





目录
摘要
远程直接内存访问(RDMA)和非统一内存访问(NUMA)是现代高性能计算平台的关键技术。RDMA允许节点直接访问远程机器上的内存,而多处理器架构使用NUMA来提升内存访问性能。当这两种技术结合时,在某些配置下会导致性能下降。
本文首次探讨了这些配置,并提供了关于NUMA对基于RDMA系统性能影响的定量研究结果。研究表明,对于超快网络而言,NUMA本地性的影响在启用RDMA的分布式系统的性能影响更大。研究量化了其角色并揭示了意想不到的行为。
总之,远程可访问内存的NUMA本地性差可能导致自动20%的性能下降。此外,根据内存本地性的不同,操作远程可访问内存的本地工作负载可能会导致高达300%的性能差距。
我们使用两代RDMA卡、一个合成基准测试和Memcached对我们的发现进行了验证。
关键词:RDMA、NUMA、性能、局部性
一、前言
(简介RDMA是什么)……,本文首次对RDMA单边通信与NUMA(非均匀内存访问)一起部署时的性能影响进行了实证研究。NUMA被公认是对基于RDMA系统的挑战[13, 41],但目前还没有全面的研究来显示单边操作的性能影响。
(简介NUMA技术)……,我们的研究有三个动机:
-
首先,RDMA和NUMA是属于所有高性能计算基础设施的两种技术,并且它们在未来仍将存在,因为NUMA被广泛采用,而RDMA的能力正在多种环境中迅速被探索[3, 14, 25, 28, 36, 39, 41]。
-
其次,单边操作是RDMA的真正创新,并且具有与本地服务器计算无关的独特特性。这是因为RDMA上的内存传输 不需要 接收内存的服务器CPU参与;RNIC(网卡)自主操作。这种设计的意味着远程操作与本地服务器共享硬件资源,因此硬件争用可能影响其性能,但本地服务器无法控制或看到该操作,因此运行时优化被禁止(例如,NUMA平衡[2])。
-
第三,越来越多的分布式数据存储库(例如[22])倾向于将数据和元数据存储在内存中,同时使用复制来确保容错性和可用性。因此,理解NUMA对RDMA的影响对于后续改进至关重要。
体现上述结论的一个例子如下。假设集群中有两个节点N1和N2,在节点N2上运行的应用程序线程T。当T对存储在N1上的内存位置执行读或写操作时,它执行单边操作,该操作由N1的RNIC(网卡)直接处理,无需N1的操作系统(cpu)参与。T的内存操作性能取决于以下因素:
- 请求内存的NUMA局部性;
- 在N1上执行的工作负载,可能会占用大量内存(内存密集型),并(过度)使内存层级系统(不堪重负)。
这些因素T或N1 都没法控制,既T的操作可能会因为T和N1N1都无法控制的原因而变慢。
为了进行研究,我们开发并测试了一个微基准测试和移植到RDMA的知名应用程序Memcached[16]。我们开发前者是为了在NUMA存在的情况下隔离RDMA的行为。我们使用后者来展示我们微基准测试中分析的聚合效应。我们的配置 是以调查Facebook得到的真实配置,该调查表明大部分键值操作的目标数据小于64字节。
我们发现的简要总结如下:
- 对于无负载的系统,访问与RNIC位于同一NUMA区域的内存可以带来10-20%的性能提升;
- 在本地工作负载下,NUMA本地访问的性能可能比NUMA远程访问差300%;
- 内存密集型独立工作负载在与远程可访问内存位于同一NUMA区域时,性能可能降低多达50%。
……虽然本评估研究中使用的硬件不是最新的,但我们认为我们的结果在较新的设备中只会变得更加明显。这是因为NUMA的制约是固定的。随着RDMA的访问时间趋向于本地访问的上限,跨处理器互连的额外跳数所代表的相对成本更高。目前10%-20%的性能下降意味着在更快的RNIC下会有更高的损失。
……我们的研究为以更具针对性的方式(而非完全通用的方式)利用RDMA单边交互与NUMA服务器协同工作开辟了令人兴奋的新方向,从而能够优化远程访问性能而非使其受到制约。
我们实现的源代码可在[https://github.com/sss-lehigh/nurdma
二、背景
(RDMA和NUMA的简介)……。
非均匀内存访问
(NUMA说明)……,
图1展示了NUMA架构机器的高层结构。每个处理器关联一个物理内存模块,但所有系统内存均可通过内存互连访问。由于NUMA远程访问较慢,应用程序最佳实践是通过将页面绑定到NUMA本地内存来保持数据局部性。某些操作系统使用NUMA平衡技术[2],透明地将线程和内存安置在同一区域。
本图仅展示两个NUMA区域,但现代处理器(如Intel Xeon E7 8800系列)可支持最多八插槽配置[18]。随着插槽数量增加,跨插槽消息可能需要多次跳转才能到达目的地,加剧NUMA远程内存访问问题。
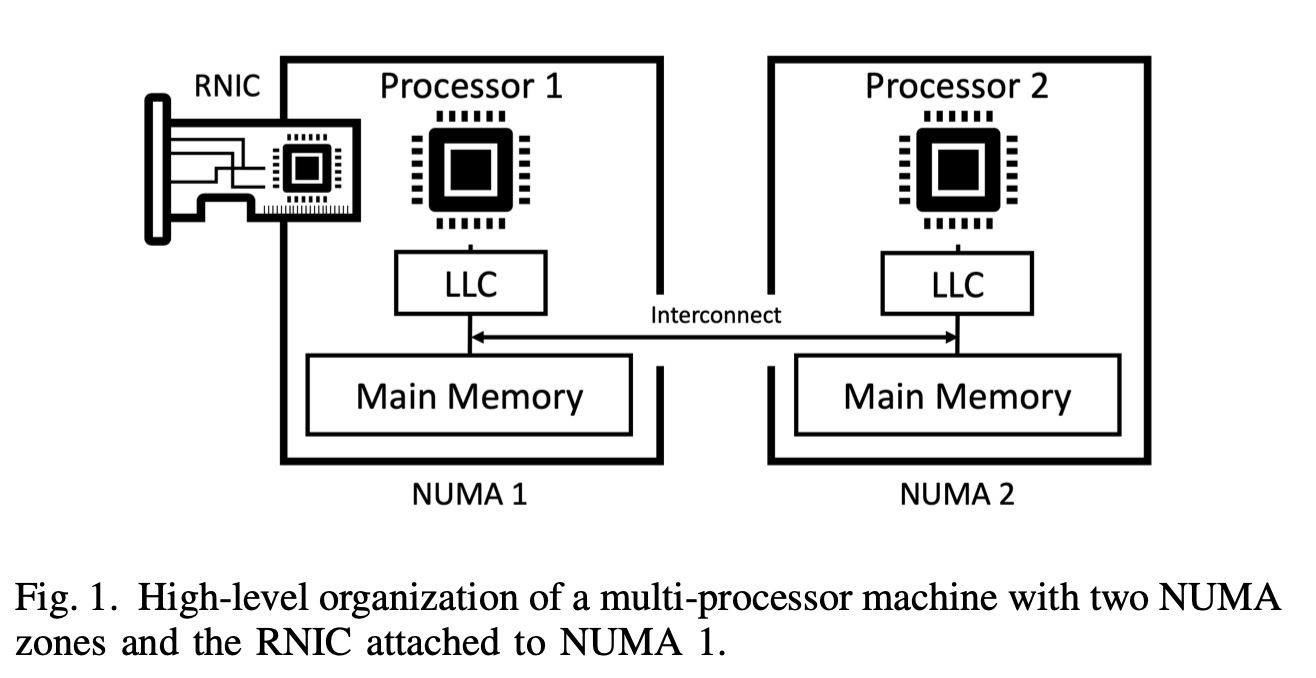
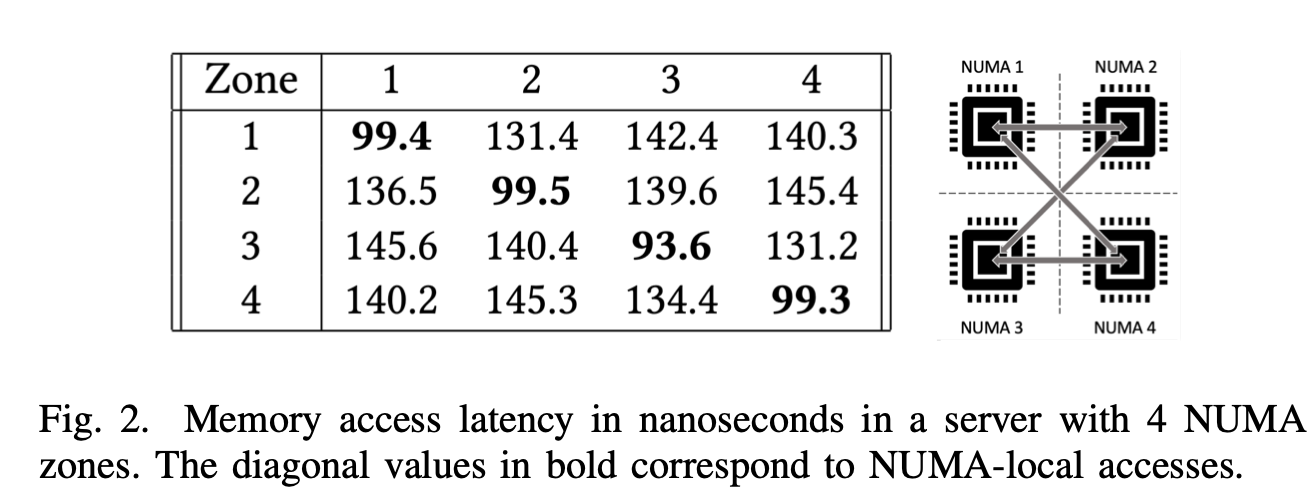
图2的表格展示了配备Intel Xeon Platinum 8160处理器的四插槽机器(共192核心)的内存访问延迟结果,单位为纳秒。
NUMA架构的一个衍生特性是I/O操作也被绑定到特定区域,这在网络计算中起到重要作用。外部设备通过物理连接至某个NUMA区域的网卡与处理器通信(II-C节将对此机制展开详细说明)。其结果是:当设备发起内存访问请求,而目标地址对应的物理页面位于NUMA远程内存区域时,该请求必须通过互连结构才能完成服务。正如我们在评估中将看到的,尽管网络延迟与(NUMA间)互连延迟存在数量级差异,但这种机制仍可能对RDMA性能产生影响。
远程直接内存访问
(介绍RDMA的单边操作和双边操作)……,
如前所述,由于单边操作与机器的操作系统无关,并且同时它们与本地操作系统和应用程序共享相同的物理硬件资源,它们的性能可能会受到 请求应用程序或接收机器上的软件在运行时都无法优化的因素的显著影响。
这种透明性(既RDMA操作内核不参与)的一个后果是,无法使用NUMA平衡优化[2]在NUMA区域之间移动内存页面,因为页面在RDMA初始化时已经注册内存操作被锁定。
NUMA和RDMA I/O
现代架构提供了一种机制,使I/O能直接访问末级缓存。例如,本研究使用的Intel机器采用数据直接I/O(DDIO)技术实现直接缓存访问。鉴于现代I/O速度和缓存容量,允许I/O访问缓存以避免额外开销是切实可行的。此前,输入数据需先写入主存,再由本地访问将其读入缓存。通过DDIO等技术,缓存内存访问的I/O延迟得到改善,I/O直接将数据存入缓存也让本地计算受益。
该技术旨在透明化地优化I/O操作的延迟和吞吐量。然而需特别指出,当前这种优化仅适用于与I/O控制器同属一个NUMA区域的缓存,且默认启用。远程NUMA区域的物理内存仍通过常规直接内存访问(DMA)进行访问[18]。正如我们将在评估中讨论的,这种行为可能对RDMA产生不利影响,进而对性能造成负面影响。
三、相关工作
(介绍RDMA和NUMA在高速系统中的应用)……,部分工作虽涉及NUMA局部性问题,并尝试通过绑定内存和线程到RNIC(网卡)本地NUMA区域来缓解影响,但均未对两种技术的关联及综合性能影响进行深入研究。
(介绍有人研究RDMA机制和优化,但未讨论远程内存的NUMA局部性问题)……,
近期分布式系统常结合RDMA互连和大容量多核服务器测试性能,典型例子包括FaRM[14]、HydraDB[39]和DrTM[40]。FaRM使用两个RNIC,要求线程仅与同NUMA区域的RNIC交互。为解决扩展性问题,FaRM允许线程间共享队列对(QP)传递消息,但仅允许同NUMA区域线程共享QP。HydraDB通过内存与服务器处理线程共置、在多插槽机器部署多实例来实现NUMA感知。DrTM在NUMA区域间显式划分TPC-C基准测试,使所有工作集中在单个区域。这些案例虽承认NUMA局部性影响,但均采取保守策略,未量化其具体影响。
FaSST是一个基于RPC和双边通信实现的分布式内存事务系统[22],为单边与双边RDMA操作的成本效益分析提供了重要补充视角。根据源代码推测,FaSST与FaRM、DrTM类似,通过将资源绑定到RNIC所在NUMA区域来优化性能。
目前我们所知对NUMA与RDMA关系最明确的讨论来自Wu等人[41]。他们基于FaRM消息传递机制设计了分布式图引擎GRAM,研究结果表明,将消息缓冲区与接收线程置于同一NUMA区域可使性能提升40%。在这里,非统一内存访问(NUMA)的实测开销源于本地线程对内存进行访问时的局部性,而非由网卡(RNIC)执行的内存访问。(Here the measured cost of NUMA stems from locality with respect to the local threads that access the memory, not the memory access performed by the RNIC)。本文评估研究将探讨后者,即NUMA局部性对RDMA单边操作本身性能的影响。
与FaRM类似,Ren等人[34]通过按NUMA区域划分数据,并使用多个绑定到各区域的RNIC路由访问请求,从而规避NUMA效应。但这种方法导致所需RNIC数量成倍增加,部分硬件可能不支持且成本更高。
另一种解决方案是Mellanox的Socket Direct技术,通过将16x PCIe连接拆分为两个8x插槽配置,在NUMA区域间共享单个RNIC[26]。该技术允许两个处理器插槽共享RNIC且避免跨插槽通信,但存在两个局限:首先,单个插槽带宽因PCIe通道减少而减半;其次,当系统包含多个NUMA区域时,本文讨论的问题依然存在。
其他研究注意到NUMA架构与RDMA分布式系统的相似性,提出基于RDMA的分布式共享内存实现[3]。其核心思想是在设计算法时将远程内存视为NUMA节点。与本文不同,该研究未探讨内存局部性带来的性能损失及NUMA与RDMA的相互作用。
NUMA的固有特性意味着彻底消除其代价需要重新思考基础架构决策。IOctopus[37]是近期尝试通过重新设计PCIe设备架构来缓解本文评估中所述问题的解决方案。即便如此,在拟议的PCIe框架下,RDMA与DDIO在NUMA本地内存上产生的意外行为仍可能无法避免,且该方案尚无商用产品。
据我们所知,当前普遍做法是保守地将远程可访问内存分配在RNIC物理连接的NUMA区域。这种设计将计算能力限制在调度到该区域的核/线程,且无法进行进一步优化。本文揭示了两种技术的耦合关系,为未来的系统充分释放各自潜力提供了理论依据。
四、实验设置
我们的分析始于一个客户端 - 服务器微基准测试,该测试旨在捕捉我们所关注的两个硬件组件之间的微妙交互。在理解了非统一内存访问(NUMA)对单边操作的远程直接内存访问(RDMA)性能的实际影响后,我们接着证明在更复杂的场景中,NUMA 局部性确实会对性能产生影响。我们选择基于 RDMA 实现的 Memcached [20] 来探索在实际环境中 NUMA 的影响。微基准测试用于分离现象以理解基本交互;基于 RDMA 的 Memcached 则代表了更复杂应用的行为。
A. 局部性
在深入进行评估研究之前,我们首先定义一些术语,以明确我们对局部性的概念。我们假设每台机器采用以远程网络接口控制器(RNIC)为中心的 NUMA 视角。换句话说,RDMA 本地指的是 RNIC 通过 PCIe 总线连接的 NUMA 区域。内存也可以是 NUMA 本地的,这意味着它在物理上与访问线程所在的 NUMA 区域相同。此外,对于给定节点,资源也可以是本地或远程的。
为了说明这一点,考虑一个如图 1 所示的双 NUMA 系统,它由 NUMA 区域 N1 和 N2 组成。假设 RNIC 连接到 N1,那么该区域内的任何资源都被视为 RDMA 本地资源。N2 中的资源则被视为 RDMA 远程资源。此外,如果线程 T1 在 N2 上运行,那么 T1 可以访问位于 N2 的 NUMA 本地内存。最后,如果客户端读取(写入)服务器 N2 上的内存,我们将其称为对 RDMA 远程内存的 RDMA 读取(写入)。
B. 测试平台配置
硬件交代:
在接下来的实验中,我们使用的节点由两颗英特尔至强 E5 - 2670 v3 处理器组成,每台机器共有 48 个核心。对于每个物理核心,L1 数据缓存为 32 KB,L2 缓存为 256 KB,并且所有核心共享一个 30 MB 的 L3 缓存。系统中的所有节点都运行 Ubuntu 16.04 操作系统,并配备了一个 Mellanox ConnectX - 3 单端口 RDMA 适配器,通过 56 Gbps 的 InfiniBand 网络连接。所有实验都使用适用于 Linux 的 Mellanox 驱动程序 4.5 版本以 C++ 语言实现。
除了在 ConnectX - 3 上测试我们的结果外,我们还在下一代 RNIC 上验证那些更令人惊讶的发现,以确保结果的一致性。在现代 RNIC 测试平台中,每台机器有两颗 10 核的英特尔至强 E5 - 2650 v3 处理器,其高层级缓存大小与之前的设置相同,有一个 25 MB 的 L3 缓存和一个 Mellanox ConnectX - 4。
我们没有探索每台机器连接多个 RNIC 的配置,因为我们认为这会使我们的研究结果变得模糊。实际上,可以连接多个 RNIC,每个 RNIC 物理上连接到不同的 NUMA 区域。如第三节所述,常见的方法是为多个 RNIC 静态分配软件资源,以解决我们评估研究中所强调的一些问题。然而,即使采用这种设计,大型多处理器系统也可以轻松部署 8 个 NUMA 区域。为每台机器配备 8 个 RNIC 成本会显著增加,并且仍不会改变我们的研究结果。
C. 工作负载特性
第一组实验:所有资源绑定到 RDMA 本地 NUMA 区域
在最初的一组实验中,我们假设客户端运行在有利的配置下。也就是说,我们将所有资源绑定到 RDMA 本地 NUMA 区域,这样它就不会因 NUMA 局部性而产生任何开销。在这个假设下,我们将任何行为结果归因于远程可访问内存位置的变化或服务器工作负载。在第六节评估基于 RDMA 的 Memcached 时,我们会解决客户端对 NUMA 感知不足的问题。
io大小在8 到 64 字节之间
根据我们的初步结果,我们将访问大小固定在 8 到 64 字节之间。Atikoglu 等人报告称,在 Facebook 的键值存储中,对于最常见的工作负载,大多数键和值的大小小于 64 字节 [4]。另一类工作负载仅由键为 16 或 21 字节、值为 2 字节的请求组成。因此,我们的配置能够代表实际工作负载。Nishtala 等人 [30] 也报告了类似的统计数据,并且小键和值的大小被用于测试众多先进的键值存储设计 [13, 15, 22]。
QP 的数量限制在少于 32 个
如第二节 B 部分所述,单边通信需要为每个连接分配专用的队列对(QP)。避免 RNIC 在 QP 状态上的缓存未命中是高性能 RDMA 已知的优化方法 [21]。在接下来的实验中,我们将 QP 的数量限制在少于 32 个,以在不被 RNIC 缓存未命中或 RNIC 资源竞争干扰结果的情况下探究其行为。同样,我们分配小于一个页面的远程可访问缓冲区,以避免 RNIC 地址转换开销。如果需要大内存区域,可以使用更大的页面来达到相同的效果 [13]。
五、微基准测试
我们进行微基准测试的主要目标是凸显单边操作中远程直接内存访问(RDMA)与非统一内存访问(NUMA)之间的基本交互情况。
RDMA初始化:
在初始化阶段,服务器会为远程操作创建一个共享内存区域,并在一个套接字上监听客户端的连接请求。一旦接收到连接,服务器会将虚拟地址和访问密钥发送给客户端,以便客户端可以开始进行 RDMA 操作。客户端和服务器会再次通过套接字进行同步,以确保初始化完成,然后客户端开始对服务器上的缓冲区发起远程访问。
在实际应用场景中,服务器上可能会运行其他进程,这些进程要么与存储在远程可访问缓冲区中的数据进行交互,要么作为独立的应用程序运行。我们通过在服务器上同时运行合成工作负载或引入负载线程来模拟这两种行为。在这两种情况下,内存访问和套接字间通信都会影响远程单边操作的性能。正如我们将在第五节 D 部分展示的那样,当服务器节点引入本地工作负载时,架构设计可能会对性能产生惊人的影响。
在每个实验中,每个客户端连接都会向服务器发起 100 万次操作,在此期间我们会记录每个客户端的延迟或吞吐量。吞吐量的测量方式是取执行期间 10 毫秒长的瞬时吞吐量的平均值。在测量延迟时,我们在发起 RDMA 操作后立即轮询完成情况,然后计算每个客户端的平均值和标准差,并报告所有客户端的总体平均值。对于吞吐量,我们在运行过程中对每个连接的结果进行平均(通常包含 200 个样本),然后将每个客户端的平均吞吐量相加,报告系统的总吞吐量。
尽管整个内存区域在队列对(QP)之间是共享的,但写入操作不会产生冲突。这样做是为了明确确保客户端不会因访问相同的内存地址而直接相互干扰。因此,服务器上为远程访问分配的内存量等于连接数乘以每次访问的大小。对于较小的访问大小,可能会出现伪共享的情况。每个连接会写入不相交但相邻的地址,并且内存区域的起始地址是按缓存行对齐的。
A. 单个操作延迟
作为后续实验的初步动机,我们首先测量客户端单边读操作和写操作的延迟,将其作为 NUMA 局部性的函数。这个简单实验的目的是在控制其他额外因素(如服务器本地工作负载)的情况下,了解 NUMA(如果有的话)对性能的基线影响。在这个实验中,客户端发起 64 字节请求,在 100 万次闭环迭代中测量延迟,64 字节对应于缓存一致性 I/O 操作的最大单次写入量,并且可以避免伪共享。
1)假设:
我们假设当远程访问的缓冲区位于 RDMA 远程 NUMA 区域时,读操作的延迟会增加,这主要是因为需要穿越套接字间的连接。另一方面,写操作在到达服务器的远程网络接口控制器(RNIC)时就会得到确认,因此我们预计在两个 NUMA 区域中写操作的延迟相似。
2)研究结果
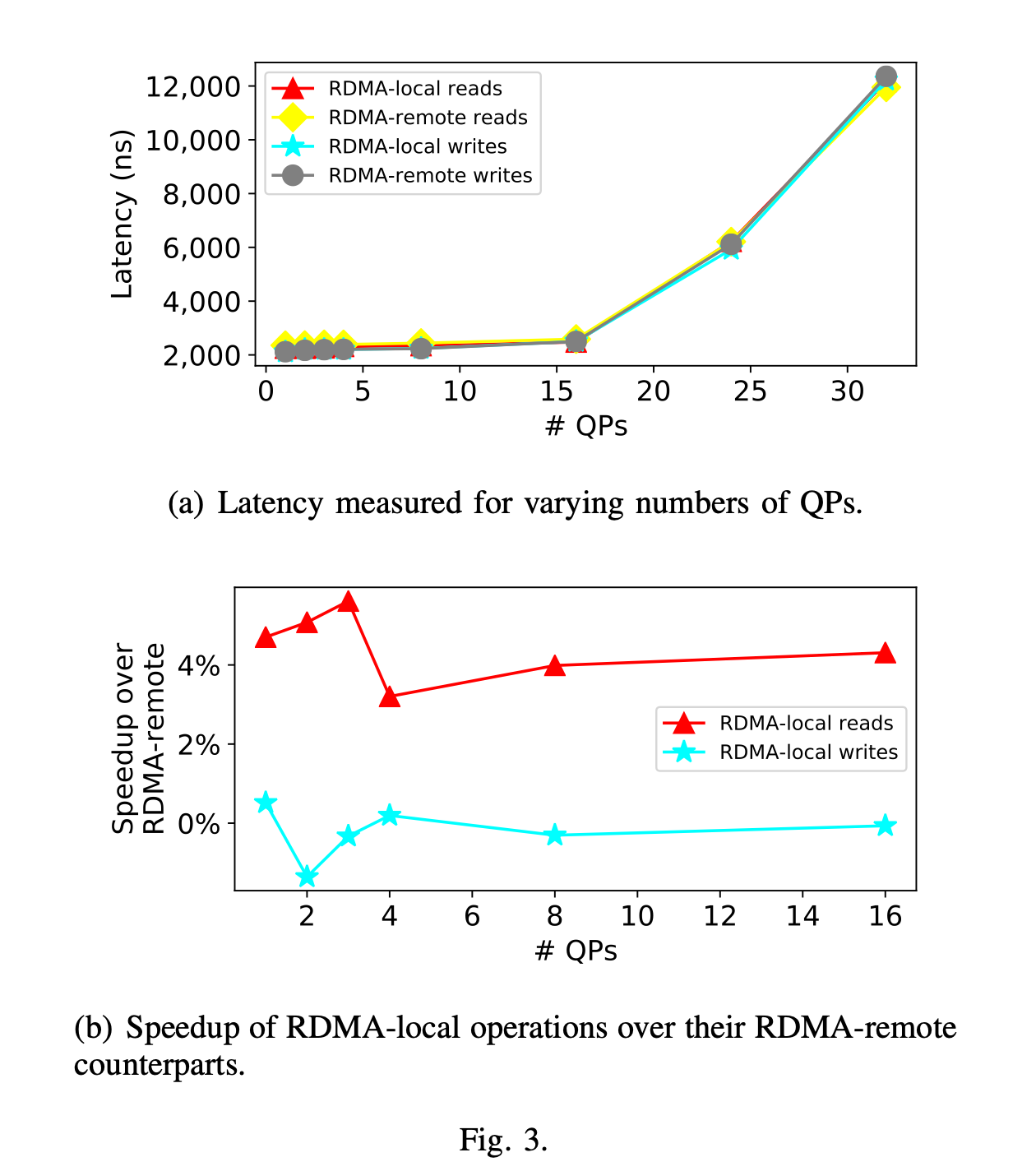
图 3(a)展示了 RDMA 本地操作和 RDMA 远程操作的延迟测量结果。为了说明远程操作如何影响远程机器的内存层次结构,服务器上未运行任何工作负载。
从该图中我们可以看到,当使用超过 16 个队列对(QP)时,延迟会急剧上升。我们认为这种现象是由 RNIC(远程网络接口控制器-RDMA网卡)的固有局限性导致的,这些局限性涉及并行执行单元的数量以及较小的缓存 [13]。当 QP 数量限制在 16 个或更少时,我们观察到网络适配器上的额外负载并不会显著改变延迟。
每次操作的往返延迟方面,RDMA 本地读取的延迟范围为 2.3 微秒至 2.5 微秒,RDMA 远程读取的延迟范围为 2.4 微秒至 2.6 微秒,而 RDMA 本地写入和 RDMA 远程写入的延迟范围均为 2.1 微秒至 2.5 微秒。读取操作比写入操作慢,因为需要返回数据。相比之下,一旦服务器的 RNIC 接收到写入请求,就会立即生成写入确认。
图 3(b)展示了在最多使用 16 个 QP 的情况下,RDMA 本地操作相对于 RDMA 远程操作的延迟加速比。我们的简单测试显示,当被访问的内存区域位于 RDMA 远程 NUMA(非统一内存访问)区域时,RDMA 读取的延迟会持续增加 3% - 5%。我们使用英特尔的内存延迟检查器(MLC)工具 [19] 测量本地访问时间,以此估算直接数据输入输出(DDIO)和套接字互连对延迟的影响。与表 2 类似,我们测量了服务器节点的本地访问延迟,同时还记录了三级缓存(L3)命中延迟。如前文所述,当内存与 I/O 不在同一 NUMA 区域时,DDIO 不会使用缓存一致性操作。在我们的机器上,NUMA 区域内的本地 L3 访问延迟为 38 纳秒,这可以估算出 RDMA 读取过程中在内存层次结构中花费的时间。对 NUMA 远程内存的访问延迟为 122 纳秒。就 RDMA 而言,相对于 2.3 微秒的基准 RDMA 本地内存读取延迟,我们观察到的 3.6% 的差异是由于需要穿越套接字互连并访问内存而非利用缓存造成的。图 3(b)还显示,正如预期的那样,写入操作之间没有显著差异。
尽管 NUMA 的影响相对较小,但却是持续存在的。在所有使用 16 个或更少 QP 的运行中,标准偏差小于平均延迟的 0.01%。在后续实验中,我们将证明,在存在独立工作负载的情况下,延迟增加 3.5% 可能会导致吞吐量下降 10% - 20%。我们观察到一个奇特的结果:当 QP 数量超过 8 个时,访问延迟呈现双峰分布。最初创建的 7 个 QP 的平均延迟低于其余 QP。当仅使用 16 个 QP 时,这种差异较小。然而,当使用 24 个 QP 时,延迟差异为 5000 纳秒,使用 32 个 QP 时,延迟差异为 12000 纳秒。由于我们尚未完全了解 RNIC 的内部机制,所以避免对这种现象的原因进行猜测,不过我们怀疑这与缓存 QP 上下文以及 RNIC 如何将 QP 调度到其执行单元有关。无论如何,在所有后续实验中,我们将注意力转向吞吐量。这种配置有助于在不引入额外瓶颈(如 RNIC 本身)的情况下展示性能特征。
B. 不同 RDMA 访问IO大小的吞吐量
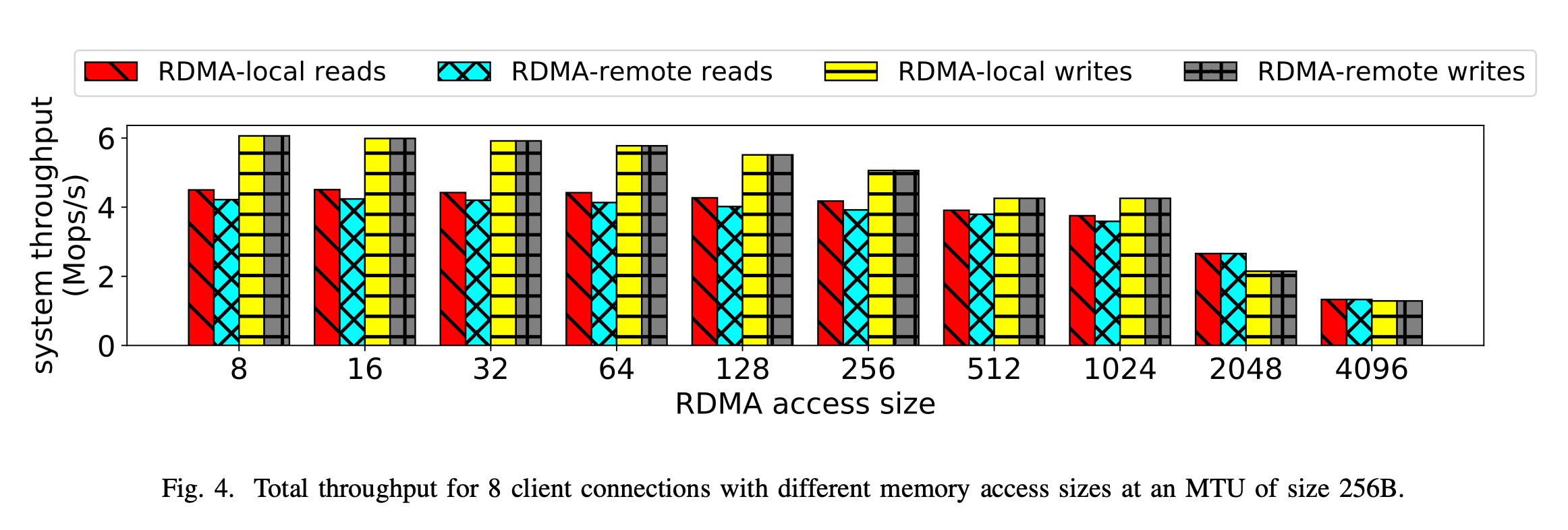
展示 NUMA 局部性作为访问大小的函数所产生的影响,有助于基于 RMDA 的系统设计,尤其是那些具有细粒度内存访问的系统。在我们所有的实验中,最大传输单元(MTU)为 256 字节,这是 ConnectX - 3 可配置的最小 MTU,也对应于 RNIC 配置的 256 字节的最大 PCIe 有效负载大小。
假设
对于 RDMA读操作,与我们的延迟实验类似,我们预计 RDMA 远程访问的性能会下降。然而,由于采用开环执行模型,并发客户端产生的负载如今成为了一个影响因素。预计额外的 I/O 操作会加剧 NUMA局部性的影响,因为远程内存层次结构将被加载。同样,当写入操作被远程机器的 RNIC(RDMA网卡)接收时就会得到确认,因此我们预计 NUMA 不会产生影响。
研究结果
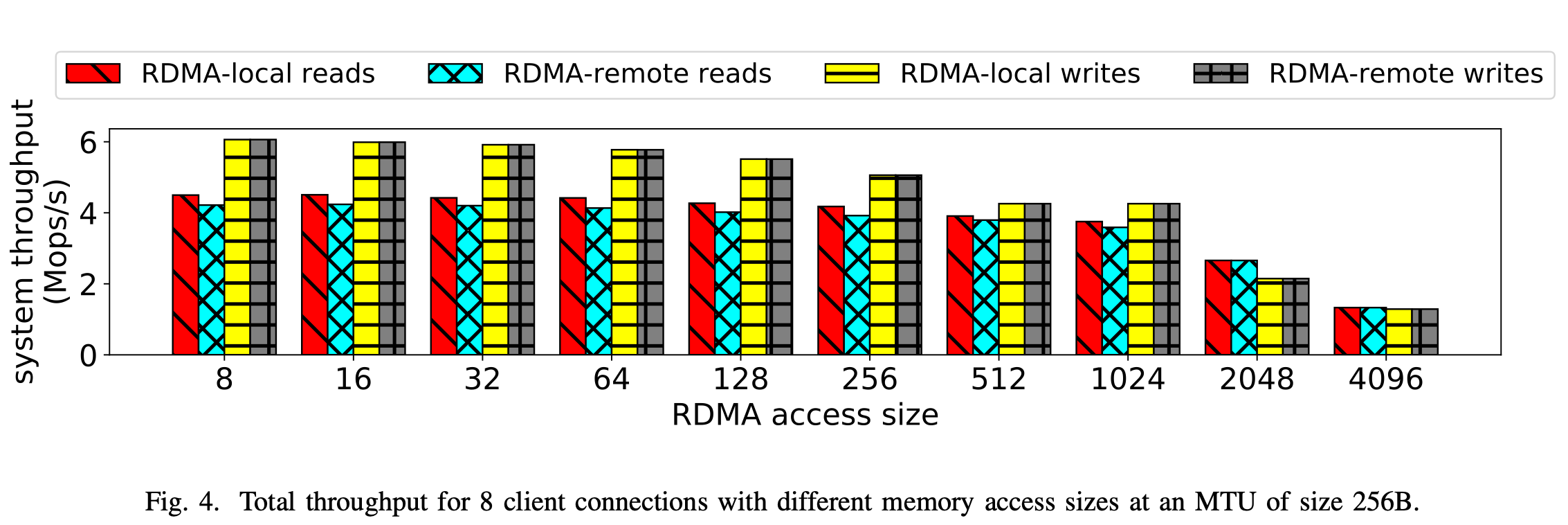
图 4 展示了 8 个客户端在 RDMA 访问IO大小增加时的系统吞吐量。与我们的延迟实验类似,RDMA 写操作的吞吐量不受 NUMA 局部性的影响。另一方面,当进行 RDMA 远程访问时,RDMA 读操作的吞吐量始终会降低 5 - 7%。需要注意的是,当消息被分段时(即大小大于 256 --大于网卡mtu),NUMA 局部性不会影响吞吐量。这是因为网络通信所花费的时间更多,从而掩盖了 RDMA 远程访问的影响。
另一个观察结果是,随着访问大小的增加,RDMA 读操作和 RDMA 写操作之间的差异会逐渐减小。换句话说,不同大小的内存访问对读操作和写操作的影响不同。在 8 字节到 1024 字节的访问范围内,RDMA 读操作能保持超过 80% 的吞吐量,而 RDMA 写操作则为基线吞吐量的 70%。在超过 1024 字节的访问时,写操作的性能相较于读操作会变差,我们认为这是由于 RNIC 和内存控制器之间通过 PCIe 总线进行额外通信所致。在 4096 字节的访问时,两种操作类型的吞吐量相近。
我们还测试了更大的 MTU(最大传输单元)大小,以确定其对系统性能和 NUMA 局部性假设的影响(如果有的话)。如果应用层存在批量处理,设计者可能会选择使用更大的 MTU。在更大的数据包大小(即大于 256 字节)下,直至 1024 字节的访问,NUMA 的影响仍然存在。无论总体吞吐量如何变化,对于较小的访问大小,更大的 MTU 并不能消除 NUMA 局部性的影响,这种影响在单个 RDMA 操作中持续存在。与 MTU 无关,2048 字节和 4096 字节访问的吞吐量始终较低,并且 NUMA 的影响可以忽略不计,这两者都是由其他瓶颈造成的,例如需要多次通过 PCIe 总线。
总之,该实验表明,在 RDMA 复杂交互的其他方面不会限制吞吐量的配置中,不同的 RDMA 访问大小都会体现出 NUMA 局部性的影响。
C. 独立应用负载
在本次实验中,我们运行一个独立进程,该进程会在内存中分配一个缓冲区,并创建多个线程来随机访问该缓冲区。内存占用量、线程数量以及读写比例均为可配置项。此外,我们还指定了缓冲区和线程的非统一内存访问(NUMA)局部性,以研究它们对远程直接内存访问(RDMA)性能的影响。
假设:当一个独立工作负载与远程内存访问并发执行时,我们预计 RDMA 读操作的性能会下降。预期性能变化的根源在于服务器机器内存子系统的竞争。出于与之前相同的原因,我们预计 RDMA 写操作将保持稳定。
发现:首先,我们在 128 个线程以 50% 的概率随机进行读写操作的情况下,测量单边 RDMA 操作的吞吐量与缓冲区大小 ss 的关系。该实验不考虑 NUMA,即工作负载线程和内存并不绑定到服务器上的特定 NUMA 区域。与上一节相同,测试包含客户端和服务器之间的 8 个队列对(QP),并对 64 字节的内存块进行读写操作。在这种配置下,我们惊讶地发现性能并未受到影响。然而,当将访问大小减小到 8 字节时,结果表明对于 RDMA 远程读操作,独立工作负载确实产生了影响,其性能相较于无负载基线降低了多达 20%。随着缓冲区大小的增加,NUMA 局部性的影响也变得更加显著。
接下来,我们研究了独立工作负载的 NUMA 局部性的影响,发现无论 NUMA 如何放置,吞吐量都没有显著差异,这表明在不考虑 NUMA 的工作负载中,快速路径互连(QPI)上的竞争是导致性能下降的主要原因。这是因为 RDMA 操作对远程机器是透明的,因此其性能特征与本地访问类似。在这种情况下,本地工作负载足以使 QPI 饱和并最终影响性能。另一方面,绑定到 NUMA 的工作负载不会使处理器内部网络饱和,因此不会影响 RDMA 性能。
与之前的实验相比,在这种设置下计算出的性能下降幅度略大。正如我们将在第六节中看到的,当存在服务器端计算时,独立工作负载的存在对整体性能的影响要大得多。在这种情况下,我们在微基准测试中看到的综合影响会在更大程度上影响性能。
D. 远程可访问内存上的负载
Load on remotely accessible memory
正如我们所提到的,服务进程本身通常并非处于空闲状态,而是可能对本地数据进行计算。对称分布式事务系统、图引擎和分布式共享内存都是这种模式的示例 [7]、[10]、[13]、[40]、[41]。为了展示这类工作负载的影响,我们在微基准测试中引入了服务器负载线程,这些线程操作的数据也可被远程客户端访问。
工作线程在服务器启动时启动,并开始随机访问远程可访问内存。最初,采用由 90% 的写操作和 10% 的读操作组成的工作负载。然后,客户端连接开始向服务器发出操作请求。与上一个实验的结果一致,我们将远程内存访问的io大小缩减至 8 字节;再次使用 8 个连接进行测试。请注意,所有远程可访问内存都可以存储在缓存中。
假设
由于所访问的内存对于本地和远程工作负载来说是共用的,我们预计在存在工作负载的情况下,RDMA(远程直接内存访问)读操作的性能下降幅度会比之前更大。而 RDMA 写操作预计能保持性能,因为远程网卡(RNIC)在收到写操作后会立即发送确认信息。
发现
我们的实验结果揭示了完全出乎意料的情况。在本地工作负载下,当有超过 8 个线程同时访问同一内存区域时,对 RDMA 远程内存的单边 RDMA 写操作的性能比 RDMA 本地写操作高出 70% - 80%。也就是说,内存和工作线程都处于 RDMA 远程的非统一内存访问(NUMA)区域。在相同情况下,RDMA 远程读操作的吞吐量比 RDMA 本地操作高出 35%。
这种现象与通常认为的应该优先选择 RDMA 本地操作的预期相悖。此外,我们发现 RDMA 写操作的性能受到的影响最大,而根据我们之前的实验,这是未曾预料到会发生变化的。
我们将在第八节对这一现象进行全面讨论,但在此我们指出,这可能是因为 RDMA 本地操作会直接访问缓存。尽管数据直接 I/O(DDIO)旨在提高 I/O 性能,但在对远程可访问内存存在大量写操作的本地工作负载时,DDIO 实际上会阻碍整体性能。另一方面,对 RDMA 远程内存的客户端操作使用直接内存访问(DMA),并且不会在缓存层面与本地工作负载产生交互。我们怀疑缓存压力限制了集成 I/O 内存管理单元的吞吐量,最终导致网卡(RNIC)成为瓶颈。
为了验证我们的实验结果,我们在配备了迈络思(Mellanox)ConnectX - 4 网卡和相同英特尔服务器(不过核心数略少)的集群上重新运行了 8 个连接和 8 字节访问大小的配置。图 5(b) 表明,即使在新一代网络适配器上,这一趋势仍然存在。值得注意的是,在新硬件上,这种现象更加明显,RDMA 远程写操作的性能比 RDMA 本地写操作高出 3 倍。这表明底层的交互并非特定于网卡,而是与机器架构直接相关。我们认为 DDIO 在这一趋势的形成中起到了重要作用。
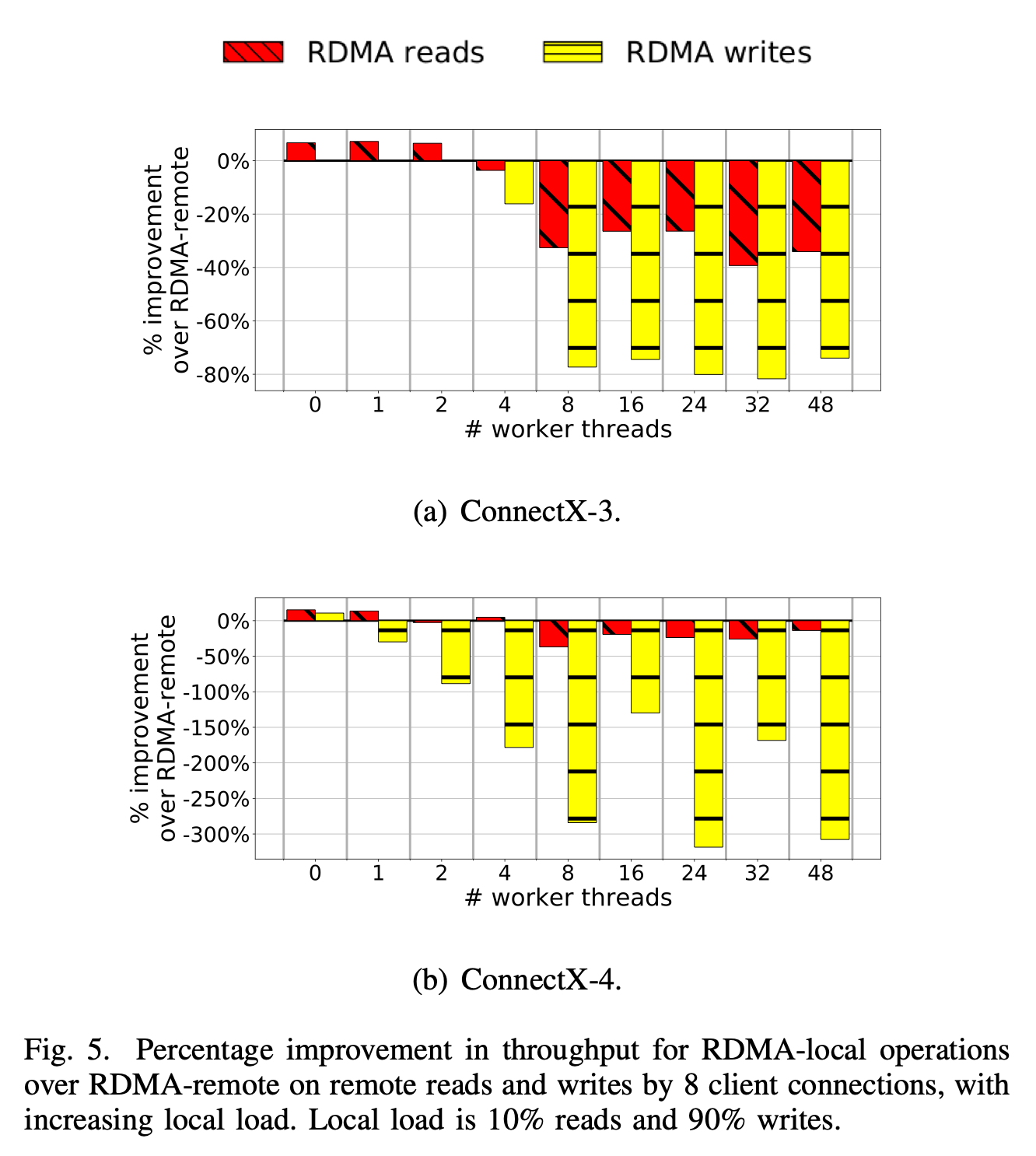
我们还测试了其他各种配置,包括更低的写操作比例、更多的客户端连接、更大的访问大小以及下一代 RDMA 卡。重要的是,当工作负载的读写比例为 1:1 时,这一意外结果仍然存在。在这种情况下,我们观察到 RDMA 远程写操作的性能提高了近 50%。当我们将连接数增加到 32 个时,我们观察到的现象与报告的 8 个连接的结果类似,但响应程度有所减弱。
对于超过 8 个工作线程的情况,RDMA 远程写操作的性能提高了 5% - 20%。最后,将每次远程访问的大小增加到 64 字节后,这种现象消失了,RDMA 本地操作的性能又略微优于 RDMA 远程操作。这一意外的性能问题让我们得出结论:需要进行小尺寸 RDMA 访问的系统设计人员应该考虑本地工作负载对其特定系统行为的潜在影响。
我们的结果还表明,传统上关于 NUMA 局部性的观念在涉及 I/O 时并不稳固,并且可能会产生重大的矛盾后果。
需要注意的是,在这种情况下我们没有实现互斥机制,因为在现有的网卡上,本地负载和 RDMA 操作之间无法实现互斥。不过,由于机器硬件实现了底层的缓存一致性策略,读操作和写操作是一致的。
六、基于 RDMA 的 Memcached
我们还部署了一个基于RDMA的 Memcached 实现 [20],并针对非统一内存访问(NUMA)局部性对其性能进行了测量。我们遵循与之前相同的原则,以展示该实现对于实际应用的性能表现。
本次实验设置与微基准测试类似,使用 Memcached 实例为客户端提供服务,客户端使用自带的 memslap 工作负载生成工具进行模拟。
实验连接数低于512:
据我们所知,当连接数少于 512 时,基于 RDMA 的 Memcached 使用单边通信。当连接数较多时,则采用混合方法,以避免单边连接带来的内存开销。我们的实验目标是连接数低于该阈值的情况,因此完全采用单边通信。
Memcached单线程,读写比例9:1 :
Memcached 在所有数据传输中都使用主动消息传递和单边 RDMA 读取 [20]。对于写操作(put),客户端会传递要写入数据的位置,然后服务器通过 RDMA 从客户端将数据读取到与键对应的槽位。对于读操作(get),客户端首先交换有关所需键值的位置和大小的信息,然后分配一个目标缓冲区,并通过 RDMA 从服务器读取数据。请注意,写操作和读操作都利用 RDMA 读取进行数据传输。
我们将 Memcached 配置为以单工作线程运行,以响应来自单个客户端的请求,从而精确确定资源局部性的影响。在执行过程中,每个键值对总共 67 字节,其中值为 64 字节长。键和值随机填充字母数字字符。客户端向 Memcached 发起的操作中,90% 为读操作,10% 为写操作。我们报告每个客户端连接进行 10 次试验、每次 100000 次操作的平均吞吐量。
图 6(a) 展示了服务器无负载运行时,不同客户端连接数下的吞吐量。
在有 4 个连接后,Memcached 达到满负载状态;
在有 16 个连接后,RDMA网卡(RNIC)达到饱和状态。
我们测试了三种场景:
(1)服务器和客户端都固定在各自节点的 RDMA 本地区域;
(2)服务器和客户端都固定在各自节点的 RDMA 远程区域;
(3)将客户端绑定到 RDMA 本地区域,服务器绑定到 RDMA 远程区域,这与微基准测试类似。
从图中可以明显看出,当服务器无负载时,客户端和服务器都位于 RDMA 本地区域时性能最佳。将两者都移至 RDMA 远程区域,对整体吞吐量的影响会逐渐变差。
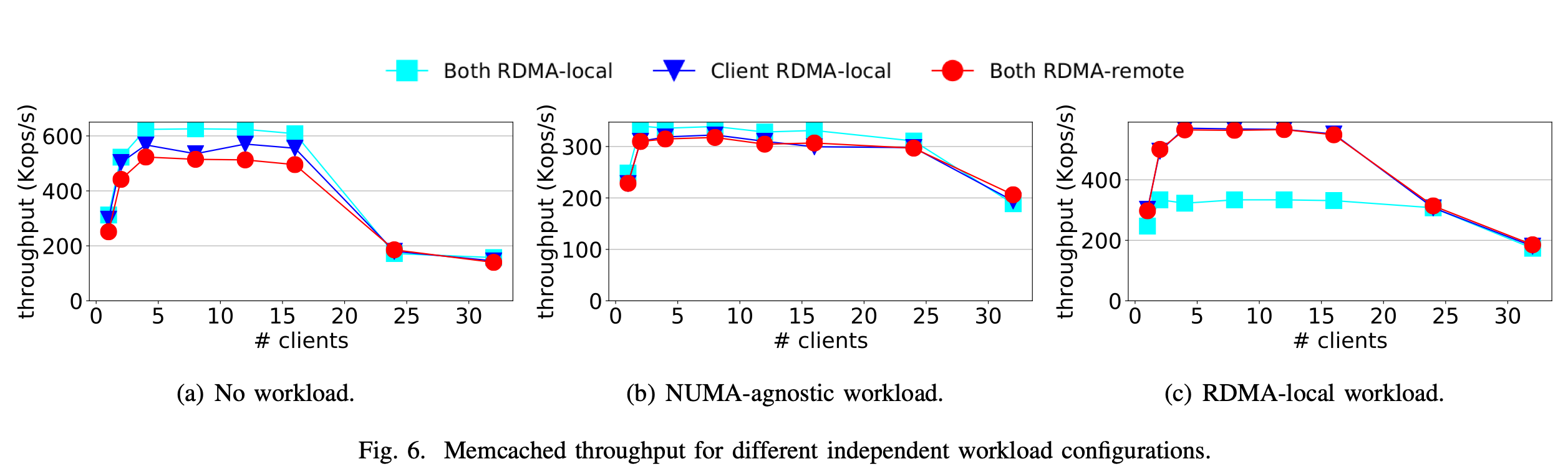
图 6(b) 展示了与之前相同配置下的系统性能,但引入了与 NUMA 无关的负载。此负载由服务器上未被 Memcached 使用的其余线程组成,这些线程会随机访问一个大内存缓冲区,读写操作各占 50%。服务器上运行的负载对所有配置的整体性能都产生了显著影响,但由于位于 RDMA 远程区域,性能仍下降了 10%。
或许更有趣的情况是,当工作负载绑定到特定的 NUMA 区域时。图 6© 展示了负载运行在 RDMA 本地 NUMA 区域的情况。当负载位于 RDMA 本地区域时,RDMA 远程区域的吞吐量不受负载影响。由于篇幅限制,我们未展示相关图表,但当负载运行在 RDMA 远程区域时,RDMA 本地内存访问不受影响。
更重要的是,在这两种情况下,对于少于 24 个连接,工作负载会使对同一 NUMA 区域的 RDMA 操作减少 40% - 50%。因此,我们预计对未负载的 NUMA 区域的操作速度将比负载区域快 2 倍。
七、额外发现
我们记录了涉及RDMA和内存架构的有趣趋势,这些趋势进一步导致了前文所讨论的性能损失。
首先,我们观察到 RDMA 读取操作不会进行缓存分配。也就是说,如果 RDMA 读取所针对的内存不在缓存中,那么缓存不会被填充,而是直接从主内存中获取值,性能会降低约 3%。我们通过先将数据缓存起来并测量性能变化,然后清空缓存再次测量性能差异,从而证实了这一行为。
其次,我们在研究消息大小时注意到,当较大的操作不进行分段时,局部性和性能之间往往呈反比关系。换句话说,如果最大传输单元(MTU)大于 1024 字节,且操作大小大于 256 字节,那么 RDMA 远程操作的性能往往比 RDMA 本地操作高出 5 - 10%。
最后,我们试图通过禁用与我们的RDMA网卡(RNIC)相连的根端口的 PCIe 配置空间中的写分配流来衡量直接数据输入/输出(DDIO)的影响。不幸的是,这样做会禁用内部操作所需的优化,导致整体性能显著下降。为了全面剖析在远程可访问缓冲区上进行本地操作时的行为,有必要在这个方向上进行进一步的研究。
八、讨论与未来研究方向
NUMA与RDMA之间的关系取决于一系列复杂的硬件交互,并且受系统工作负载的影响。
在此,我们总结研究结果,并阐释观察到的现象背后的原理。然后,我们对 NUMA 对单边 RDMA 交互的性能影响给出一般性预期。首先,我们列举关键发现,随后进行详细解释:
- 当执行过程未受到额外工作负载影响时,对 RDMA 远程缓冲区的远程读取操作性能可能会降低 5% - 10%。
- 在存在独立工作负载的情况下,对于复杂应用程序,RDMA 远程操作的速度可能会减慢至原来的二分之一。
- 对 RDMA 远程可访问内存执行的工作负载,其性能比 RDMA 本地操作高出 3 倍。这与关于 NUMA 局部性的普遍认知相悖。
在未加载负载的 RDMA - Memcached 服务器中,NUMA 局部性平均会使单边操作在连接的每一端吞吐量降低 10%。
在最坏的情况下,即客户端和服务器均为 RDMA 远程时,我们预计性能会比最佳情况(即两端均为 RDMA 本地)差 20%。造成这种差异的根本原因有两个方面。
其一,RDMA 本地交互在处理请求时会自动利用直接缓存访问,从而提高了延迟和吞吐量。
其二,数据检索必须通过套接字之间的互连进行,这会产生额外的开销。当客户端和服务器的 RDMA 内存区域均为 RDMA 远程时,这两个因素共同作用导致性能下降 20%。
尽管每一端 10% 的性能下降看似并不显著,但在我们的微基准测试和实际应用中,这种情况始终存在。这种性能损失可能会掩盖新设计和实现的性能优势。由于包含 RDMA 可访问内存的物理页面在运行时无法移动,且单边 RDMA 操作对远程机器是透明的,因此如何克服这一问题仍是一个悬而未决的问题。
当服务器负载运行时,RDMA 操作不再处于孤立的执行环境中。在评估中,我们测试了独立工作负载以及访问远程可访问内存的工作负载。当工作负载独立且应用程序涉及服务器上的计算时,工作负载的 NUMA 局部性会对与该工作负载处于同一 NUMA 区域的单边操作产生显著的负面影响(即速度减慢至原来的二分之一)。这是因为 RDMA 操作和服务器计算都与工作负载竞争资源。
如果工作负载并非只读,并且直接对可通过 RDMA 访问的内存进行操作,同时 RDMA 操作的数据量较小,那么 RDMA 本地操作的性能会比 RDMA 远程操作差。这一结果出乎意料,可能是由数据直接 I/O(DDIO)导致的。当 RDMA 操作访问的内存也存在于其他核心的高级缓存中时,这些操作会因缓存互连的负载(如缓存行失效)而产生额外的开销。因此,如果应用程序需要此类工作负载,使用 RDMA 远程内存可能有助于避免缓存争用。
最后,通过与新型远程网络接口控制器(RNIC)的对比,我们获得了新的启发。未来的硬件改进将继续降低延迟并提高吞吐量。这些进步带来的一个结果是,NUMA 的影响将更加明显,它在整个硬件路径性能中所占的比例将更大。
未来研究方向
基于我们的研究结果,我们确定了一些研究机会,旨在为使用多处理器服务器的分布式系统提供优化组件。这些思路的共同目标是使 RDMA 操作在 NUMA 局部性方面更加智能,从而避免出现本文所强调的性能问题。以下是我们认为特别有前景的研究方向概述,后续段落将提供更多细节:
- 支持 RDMA 的 NUMA 平衡机制,自动将远程可访问内存移动到最优的 NUMA 区域。
- 工作负载分析,自动将内存区域固定到 NUMA 区域。
- 支持 NUMA 的本地和远程操作同步机制。
NUMA 平衡是许多操作系统采用的一种调度策略,旨在通过移动页面和计算任务来减少 NUMA 互连的流量。然而,对于 RDMA 单边交互,NUMA 平衡无法发挥作用,因为这些操作对操作系统是不可见的。让本地操作系统了解这种远程访问模式,有助于减少本文中讨论的因 RDMA 远程计算产生的部分开销。
针对本文讨论的问题,一个更直接的解决方案是采用工作负载分析器,并根据分析结果,依据访问模式预先将内存固定到 NUMA 区域。我们相信,我们的研究结果将促使系统设计人员做出决策,避免出现上述开销。
另一个相关问题是,除非设备提供支持,否则 RDMA 和本地访问操作无法实现跨操作的原子性。目前的 RNIC 仅支持远程操作之间的原子性。为了实现全局原子性,必须利用回环或先进的硬件技术(如英特尔的事务同步扩展,TSX)。一个支持 NUMA 且不强制本地操作通过本地 RNIC 路由的同步应用程序编程接口(API),将为程序员提供一个强大的工具,用于构建高性能的分布式共享内存系统。
参考
REFERENCES
[1] Mellanox adapters. https://store.mellanox.com/categories/adapters/
infiniband-and-vpi-adapter-cards.html, 2018.
[2] NUMA Balancing. https://access.redhat.com/documentation/en-us/red
hat enterprise linux/7/html/virtualization tuning and optimization
guide/sect-virtualization tuning optimization guide-numa-auto numa
balancing, 2018.
[3] Scaling out NUMA-Aware Applications with RDMA-Based Distributed
Shared Memory. Journal of Computer Science and Technology,
34(1):94–112, 2019.
[4] B. Atikoglu, Y. Xu, E. Frachtenberg, S. Jiang, and M. Paleczny. Work-
load Analysis of a Large-scale Key-value Store. In ACM SIGMETRICS
Performance Evaluation Review, volume 40, pages 53–64. ACM, 2012.
[5] A. Banerjee, R. Mehta, and Z. Shen. NUMA Aware I/O in Virtualized
Systems. In 2015 IEEE 23rd Annual Symposium on High-Performance
Interconnects, pages 10–17. IEEE, 2015.
[6] E. Burns and R. Russell. Implementation and Evaluation of iSCSI over
RDMA. In 2008 Fifth IEEE International Workshop on Storage Network
Architecture and Parallel I/Os, pages 3–10. IEEE, 2008.
[7] Q. Cai, W. Guo, H. Zhang, D. Agrawal, G. Chen, B. C. Ooi, K.-L. Tan,
Y. M. Teo, and S. Wang. Efficient Distributed Memory Management
with RDMA and Caching. Proceedings of the VLDB Endowment,
11(11):1604–1617, 2018.
[8] I. Calciu, D. Dice, Y. Lev, V. Luchangco, V. J. Marathe, and N. Shavit.
Numa-aware reader-writer locks. PPoPP, pages 157–166. ACM, 2013.
[9] I. Calciu, S. Sen, M. Balakrishnan, and M. K. Aguilera. Black-box
Concurrent Data Structures for NUMA Architectures. ACM SIGOPS
Operating Systems Review, 51(2):207–221, 2017.
[10] H. Chen, R. Chen, X. Wei, J. Shi, Y. Chen, Z. Wang, B. Zang, and
H. Guan. Fast In-memory Transaction Processing Using RDMA and
HTM. ACM Transactions on Computer Systems (TOCS), 35(1):3, 2017.
[11] Y. Chen, X. Wei, J. Shi, R. Chen, and H. Chen. Fast and general
distributed transactions using RDMA and HTM. In EuroSys, pages
26:1–26:17. ACM, 2016.
[12] H. Daly, A. Hassan, M. F. Spear, and R. Palmieri. NUMASK: high
performance scalable skip list for NUMA. In DISC, pages 18:1–18:19,
2018.
[13] A. Dragojevi´ c, D. Narayanan, O. Hodson, and M. Castro. FaRM: Fast
Remote Memory. In USENIX NSDI, pages 401–414, 2014.
[14] A. Dragojevi´ c, D. Narayanan, E. B. Nightingale, M. Renzelmann,
A. Shamis, A. Badam, and M. Castro. No Compromises: Distributed
Transactions with Consistency, Availability, and Performance. In SOSP,
pages 54–70. ACM, 2015.
[15] B. Fan, D. G. Andersen, and M. Kaminsky. Memc3: Compact and
concurrent memcache with dumber caching and smarter hashing. In
USENIX NSDI, pages 371–384, 2013.
[16] B. Fitzpatrick. Distributed Caching with Memcached. Linux journal,
2004(124):5, 2004.
[17] InfiniBand Trade Association. InfiniBand Architecture Specification
Volume 1 and 2, 11 2007. Release 1.2.1.
[18] Intel. Intel xeon processor e7-8800/4800 v4 product families, 2016.
[19] Intel. Intel® memory latency checker v3.6, 2018.
[20] J. Jose, H. Subramoni, M. Luo, M. Zhang, J. Huang, M. Wasi-ur
Rahman, N. S. Islam, X. Ouyang, H. Wang, S. Sur, et al. Memcached
Design on High Performance RDMA Capable Interconnects. In ICPP,
pages 743–752. IEEE, 2011.
[21] A. Kalia, M. Kaminsky, and D. G. Andersen. Design Guidelines for
High Performance RDMA Systems. In 2016 USENIX ATC, page 437,
2016.
[22] A. Kalia, M. Kaminsky, and D. G. Andersen. FaSST: Fast, Scalable
and Simple Distributed Transactions with Two-Sided RDMA Datagram
RPCs. In USENIX OSDI, pages 185–201, 2016.
[23] C. Lameter. Numa (non-uniform memory access): An overview. Queue,
11(7):40:40–40:51, July 2013.
[24] Y. Li. NUMA-aware Algorithms: the Case of Data Shuffling. In CIDR,
Jan 2013.
[25] J. Mambretti, J. Chen, and F. Yeh. Next generation clouds, the
chameleon cloud testbed, and software defined networking (sdn). ICC-
CRI, pages 73–79. IEEE, 2015.
[26] Mellanox. Maximizing server performance with mellanox socket direct
adapter, 2018.
[27] Microsoft. Availability of h-series vms in microsoft azure, 2016.
[28] C. Mitchell, Y. Geng, and J. Li. Using One-Sided RDMA Reads to
Build a Fast, CPU-Efficient Key-Value Store. In USENIX ATC, pages
103–114, 2013.
[29] J. Nelson and R. Palmieri. On the performance impact of numa on
one-sided rdma interactions. In ICDCS ’20 Poster paper, 2020.
[30] R. Nishtala, H. Fugal, S. Grimm, M. Kwiatkowski, H. Lee, H. C. Li,
R. McElroy, M. Paleczny, D. Peek, P. Saab, et al. Scaling Memcache
at Facebook. In USENIX NSDI, pages 385–398, 2013.
[31] S. Novakovic, Y. Shan, A. Rajaraman, and J. D. Ullman. Storm: a fast
transactional dataplane for remote data structures. ACM, 2019.
[32] G. F. Pfister. An introduction to the infiniband architecture. In High
Performance Mass Storage and Parallel I/O, chapter 42, pages 617–632.
John Wiley & Sons, Inc., 2001.
[33] Y. Ren, T. Li, D. Yu, S. Jin, and T. Robertazzi. Middleware Support for
RDMA-based Data Transfer in Cloud Computing. In 2012 IEEE 26th
International Parallel and Distributed Processing Symposium Workshops
& PhD Forum, pages 1095–1103. IEEE, 2012.
[34] Y. Ren, T. Li, D. Yu, S. Jin, and T. Robertazzi. Design and Performance
Evaluation of NUMA-aware RDMA-based End-to-end Data Transfer
Systems. In SC, page 48. ACM, 2013.
[35] T. Research. AMD Optimizes EPYC Memory with NUMA, 2018.
[36] R. Ricci, E. Eide, and The CloudLab Team. Introducing CloudLab: Sci-
entific infrastructure for advancing cloud architectures and applications.
USENIX, 39(6), Dec. 2014.
[37] I. Smolyar, A. Markuze, B. Pismenny, H. Eran, G. Zellweger, A. Bolen,
L. Liss, A. Morrison, and D. Tsafrir. Ioctopus: Outsmarting nonuniform
DMA. In J. R. Larus, L. Ceze, and K. Strauss, editors, ASPLOS
’20: Architectural Support for Programming Languages and Operating
Systems, Lausanne, Switzerland, March 16-20, 2020, pages 101–115.
ACM, 2020.
[38] C. Wang, J. Jiang, X. Chen, N. Yi, and H. Cui. APUS: Fast and Scalable
Paxos on RDMA. In SoCC, pages 94–107. ACM, 2017.
[39] Y. Wang, L. Zhang, J. Tan, M. Li, Y. Gao, X. Guerin, X. Meng, and
S. Meng. HydraDB: a Resilient RDMA-driven Key-value Middleware
for In-memory Cluster Computing. In SC, pages 1–11. IEEE, 2015.
[40] X. Wei, Z. Dong, R. Chen, and H. Chen. Deconstructing rdma-enabled
distributed transactions: Hybrid is better! In USENIX OSDI, pages 233–
251, 2018.
[41] M. Wu, F. Yang, J. Xue, W. Xiao, Y. Miao, L. Wei, H. Lin, Y. Dai, and
L. Zhou. Gram: Scaling graph computation to the trillions. In SoCC,
pages 408–421. ACM, 2015.
[42] K. Zhang, R. Chen, and H. Chen. NUMA-aware Graph-structured
Analytics. ACM SIGPLAN Notices, 50(8):183–193, 2015.


















 1112
1112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









