







目录
参考和学习资料和途径
文档和教程
教程
链接:https://www.jianshu.com/p/22bbb8f029e6
视频教程:腾讯视频
文档
《Mellanox OFED for Linux User Manual 4.4》https://www.mellanox.com/related-docs/prod_software/Mellanox_OFED_Linux_User_Manual_v4_4.pdf
《Mellanox OFED for Linux User Manual 3.2》https://www.mellanox.com/related-docs/prod_software/Mellanox_OFED_Linux_User_Manual_v3.20.pdf
《MLNX_OFED Documentation Rev 4.6-1.0.1.1》MLNX_OFED Documentation Rev 4.6-1.0.1.1 - MLNX_OFED v4.6-1.0.1.1 - NVIDIA Networking Docs
《RDMA Aware Networks Programming User ManualRev 1.7》
官方编程手册最靠谱,获取mellanox网卡方编程手册的方法:
https://docs.nvidia.com/networking/software/index.html
https://docs.nvidia.com/networking/software/adapter-software/index.html
还有一些已经翻译过的:
RDMA中英文编程手册1.7-:https://download.csdn.net/download/bandaoyu/87354001
中文翻译:RDMA编程用户手册-官方中文版_rdma编程,rdma编程用户手册-网管软件文档类资源-CSDN下载
论文:
《RDMA over Commodity Ethernet at Scale》https://www.microsoft.com/en-us/research/wp-content/uploads/2016/11/rdma_sigcomm2016.pdf
《基 于 ibdump的 InfiniBand网络拥塞控制观测方法研究》http://www.jsjkx.com/CN/article/openArticlePDF.jsp?id=6159
PPT:
<分析 InfiniBand 数据包>https://openfabrics.org/images/eventpresos/workshops2015/UGWorkshop/Thursday/thursday_09.pdf
RDMA网卡厂商官网
RDMA over Converged Ethernet (RoCE) - MLNX_OFED v4.5-1.0.1.0 - NVIDIA Networking Docs
开发社区
Linux社区
Linux内核的RDMA子系统还算比较活跃,经常会讨论一些协议细节,对框架的修改比较频繁,另外包括华为和Mellanox在内的一些厂商也会经常对驱动代码进行修改。
邮件订阅:http://vger.kernel.org/vger-lists.html#linux-rdma
代码位于内核drivers/infiniband/目录下,包括框架核心代码和各厂商的驱动代码。
代码仓:https://git.kernel.org/pub/scm/linux/kernel/git/rdma/rdma.git/
RDMA社区
对于上层用户,IB提供了一套与Socket套接字类似的接口——libibverbs,前文所述三种协议都可以使用。参考着协议、API文档和示例程序很容易就可以写一个Demo出来。本专栏中的RDMA社区专指其用户态社区,在github上其仓库的名字为linux-rdma。
主要包含两个子仓库:
- rdma-core
用户态核心代码,API,文档以及各个厂商的用户态驱动。
- perftest
一个功能强大的用于测试RDMA性能的工具。
代码仓:https://github.com/linux-rdma/
UCX[5]
UCX是一个建立在RDMA等技术之上的用于数据处理和高性能计算的通信框架,RDMA是其底层核心之一。我们可以将其理解为是位于应用和RDMA API之间的中间件,向上层用户又封装了一层更易开发的接口。
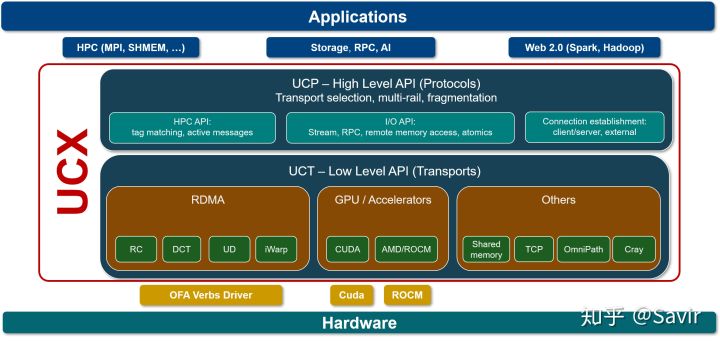
笔者对其并不了解太多,只知道业界有一些企业在基于UCX开发应用。
代码仓:https://github.com/openucx/ucx
其他知识
玩家
标准/生态组织
提到IB协议,就不得不提到两大组织——IBTA和OFA。
IBTA[3]
成立于1999年,负责制定和维护Infiniband协议标准。IBTA独立于各个厂商,通过赞助技术活动和推动资源共享来将整个行业整合在一起,并且通过线上交流、营销和线下活动等方式积极推广IB和RoCE。
IBTA会对商用的IB和RoCE设备进行协议标准符合性和互操作性测试及认证,由很多大型的IT厂商组成的委员会领导,其主要成员包括博通,HPE,IBM,英特尔,Mellanox和微软等,华为也是IBTA的会员。
OFA[4]
成立于2004年的非盈利组织,负责开发、测试、认证、支持和分发独立于厂商的开源跨平台infiniband协议栈,2010年开始支持RoCE。其对用于支撑RDMA/Kernel bypass应用的OFED(OpenFabrics Enterprise Distribution)软件栈负责,保证其与主流软硬件的兼容性和易用性。OFED软件栈包括驱动、内核、中间件和API。
上述两个组织是配合关系,IBTA主要负责开发、维护和增强Infiniband协议标准;OFA负责开发和维护Infiniband协议和上层应用API。
硬件厂商和用户
硬件厂商
设计和生产IB相关硬件的厂商有不少,包括Mellanox、华为、收购了Qlogic的IB技术的Intel,博通、Marvell,富士通等等,这里就不逐个展开了,仅简单提一下Mellanox和华为。
- Mellanox
IB领域的领头羊,协议标准制定、软硬件开发和生态建设都能看到Mellanox的身影,其在社区和标准制定上上拥有最大的话语权。目前最新一代的网卡是支持200Gb/s的ConnextX-6系列。
- 华为
去年初推出的鲲鹏920芯片已经支持100Gb/s的RoCE协议,技术上在国内处于领先地位。但是软硬件和影响力方面距离Mellanox还有比较长的路要走,相信华为能够早日赶上老大哥的步伐。
用户
微软、IBM和国内的阿里、京东都正在使用RDMA,另外还有很多大型IT公司在做初步的开发和测试。在数据中心和高性能计算场景下,RDMA代替传统网络是大势所趋。笔者对于市场接触不多,所以并不能提供更详细的应用情况。
下一篇将用比较直观的方式比较一次典型的基于Socket的传统以太网和RDMA通信过程。
未整理论文,摘自:https://blog.csdn.net/weixin_30307921/article/details/98227024
二、 使用的调研方式
- 中国知网搜索:搜到的论文质量较差,舍弃。故没有产生作用。
- RDMA技术标准制定方官网OpenFabrics Alliance – Innovation in High Speed Fabrics:用于了解技术原理。
- 一个有关RDMA的博客RDMAmojo - RDMAmojo - blog on RDMA technology and programming by Dotan Barak RDMAmojo:用于了解技术原理。
- 维基百科:使用频繁,主要用于查看术语定义。
- Google scholar搜索:主力,大部分论文由此获取。
- 查看论文作者的其他论文:查阅过程中发现Dhabaleswar K.DK Panda作者的名字常常出现,于是查了一下该作者的其他论文。
- 问师兄:非常频繁,帮助很大。
- 后来在中国科学技术大学罗昭锋老师放在科学网的一篇博文《引文分析软件histcite简介》的启发下利用histcite软件分析了Web of Science核心合集数据库中与RDMA相关的约500篇论文,并进行可视化
RDMA与TCP的比较
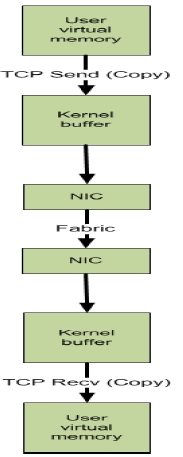
(图来自RDMA技术标准制定方官网OpenFabrics Alliance – Innovation in High Speed Fabrics的一个培训ppt)
成本上RDMA较贵:
10G普通网卡:Mellanox MCX341A-XCCN ConnectX-3 10Gigabit Ethernet Card
$170.00
Infiniband交换机:Mellanox MCS7510 66Tb/s, 324-port EDR Infiniband chassis switch, includes 12 fans and 6 power supplies (N+N), RoHS R6
$66,950.00
infiniband卡:Mellanox MCX456A-ECAT ConnectX VPI Infiniband Host Bus Adapter
$1,575.00
论文分类:
1.对RDMA读操作的研究
分析RDMA读操作不同情况下的利弊
Dragojevic A, Narayanan D, Castro M. RDMA Reads: To Use or Not to Use?[J]. IEEE Data Eng. Bull., 2017, 40(1): 3-14.
键值对应用中未使用读操作的方案
Kalia A, Kaminsky M, Andersen D G. Using RDMA efficiently for key-value services[C]//ACM SIGCOMM Computer Communication Review. ACM, 2014, 44(4): 295-306.
键值对应用中使用了读操作但做出改进的方案
C. Mitchell, Y. Geng, and J. Li. Using One-Sided RDMA Reads to Build a Fast,
CPU-Efficient Key-Value Store. In USENIX ATC, 2013.
分析发现在广域网上RDMA读操作性能较差
Yu W, Rao N S V, Wyckoff P, et al. Performance of RDMA-capable storage protocols on wide-area network[C]//Petascale Data Storage Workshop, 2008. PDSW'08. 3rd. IEEE, 2008: 1-5.
MPI应用中将Rendezvous Protocol的实现由写操作实现改为使用读操作实现。
Sur S, Jin H W, Chai L, et al. RDMA read based rendezvous protocol for MPI over InfiniBand: design alternatives and benefits[C]//Proceedings of the eleventh ACM SIGPLAN symposium on Principles and practice of parallel programming. ACM, 2006: 32-39.
提出的优化方案中避免RDMA单边操作(RDMA读/写)
Kalia A, Kaminsky M, Andersen D G. FaSST: Fast, Scalable and Simple Distributed Transactions with Two-Sided (RDMA) Datagram RPCs[C]//OSDI. 2016: 185-201.
这篇研究RDMA隐藏成本的分析中也有提及:
Author(s): Frey PW (Frey, Philip W.); Alonso G (Alonso, Gustavo)
Title: Minimizing the Hidden Cost of RDMA
Source: 2009 29TH IEEE INTERNATIONAL CONFERENCE ON DISTRIBUTED COMPUTING SYSTEMS : 553-+
Date: 2009
DOI: 10.1109/ICDCS.2009.32
2.对RDMA虚拟化,软件化的研究
这个方向在2011年被提出来一次,作者们研究设计了一个软件RDMA栈,并试图应用在商业云上。
Trivedi A, Metzler B, Stuedi P. A case for RDMA in clouds: turning supercomputer networking into commodity[C]//Proceedings of the Second Asia-Pacific Workshop on Systems. ACM, 2011: 17.
http://apsys11.ucsd.edu/papers/apsys11-trivedi.pdf
最近又有两篇论文关注这方面的问题:
虚拟化RDMA(新,2017年论文)
Fan S, Chen F, Rauchfuss H, et al. Towards a Lightweight RDMA Para-Virtualization for HPC[C]//COSH/VisorHPC@ HiPEAC. 2017: 39-44.
https://mediatum.ub.tum.de/doc/1344417/1344417.pdf
软件化RDMA。(新,2017年论文)
Mao Miao, Fengyuan Ren, Xiaohui Luo, Jing Xie, Qingkai Meng, and Wenxue Cheng. 2017. SoftRDMA: Rekindling High Performance Software RDMA over Commodity Ethernet. In Proceedings of the First Asia-Pacific Workshop on Networking (APNet'17). ACM, New York, NY, USA, 43-49. DOI: SoftRDMA | Proceedings of the First Asia-Pacific Workshop on Networking
3.对RDMA内存管理的研究
一个提高RDMA内存管理效率的方案(一个计算所老师的论文)
Ou L, He X, Han J. An efficient design for fast memory registration in RDMA[J]. Journal of Network and Computer Applications, 2009, 32(3): 642-651.
在MPI应用中一个提高RDMA内存管理效率的方案
Mamidala A, Vishnu A, Panda D. Efficient shared memory and RDMA based design for MPI_Allgather over infiniband[J]. Recent Advances in Parallel Virtual Machine and Message Passing Interface, 2006: 66-75.
设计了一个新协议来Overlap内存管理的开销,跟单边操作(读/写)也有关系
Woodall T, Shipman G, Bosilca G, et al. High performance RDMA protocols in HPC[J]. Recent Advances in Parallel Virtual Machine and Message Passing Interface, 2006: 76-85.
4.将RDMA应用于GPU的研究
以下四篇论文成如上图关系:
第一篇首先提出使用GPUDirect RDMA来实现 Inter-node MPI Communication:
Potluri S, Hamidouche K, Venkatesh A, et al. Efficient inter-node MPI communication using GPUDirect RDMA for InfiniBand clusters with NVIDIA GPUs[C]//Parallel Processing (ICPP), 2013 42nd International Conference on. IEEE, 2013: 80-89.
有3篇跟进:
Wang H, Potluri S, Bureddy D, et al. GPU-aware MPI on RDMA-enabled clusters: Design, implementation and evaluation[J]. IEEE Transactions on Parallel and Distributed Systems, 2014, 25(10): 2595-2605.
Hamidouche K, Venkatesh A, Awan A A, et al. Exploiting GPUDirect RDMA in Designing High Performance OpenSHMEM for NVIDIA GPU Clusters[C]//Cluster Computing (CLUSTER), 2015 IEEE International Conference on. IEEE, 2015: 78-87.
Banerjee D S, Hamidouche K, Panda D K. Designing high performance communication runtime for GPU managed memory: early experiences[C]//Proceedings of the 9th Annual Workshop on General Purpose Processing using Graphics Processing Unit. ACM, 2016: 82-91.
5.将RDMA应用于键值对存储的研究
这篇主要关注安全性问题:
Yang M, Yu S, Yu R, et al. InnerCache: A Tactful Cache Mechanism for RDMA-Based Key-Value Store[C]//Web Services (ICWS), 2016 IEEE International Conference on. IEEE, 2016: 646-649.
提高性能(在RDMA读操作部分中介绍过)
Kalia A, Kaminsky M, Andersen D G. Using RDMA efficiently for key-value services[C]//ACM SIGCOMM Computer Communication Review. ACM, 2014, 44(4): 295-306.
提高性能
C. Mitchell, Y. Geng, and J. Li. Using One-Sided RDMA Reads to Build a Fast,
CPU-Efficient Key-Value Store. In USENIX ATC, 2013.
这个主要是关注基于RDMA的键值对应用中固态硬盘和内存混合存储的问题
Shankar D, Lu X, Islam N, et al. High-Performance Hybrid Key-Value Store on Modern Clusters with RDMA Interconnects and SSDs: Non-blocking Extensions, Designs, and Benefits[C]//Parallel and Distributed Processing Symposium, 2016 IEEE International. IEEE, 2016: 393-402.
6.将RDMA应用于关系数据库的研究
共享内存避免读硬盘,从而提升性能
Li F, Das S, Syamala M, et al. Accelerating relational databases by leveraging remote memory and RDMA[C]//Proceedings of the 2016 International Conference on Management of Data. ACM, 2016: 355-370.
引入MySQL
Shankar D, Lu X, Jose J, et al. Can RDMA benefit online data processing workloads on memcached and MySQL?[C]//Performance Analysis of Systems and Software (ISPASS), 2015 IEEE International Symposium on. IEEE, 2015: 159-160.
加速数据库join操作
Barthels C, Loesing S, Alonso G, et al. Rack-scale in-memory join processing using RDMA[C]//Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data. ACM, 2015: 1463-1475.
两篇都是利用RDMA和HTM设计新的Transactions progress system ,作者也一样
Wei X, Shi J, Chen Y, et al. Fast in-memory transaction processing using RDMA and HTM[C]//Proceedings of the 25th Symposium on Operating Systems Principles. ACM, 2015: 87-104.
Chen Y, Wei X, Shi J, et al. Fast and general distributed transactions using RDMA and HTM[C]//Proceedings of the Eleventh European Conference on Computer Systems. ACM, 2016: 26.
加速分布式Transactions时避免了RDMA单边操作
Kalia A, Kaminsky M, Andersen D G. FaSST: Fast, Scalable and Simple Distributed Transactions with Two-Sided (RDMA) Datagram RPCs[C]//OSDI. 2016: 185-201.
7.将RDMA应用于大数据系统的研究
将RDMA引入Spark提高性能
Lu X, Rahman M W U, Islam N, et al. Accelerating spark with RDMA for big data processing: Early experiences[C]//High-performance interconnects (HOTI), 2014 IEEE 22nd annual symposium on. IEEE, 2014: 9-16.
与上篇工作类似
Yan X, Wong B, Choy S. R3S: RDMA-based RDD Remote Storage for Spark[C]//Proceedings of the 15th International Workshop on Adaptive and Reflective Middleware. ACM, 2016: 4.
用RDMA解决MapReduce,Spark和HBase的主要存储引擎HDFS的I/O瓶颈,从而提升性能
Islam N S, Rahman M W, Jose J, et al. High performance RDMA-based design of HDFS over InfiniBand[C]//Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis. IEEE Computer Society Press, 2012: 35.
这篇与上篇工作类似
Woodall T, Shipman G, Bosilca G, et al. High performance RDMA protocols in HPC[J]. Recent Advances in Parallel Virtual Machine and Message Passing Interface, 2006: 76-85.
引入Hadoop后的性能分析
Lu X, Islam N S, Wasi-Ur-Rahman M, et al. High-performance design of Hadoop RPC with RDMA over InfiniBand[C]//Parallel Processing (ICPP), 2013 42nd International Conference on. IEEE, 2013: 641-650.
设计了一个插件库帮助Hadoop使用RDMA
Wang Y, Xu C, Li X, et al. JVM-bypass for efficient Hadoop shuffling[C]//Parallel & Distributed Processing (IPDPS), 2013 IEEE 27th International Symposium on. IEEE, 2013: 569-578.
8将RDMA应用于NFS的研究
引入RDMA提高性能,并解决了一个安全性问题。
Noronha R, Chai L, Talpey T, et al. Designing NFS with RDMA for security, performance and scalability[C]//Parallel Processing, 2007. ICPP 2007. International Conference on. IEEE, 2007: 49-49.
将RDMA作为NFS的传输层提高性能
Callaghan B, Lingutla-Raj T, Chiu A, et al. Nfs over rdma[C]//Proceedings of the ACM SIGCOMM workshop on Network-I/O convergence: experience, lessons, implications. ACM, 2003: 196-208.
分析发现基于RDMA的NFS在广域网上性能较差,由于广域网上RDMA读操作性能较差
Yu W, Rao N S V, Wyckoff P, et al. Performance of RDMA-capable storage protocols on wide-area network[C]//Petascale Data Storage Workshop, 2008. PDSW'08. 3rd. IEEE, 2008: 1-5.
9. 将RDMA应用于MPI的研究
Liu J, Wu J, Panda D K. High performance RDMA-based MPI implementation over InfiniBand[J]. International Journal of Parallel Programming, 2004, 32(3): 167-198.
Sur S, Jin H W, Chai L, et al. RDMA read based rendezvous protocol for MPI over InfiniBand: design alternatives and benefits[C]//Proceedings of the eleventh ACM SIGPLAN symposium on Principles and practice of parallel programming. ACM, 2006: 32-39.
- 10. 杂
还有一些研究RDMA编程,给web协议提速,在(IBMHPS (High Performance Switch and adapter)上实现RDMA等等


















 2829
2829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









