







前言
看介绍,像是mellonx针对其kernel bypass网卡(RDMA网卡)提供的一个lib库,该lib库对外提供socket api,使得用户的程序不需要修改就可以直接使用kernel bypass网卡(如RDMA网卡)。
我们都知道RDMA 网卡目前使用的是rdma_cm和vbers api编程,和socket不一样,如果能用socket对RDMA编程,那确实是很大的利好。
官网介绍
什么是VMA?Mellanox Interconnect Community
官方介绍:
Mellanox的信息加速器(VMA)提高了基于信息和流的应用的性能,如金融服务、媒体和娱乐、数据库和数据流应用中的性能。其结果是将延迟降低到微秒以下,将吞吐量提高到100GbE线速。
VMA是一个开源库项目,提供标准sokect API 接口,实现kernel-bypass 架构, 在用户空间可以多播,UDP单播和TCP流。 VMA还具有易用,内置预配置配置文件(例如(配置)延迟或流)等特性。
参考资料:
架构:
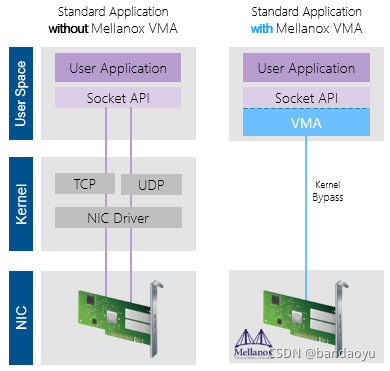
什么是vma?
内核旁路 - 程序绕过内核直达网卡降低CPU负担。
不需要任何应用程序更改 - 向应用程序层提供标sockets TCP,UDP(单播,组播),使用socket接口编程
Mellanox VMA带来的利好
降低延迟 - 使用UDP / TCP小于1.3微秒
较低的抖动 - 减少的上下文切换和中断优化应用程序网络抖动
降低CPU利用率 - 较少的开销和更优化提供CPU效率
高吞吐量 - 达到100gbe的线速率
vma降低延迟

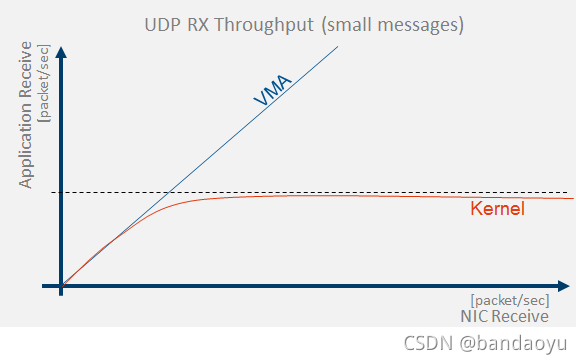
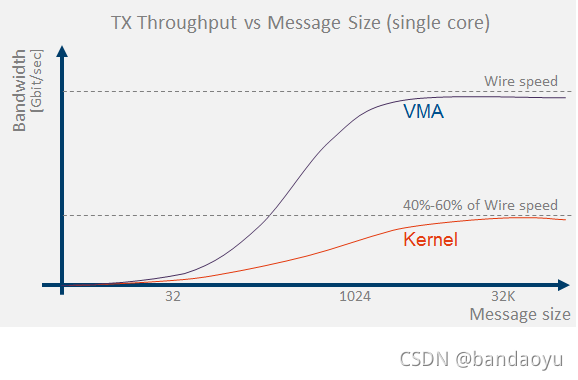
VMA带来内核内核无法达到的性能(说明性)
内核无法给应用层带来(高)吞吐量。通过绕过内核 - VMA能够实现RX和TX的(高)吞吐量。
ULP(Upper Layer Protocols)
RDMA Consortium 和 IBTA 主导了RDMA,RDMAC是IETF的一个补充,它主要定义的是iWRAP和iSER,IBTA是infiniband的全部标准制定者,并补充了RoCE v1 v2的标准化。应用和RNIC之间的传输接口层(software transport interface)被称为Verbs。IBTA解释了RDMA传输过程中应具备的特性行为,而并没有规定Verbs的具体接口和数据结构原型。这部分工作由另一个组织OFA(Open Fabric Alliance)来完成,OFA提供了RDMA传输的一系列Verbs API。OFA开发出了OFED(Open Fabric Enterprise Distribution)协议栈,支持多种RDMA传输层协议。
OFED中除了提供向下与RNIC基本的队列消息服务,向上还提供了ULP(Upper Layer Protocols),通过ULPs,上层应用不需要直接到Verbs API对接,而是借助于ULP与应用对接,常见的应用不需要做修改,就可以跑在RDMA传输层上。

















 2007
2007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









