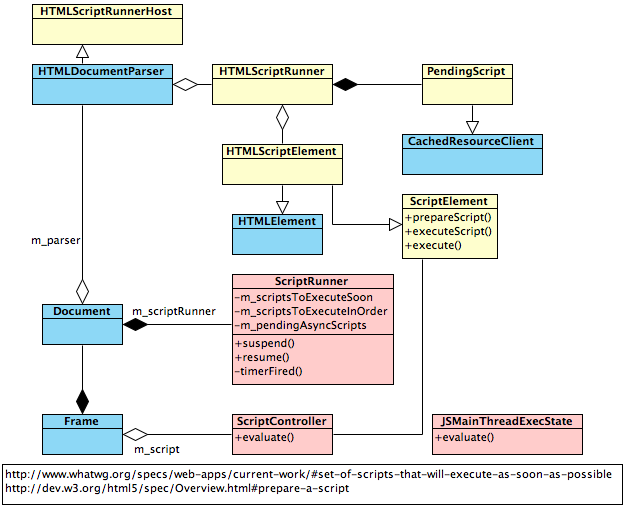
*主要类的代码基本集中在bindings/js目录下。
2.2 JS元素的执行
这里的执行不包括页面对JS执行的策略,主要针对具体的执行过程。
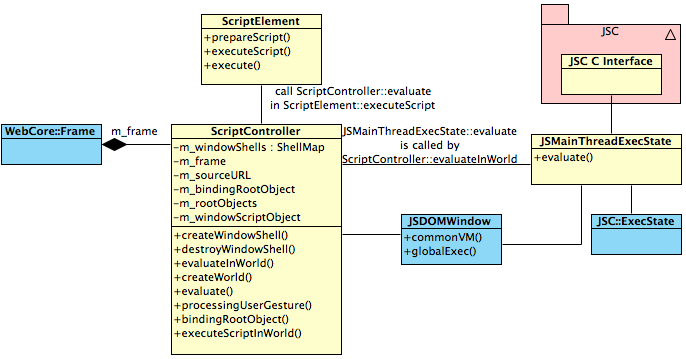
JSMainThreadExecState 负责最终对接JSC模块执行JS脚本。在系统中是一个单例的对象,也就是保证单进程与JSC协作。这同样也是JS的一个限制点。
ScriptController 维护一个JavaScriptCore执行环境,在必要时调用JSMainThreadExecState执行。
ScriptElement 代表了一个具体的script元素,包括JavaScript, SVG等。
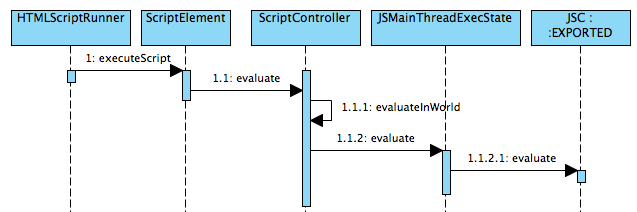
再附上一张时序图来帮助了解它们间的关系, (其中脚本的执行决策是由HTMLScriptRunner来发起的):
2.3 JS元素的解析与管理
在WebKit内部,页面解析与脚本控制的操作主要是在HTMLDocumentParser,HTMLScriptRunner和ScriptElement中实现的。
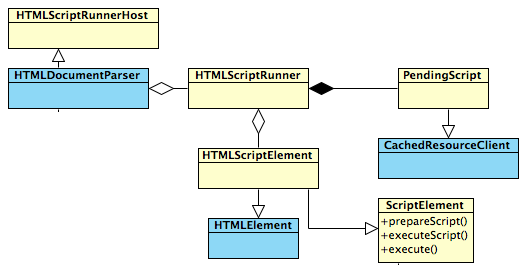
2.3.1 JS解析
从下面这张经典的图说起:
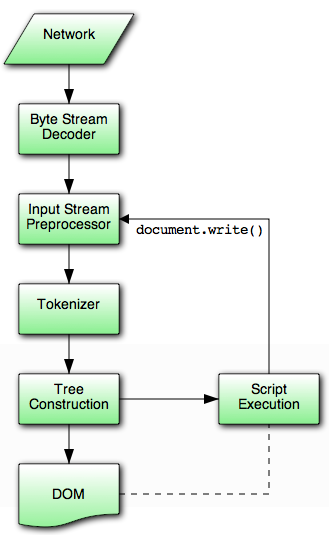
这张图源自W3C的官方定义, 与主文相关的是说明JS之所以会导致页面解析阻塞正是因为它允许脚本使用document.write()改变页面内容,会造成DOM树可能会需要重新解析(reparser)。所以非但浏览器要做些优化,JS开发者也要注意JS的实现方法,比如编写non-block script。
另外不但JS阻塞Parser, Style Sheet也会阻塞JS。如果JS里包含了对某个元素的显示属性的检测,在CSS还没有加载解析完成的情况下,肯定得不到正确结果。所以对应在WebKit也对应出了不同的定义。
在HTMLScriptRunner有两个重要的成员变量:
m_scriptsToExecuteAfterParsing -> 由requestDeferredScript()添加。
m_parserBlockingScript -> 由requestParsingBlockingScript添加。
根据名字也可以看出来前者是保存defer脚本,后者是保存一般的脚本的。至于async则是在下载完成后触发的,稍后说明。
2.4 JS运行策略
之前说到不同的JS加载属性的执行方法会不一样:
async -> 是由ScriptRunner::notifyScriptReady在脚本下载完成时执行的。
defer -> 是由HTMLDocumentParser::notifyFinished()在页面解析完成时发起执行的。
其它的JS脚本则在处理token时由HTMLDocumentParser::canTakeNextToken来检测并发起执行的。
2.4.1一般JS脚本的执行
一般没有带async和defer属性的JS脚本,被称为解析阻塞脚本(Parsing Blocking Scripts),则由HTMLScriptRunner::executeParsingBlockingScripts()负责执行的。
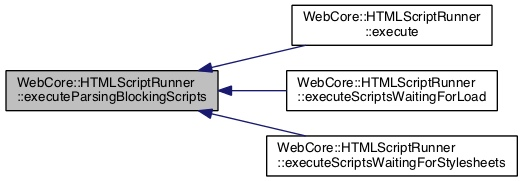
一个典型的调用方式如下:
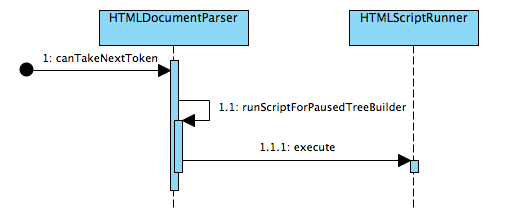
比如当新解析到一个Token时,Document Parser就会触发一个canTakeNextToken来检查一些状态,其中一项就是看看脚本是否可以运行,如果条件合适就会执行相应的脚本。所谓条件合适,可以在它会调用的HTMLScriptRunner::isPendingScriptReady里看到(函数也很好理解,就是看之前挂起的脚本是不是又可以执行了) :
- <span style="font-size:14px;">bool HTMLScriptRunner::isPendingScriptReady(const PendingScript& script)
- {
- m_hasScriptsWaitingForStylesheets = !m_document->haveStylesheetsLoaded();
- if (m_hasScriptsWaitingForStylesheets)
- return false;
- if (script.cachedScript() && !script.cachedScript()->isLoaded())
- return false;
- return true;
- }</span>
其中等待的就是两个条件:
1. 是不是正在加载CSS.
2. 脚本是不是有信赖的脚本还在加载.
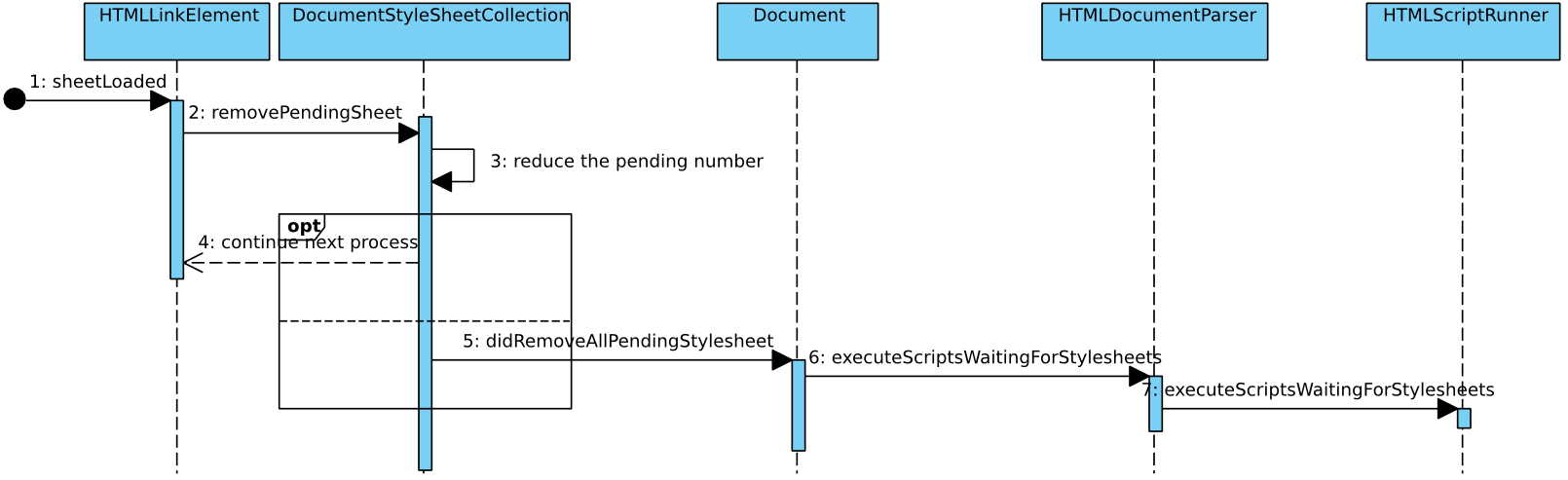
下面再介绍一个入口。因为有一部分脚本是等待CSS加载完成后才会执行的,所以在CSS加载完成会一次调用过程如下:
2.4.2 async与defer脚本的执行
下面就附两张图来说明两者的执行过程,中间省略一些不重要的步骤。
async的执行过程, 注意是由资源加载触发:
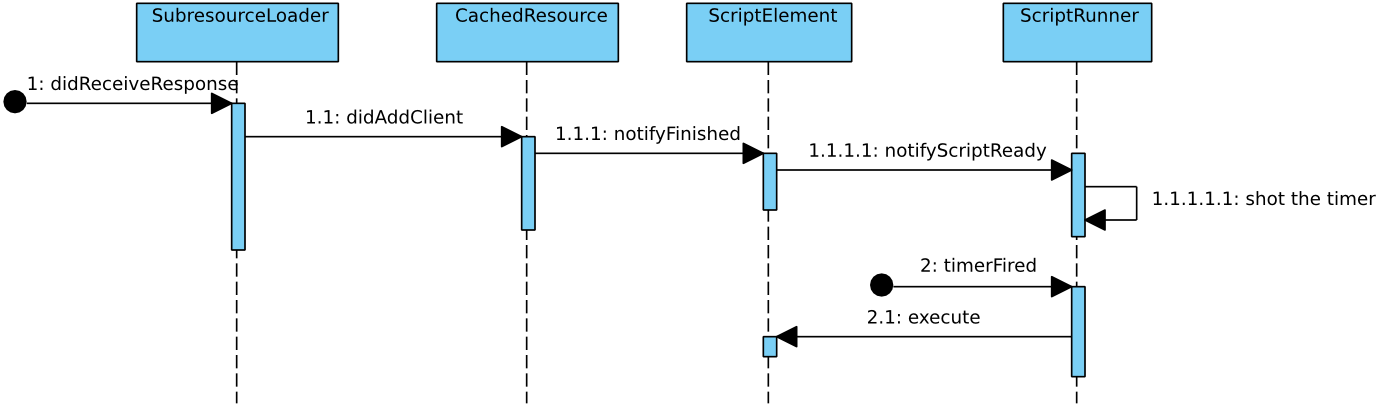
defer脚本的执行过程,除了这个之外,还有一些异常的考虑,比如在HTMLScriptRunner析构时也会进行处理。
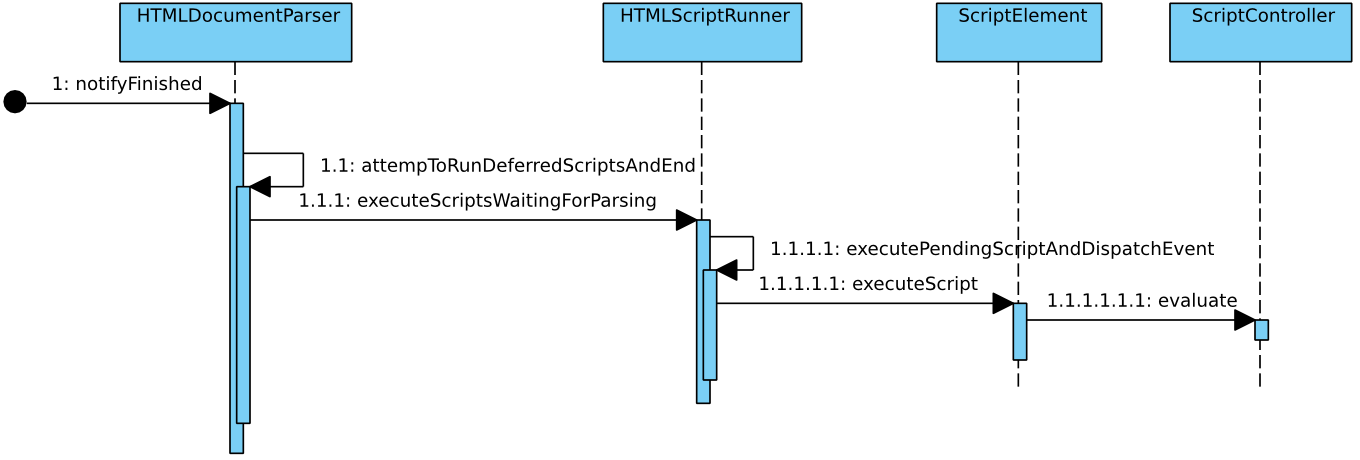
2.4.3 进一步阅读代码指引
以HTMLScriptRunner的runScript为例,它是由HTMLScriptRunner::execute()调用的,其实对应于W3C定义的标准流程: Running a script:
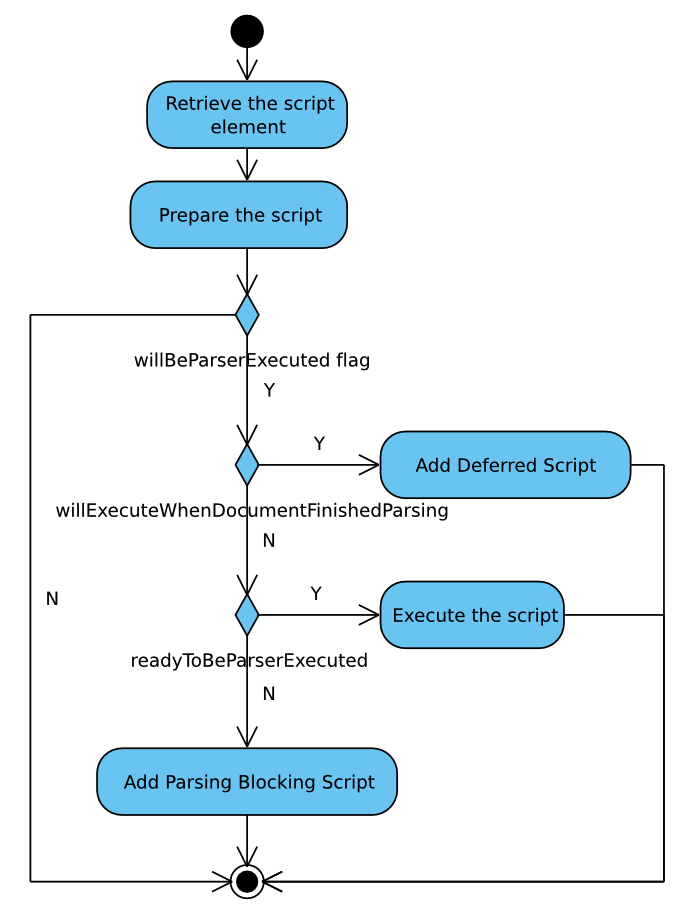
这一部分的涉及到很多的细节,可以参考W3C的定义进一步阅读代码。
http://www.whatwg.org/specs/web-apps/current-work/multipage/scripting-1.html
ScriptElement::prepareScript() -> http://dev.w3.org/html5/spec/Overview.html#prepare-a-script
WebKit在重要函数里也标注了对应标准文档的章节,看代码前可以先阅读这部分的说明。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









