









一、RDMA
RDMA(远程直接内存访问)技术主要包括以下核心实现方式:
1.1、InfiniBand(IB)
- 技术特性:
InfiniBand是专为RDMA设计的网络协议,采用专用硬件架构(如交换机、HCA网卡),通过二层协议实现低延迟(纳秒级)和高带宽(最高168Gbps)。其核心优势包括:- 零拷贝机制:数据直接在应用程序内存与网卡间传输,无需内核参与。
- 服务质量(QoS):支持优先级流控(PFC)和虚拟通道(VL),保障关键业务流量。
- 应用场景:主要用于高性能计算(HPC)、超算中心及大规模并行计算集群。
1.2、RoCE(RDMA over Converged Ethernet)
- 技术分类:
- RoCEv1:基于以太网二层(MAC层),需无损网络支持(PFC流控),仅限同一VLAN内通信。
- RoCEv2:扩展至三层(IP/UDP),支持跨子网路由,兼容现有以太网基础设施,延迟可低至1微秒。
- 优势与局限:
- 优势:成本低于InfiniBand,可利用现有以太网设备。
- 挑战:依赖无损网络配置,需交换机支持DCB和ECN以避免丢包。
1.3、iWARP(Internet Wide Area RDMA Protocol)
- 技术原理:基于TCP/IP协议栈,通过DDP、RDMAP和MPA子协议实现RDMA语义,兼容传统广域网。
- 核心特点:
- 广域网支持:适用于跨数据中心的长距离传输,无需专用硬件。
- 软件实现:如Soft-iWARP,可在普通网卡上通过软件模拟RDMA功能(性能受限)。
- 应用场景:企业级存储(iSCSI扩展)、混合云环境及对兼容性要求较高的场景。
1.4、其他相关性
- Soft-RoCE:软件模拟RoCE协议栈,无需专用硬件,但延迟较高(微秒级),适用于开发和测试环境。在虚拟机环境或者容器环境都可以使用。
- Virtual Interface(VI)架构:早期RDMA实现,现已逐步被InfiniBand和RoCE取代。
-
IB Verbs 和 DOCA GPUNetIO :
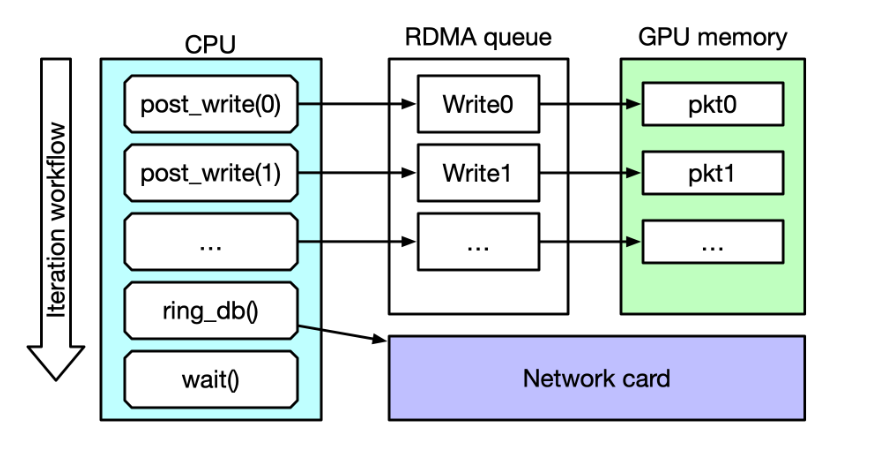
在NVIDA DOCA 2.7 中,引入了一个新的 DOCA GPUNetIO RDMA 客户机-服务器代码示例,以显示新 API 的使用情况并评估其正确性。perftest 是一组微基准点,用于使用基本的 RDMA 操作测量 RDMA 带宽(BW)和两个对等点(服务器和客户端)之间的延迟尽管网络控制部分发生在 CPU 中,但可以通过启用 GPUDirect RDMA 并指定
--use_cuda标志来指定数据是否驻留在 GPU 内存中。一般来说,RDMA 写单向 BW 基准测试(即 ib_write_bw)在每个 RDMA 队列上发布一个针对相同大小消息的写请求列表,用于固定迭代次数,并命令 NIC 执行发布的写操作,这就是所谓的“按门铃”程序。为了确保所有写入都已发出,在进入下一次迭代之前,它轮询完成队列,等待每个写入都已正确执行的确认。然后,对于每个消息大小,可以检索发布和轮询所花费的总时间,并以 MB/s 为单位计算 BW。
1.5、技术对比
| 技术 | 延迟 | 带宽 | 网络要求 | 典型场景 |
|---|---|---|---|---|
| InfiniBand | 0.6μs | 200Gbps+ | 专用交换机/网卡 | 超算、AI训练集群 |
| RoCEv2 | 1-10μs | 100-800Gbps | 无损以太网(PFC/ECN) | 云数据中心、分布式存储 |
| iWARP | 10-100μs | 10-100Gbps | 普通以太网 | 跨数据中心、混合云 |
| Soft-RoCE/iWARP | 50-200μs | 1-40Gbps | 普通网卡+软件栈 | 开发测试、低成本验证 |
RDMA技术通过硬件卸载和协议优化显著提升了网络性能。
RoCEv2是数据中心主流选择,而iWARP在广域网上更具灵活性。在实际选型需结合网络基础设施(数据中心内、数据中心间)、成本及业务延迟敏感性综合评估。
1.6 RDMA的NetIO方法与算法解析
网络分组的实时 GPU 处理是一种适用于几个不同应用领域的技术,包括信号处理、网络安全、信息收集和输入重建。这些应用程序的目标是实现一个内联数据包处理管道,以在 GPU 内存中接收数据包(无需通过 CPU 内存暂存副本);与一个或多个 CUDA 内核并行地处理它们;然后运行推断、评估或通过网络发送计算结果。
通常,在这个管道中, CPU 是中介,因为它必须使网卡( NIC )接收活动与 GPU 处理同步。一旦 GPU 内存中接收到新的数据包,这将唤醒 CUDA 内核。类似的考虑可以应用于管道的发送端。
Data Plane Development Kit ( DPDK )框架引入了 gpudev library 来为此类应用提供解决方案:使用 GPU 内存( GPUDirect RDMA 技术)结合低延迟 CPU 同步进行接收或发送。
GPU 启动的通信
CPU 是主要瓶颈,它在同步 NIC 和 GPU 任务以及管理多个网络队列方面承担了太多的责任。例如,考虑一个具有多个接收队列和 100 Gbps 传入流量的应用程序。以 CPU 为中心的解决方案将具有:
- CPU 调用每个接收队列上的网络功能,以使用一个或多个 CPU Core 接收 GPU 存储器中的数据包
- CPU 收集数据包信息(数据包地址、编号)
- CPU 向 GPU 通知新接收的分组
- GPU 处理数据包
这种以 CPU 为中心的方法是:
- 资源消耗:为了处理高速率网络吞吐量( 100 Gbps 或更高),应用程序可能需要专用整个 CPU 物理核心来接收(和/或发送)数据包
- 不可扩展:为了与不同的队列并行接收(或发送),应用程序可能需要使用多个 CPU 内核,即使在 CPU Core 的总数可能被限制在较低数量(取决于平台)的系统上也是如此
- 依赖于平台:低功耗 CPU 上的相同应用程序将降低性能
GPU 内联分组处理应用程序的下一个自然步骤是从关键路径中删除 CPU 。移动到以 GPU 为中心的解决方案, GPU 可以直接与 NIC 交互以接收数据包,因此数据包一到达 GPU 内存,处理就可以开始。同样的注意事项也适用于发送操作。
GPU 从 CUDA 内核控制 NIC 活动的能力称为 GPU 启动的通信。假设使用 NVIDIA GPU 和 NVIDIA NIC ,则可以将 NIC 寄存器暴露给 GPU 的直接访问。这样, CUDA 内核可以直接配置和更新这些寄存器,以协调发送或接收网络操作,而无需 CPU 的干预。
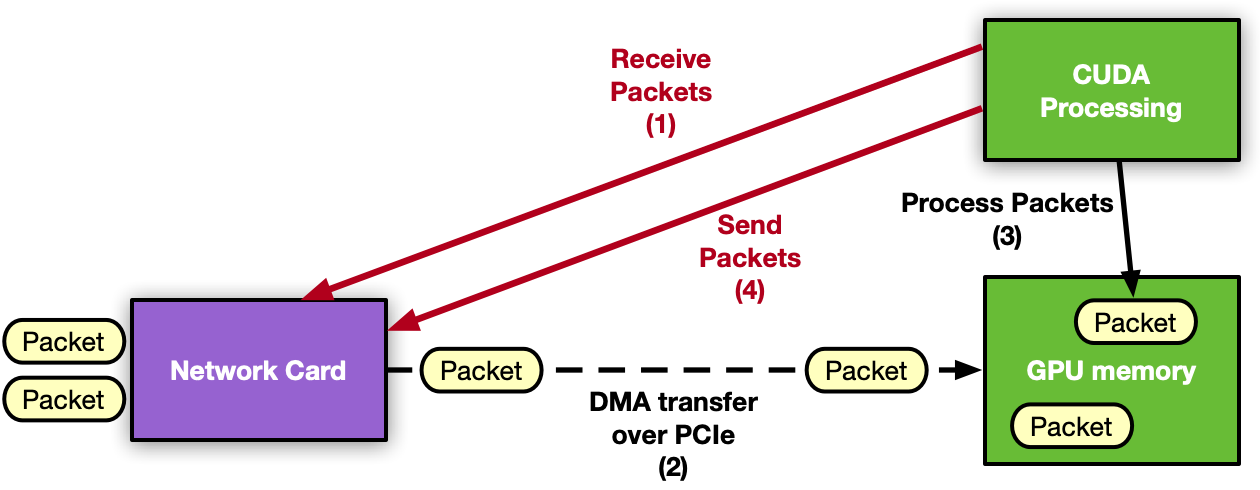
图 :以 GPU 为中心的应用程序, GPU 控制网卡和数据包处理,无需 CPU
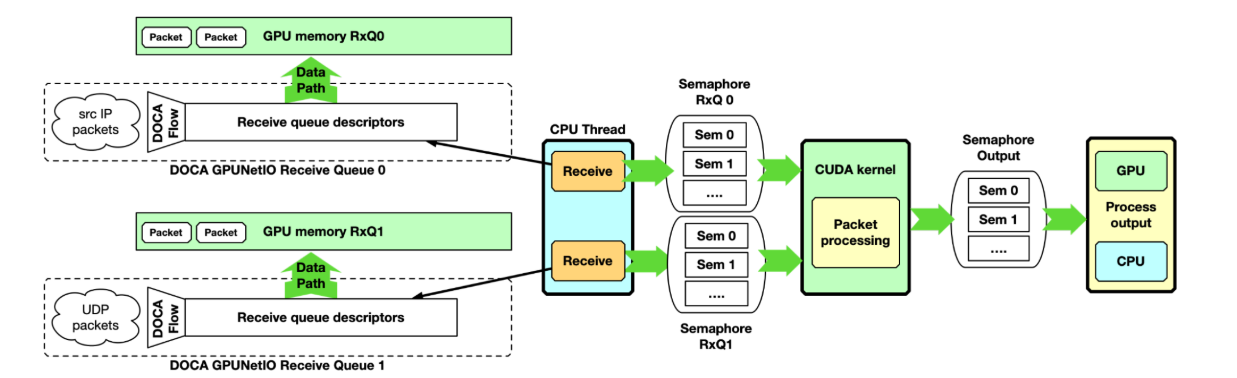
GPU 数据包处理管道, CPU 在 GPU memory 中接收数据包,并使用 GPUNetIO 信号量通知数据包处理 CUDA 内核有关传入数据包
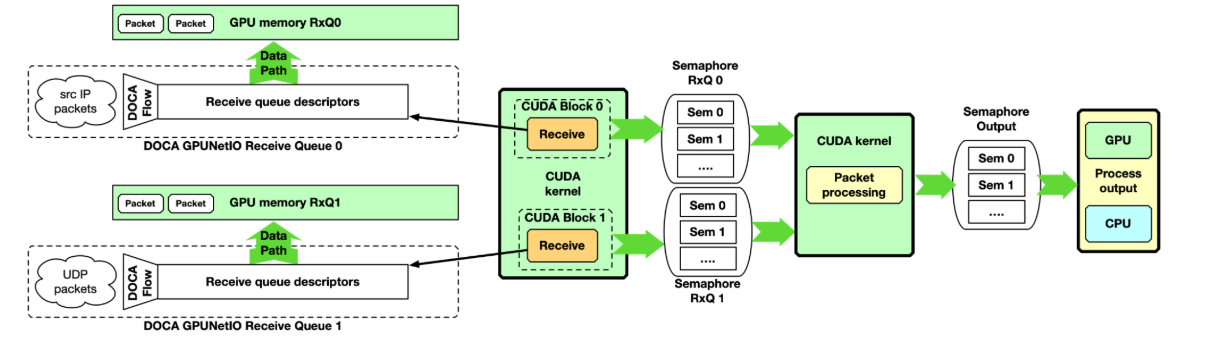
多 CUDA 内核:至少涉及两个 CUDA 内核,一个专用于接收分组,另一个专用用于分组处理。接收机 CUDA 内核可以通过信号量向第二 CUDA 内核提供分组信息。 GPU 数据包处理管道, CPU 在 GPU memory 中接收数据包,并使用 GPUNetIO 信号量通知数据包处理 CUDA 内核有关传入数据包。
这种方法适用于高速网络和延迟敏感的应用,因为两个接收操作之间的延迟不会被其他任务延迟。期望将接收机 CUDA 内核的每个 CUDA 块关联到不同的队列,并行地接收来自所有队列的所有分组。
根据定义, DPDK 是 CPU 框架。要启用 GPU 启动的通信,需要在 GPU 上移动整个控制路径,这是不适用的。因此,通过创建新的库来启用此功能。
GPUNetIO 功能一般包括:
- GPU 启动的通信: 内核调用 GPUNetIO 库中的 CUDA device 函数,以指示网卡发送或接收数据包
- 精确的发送调度:通过 GPU 启动的通信,可以根据用户提供的时间戳来调度未来的数据包传输
- GPUDirect RDMA :以连续固定大小 GPU 内存跨步接收或发送数据包,无 CPU 内存暂存副本
- 信号量:在 CPU 和 GPU 之间或不同 GPU CUDA 内核之间提供标准化的低延迟消息传递协议
- CPU 对 CUDA 内存的直接访问: CPU 可以在不使用 GPU 内存 API 的情况下修改 GPU 内存缓冲区
1.6.1、传输操作类型
-
双边操作(SEND/RECEIVE)
- 机制:需通信双方参与,发送端通过SQ(发送队列)提交请求,接收端通过RQ(接收队列)响应,完成数据交换。常用于控制报文(如连接建立、元数据同步)。
- 流程:
- 发送端将数据描述符(WQE)放入SQ,接收端提前注册接收缓冲区到RQ。
- 网卡直接通过DMA完成数据传输,完成后通过CQ(完成队列)通知应用。
-
单边操作(READ/WRITE)
- 机制:仅需本端主动操作,无需远端感知。数据直接从本地内存写入远端内存(WRITE)或从远端内存读取(READ),适用于大规模数据流(如分布式存储、科学计算)。
- 算法优化:
- 地址预取:通过预注册远端内存地址(R_key和VA),减少传输延迟。
- 流水线调度:将大块数据拆分为多个WQE并行处理,提升吞吐量。
1.6.2、队列管理机制
1.6.2.1 队列对(QP, Queue Pair)
-
结构:每个QP包含SQ(发送队列)和RQ(接收队列),映射到应用虚拟地址空间,支持异步通信。
-
调度算法:
-
轮询模式(Polling):应用主动查询CQ状态,适用于低延迟场景(如HPC)。
-
中断模式(Interrupt):依赖硬件中断通知完成事件,降低CPU占用但引入微秒级延迟。
-
1.6.2.2 完成队列(CQ)
-
事件合并:通过聚合多个完成事件(CQE)减少中断频率,提升系统效率(如中断合并技术)。
在RDMA中,通过轮询CQ(Completion Queue)实现无锁事件通知是高性能场景下的核心优化手段。以下是完整算法、代码实现及风险分析:
1.6.2.2.1 核心算法设计
-
轮询触发条件
- 事件驱动:持续调用
ibv_poll_cq检查CQ中的完成事件(CQE),无事件时返回0,有事件时返回正数(事件数量)。 - 数学表达:设轮询间隔为Δt,CQE到达率为λ,则轮询效率η为:η=1−e−λΔt当Δt→0(高频轮询)时,η→1,但CPU开销激增。
- 事件驱动:持续调用
-
无锁实现
- 原子操作:通过
__atomic_load_n读取CQ尾指针,避免锁竞争。 - 批量处理:单次轮询提取多个CQE(如32个),减少调用次数。
- 原子操作:通过
#include <infiniband/verbs.h>
#include <atomic>
// 无锁轮询CQ的示例
void poll_cq_without_lock(ibv_cq* cq) {
const int MAX_CQE = 32;
ibv_wc wc[MAX_CQE];
int ne = 0;
// 原子读取CQ尾指针
uint32_t tail = __atomic_load_n(&cq->tail, __ATOMIC_RELAXED);
// 批量轮询
while ((ne = ibv_poll_cq(cq, MAX_CQE, wc)) > 0) {
for (int i = 0; i < ne; ++i) {
if (wc[i].status != IBV_WC_SUCCESS) {
// 错误处理
fprintf(stderr, "CQE error: %s\n", ibv_wc_status_str(wc[i].status));
continue;
}
// 正常处理(如释放WR资源)
free_wr_resource(wc[i].wr_id);
}
}
}1.6.2.2.2、主要问题与风险
-
CPU开销
- 高频轮询:若Δt过小(如1μs),CPU利用率可能达100%,导致其他任务饥饿
- 优化建议:结合混合模式(轮询+中断),空闲时切换为中断模式(如
ibv_req_notify_cq)。
-
事件丢失
- CQ溢出:若CQE产生速度超过处理速度,未读取的CQE可能被覆盖。需确保CQ深度D≥λ⋅Tprocess,其中Tprocess为单CQE处理时间。
-
延迟抖动
- 非实时性:轮询间隔Δt固定时,实际事件响应延迟可能波动。可通过动态调整Δt(如基于负载)优化。
-
多线程竞争
- 虚假共享:多线程轮询同一CQ可能因缓存行争用导致性能下降。建议每个线程绑定独立CQ。
1.6.2.2.3、性能优化建议
- 硬件卸载:使用SmartNIC(如NVIDIA ConnectX-6)的硬件轮询引擎,将CQ状态检查卸载至网卡,减少CPU介入。
- 选择性信号:对关键WR(如梯度同步)设置
IBV_SEND_SIGNALED,非关键WR不触发CQE,降低事件数量 - NUMA对齐:将CQ绑定到本地NUMA节点,避免跨节点访问延迟
1.6.3、内存注册与地址转换
-
内存注册(Memory Registration)
- 流程:应用通过Verbs API(如
ibv_reg_mr)将用户态内存注册为RDMA可访问区域,生成物理地址与密钥(R_key)。 - 优化算法:
- 大页内存(HugePage):减少TLB缺失,提升地址转换效率。
- 动态注册/注销:按需管理内存区域,避免静态注册的开销。
- 流程:应用通过Verbs API(如
-
地址转换(VA to PA)
- 硬件加速:RNIC通过页表缓存(Cached Page Table)直接完成虚拟地址到物理地址的转换,绕过操作系统。
1.6.4、协议栈与算法优化
1.6.4.1 拥塞控制算法
DCQCN(数据中心量化拥塞通知):用于RoCEv2,通过ECN标记和速率调整实现无损传输。
发送方叫Reaction Point,简称RP;
接收方叫Notification Point,简称NP;
中间交换机叫 Congestion Point,简称CP。
发送方(RP)以最高速开始发送,沿途过程中如果有拥塞,会被标记ECN显示拥塞,当这个被标记的报文转发到接收方(NP)的时候,接收方(NP)会回应一个CNP报文,通知发送方(RP)。
收到CNP报文的发送方(RP),就会开始降速。当发送方没有收到CNP报文时,就开始又提速了。

以下是智算中心组网中DCQCN(Data Center Quantized Congestion Notification)的核心算法:
-
ECN标记机制
ECN_mark={1if Qcurrent≥Kmin0otherwise\text{ECN\_mark} = \begin{cases} 1 & \text{if } Q_{\text{current}} \geq K_{\text{min}} \\ 0 & \text{otherwise} \end{cases}ECN_mark={10if Qcurrent≥Kminotherwise
交换机在队列长度超过阈值时标记ECN位(Qcurrent>KthresholdQ_{\text{current}} > K_{\text{threshold}}Qcurrent>Kthreshold):其中KminK_{\text{min}}Kmin为最小触发阈值。
-
α参数更新
αnew=g⋅αold+(1−g)⋅CNP_arrived\alpha_{\text{new}} = g \cdot \alpha_{\text{old}} + (1-g) \cdot \text{CNP\_arrived}αnew=g⋅αold+(1−g)⋅CNP_arrived
动态调整拥塞程度参数α\alphaα(指数加权移动平均):ggg为衰减因子(默认0.875),CNP_arrived\text{CNP\_arrived}CNP_arrived为是否收到CNP包(0或1)。
-
速率调整
- 降速(收到CNP时): Rnew=Rold⋅(1−α2)R_{\text{new}} = R_{\text{old}} \cdot (1 - \frac{\alpha}{2})Rnew=Rold⋅(1−2α)
- 提速(周期性增加): Rnew=Rold+AI⋅byte_counterR_{\text{new}} = R_{\text{old}} + \text{AI} \cdot \text{byte\_counter}Rnew=Rold+AI⋅byte_counter AI\text{AI}AI为固定增量(如100 Mbps),byte_counter\text{byte\_counter}byte_counter为累计发送字节数。
#include <infiniband/verbs.h>
#include <atomic>
struct DCQCNParams {
float alpha = 0.5; // 初始拥塞程度
float g = 0.875; // α衰减因子
int ai_rate = 100; // 提速增量(Mbps)
int current_rate = 200000; // 当前速率(Mbps)
};
void handle_cnp(DCQCNParams& params) {
// 收到CNP时降速
params.current_rate *= (1 - params.alpha / 2);
params.alpha = params.g * params.alpha; // 更新α
}
void rate_increase(DCQCNParams& params, uint64_t bytes_sent) {
// 周期性提速
params.current_rate += params.ai_rate * (bytes_sent / 1024);
}
void process_ecn_marking(ibv_qp* qp, DCQCNParams& params) {
// 模拟交换机ECN标记逻辑
if (qp->state.queue_length > K_MIN_THRESHOLD) {
send_cnp_to_sender(qp); // 发送CNP包
}
}关键参数配置(华为HCCN工具参考)
hccn_tool -i 0 -dcqcn -s alg_mode 0 f 5 g_shift 7 al 64 tkp 3 max_speed 200000 ai 100 tmp 6 alp 32参数说明:
alg_mode: 算法模式(0为DCQCN)f: Faster Recovery迭代次数g_shift: α更新速度控制max_speed: 最大速率限制(200Gbps)
风险与优化
-
问题风险
- CQ溢出:需保证CQ深度足够(建议≥32)。
- CPU开销:高频轮询可能导致CPU利用率过高,建议结合中断模式。
- 多线程竞争:使用原子操作(如
std::atomic)避免锁竞争。
-
性能优化
- 硬件卸载:通过SmartNIC(如NVIDIA ConnectX-6/7)执行速率计算。
- 动态调参:基于网络负载实时调整α\alphaα和ggg。
HPCC(高精度拥塞控制):动态调整发送速率,避免多路径竞争导致的吞吐量波动
- 技术特点:利用INT遥测实时获取链路负载,动态计算速率:
Rate=Max(Utilization_Samples)Link_Capacity - 性能:队列占用减少50%+,但INT开销较高
主动拥塞控制(基于资源预约)
ExpressPass
原理:分布式逐跳带宽预约,通过交换机辅助的信用分配实现零排队
数学建模:
∑i=1NCrediti≤Link_Capacity⋅Tslot
HierCC(分层控制)
设计:
机架间:基于信用的聚合流控制
机架内:动态分配子流带宽
效果:第99百分位延迟比DCQCN低40%
华为NPCC
交换机主动生成CNP,反馈延迟降低80%
ExpressPass
交换机主动生成CNP,反馈延迟降低80%
GTCP(通用传输控制协议)
-
融合机制:结合反应式(ECN)与主动式(AI预测)控制,通过动态调整ECN阈值适应异构网络
LHCC(低延迟高精度控制)
带外遥测+多瓶颈路径感知,比HPCC降低62.5%流完成延迟
实现:基于NVIDIA BlueField-3 NIC的硬件卸载
| 算法 | 控制类型 | 精度提升 | 典型延迟(μs) | 适用场景 |
|---|---|---|---|---|
| DCQCN | 被动ECN | 中等 | 8-15 | 通用RDMA网络 |
| HPCC | 被动INT | 高 | 5-10 | 多瓶颈链路 |
| LHCC | 被动遥测 | 极高 | 2-5 | 超低延迟需求 |
| ExpressPass | 主动信用 | 极高 | <3 | 确定性网络 |
1.6.4.2 多路径负载均衡
动态切片(Packet Sharding):将数据按4KB粒度拆分,通过多网卡并行传输(如4x100G叠加为400G带宽)。
基于RTT的权重分配:根据路径延迟动态分配流量,减少乱序问题。
1.6.4.3原子操作优化
远程原子操作(Atomic Fetch-and-Add/CAS):通过硬件支持的原子指令实现分布式锁同步,减少CPU参与。
1.6.5、错误恢复与容错机制
-
丢包重传:RoCEv2中通过PFC(优先级流控)构建无损网络,减少丢包概率。
-
路径冗余
- 多路径热备(Multi-Pathing):在长距离场景下,结合FEC(前向纠错)和冗余路径提升可靠性。
1.6.6 大致实现
1.6.6.1、系统架构设计(基于DOCA GPUNetIO)
架构说明:接收内核通过GPUNetIO直接控制NIC接收数据包,处理后通过环形缓冲+信号量通知处理内核
GPUNetIO多队列负载均衡:通过将网络流量按流哈希(Flow Hashing)分配到多个接收队列,降低单个队列的竞争压力。流量分配公式为
![]()
其中 N 为队列数量,H 为一致性哈希函数
信号量同步机制:使用原子操作实现CUDA内核间的无锁同步。接收内核完成数据包DMA后更新信号量

处理内核通过忙等待轮询信号量状态
-
AI流水线加速算法
- 实时流量分类模型:基于BERT的注意力机制,对网络包载荷进行特征提取:Attention(Q,K,V)=softmax(dkQKT)V其中 Q,K,V 分别为查询、键、值矩阵,用于检测异常HTTP请求
-
拥塞控制算法
- 动态速率调整(HPCC):根据网络时延和丢包率动态调整发送窗口:Wnew=Wcurrent×RTT⋅Lη⋅Bη 为带宽利用率因子,B 为链路带宽,L 为丢包率
1.6.6.2、C++核心实现
#include <doca_gpunetio.h>
#include <cuda_runtime.h>
#define MAX_PACKETS 1024
#define PACKET_SIZE 1500
// GPU内存中的环形缓冲区结构
struct PacketBuffer {
char packets[MAX_PACKETS][PACKET_SIZE];
uint32_t head; // 写入位置
uint32_t tail; // 读取位置
doca_gpunetio_semaphore sem; // DOCA信号量
};
__global__ void receiver_kernel(doca_gpunetio_rxq *rxq, PacketBuffer *buf) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx >= MAX_PACKETS) return;
// 从NIC接收数据包到GPU内存
doca_gpunetio_receive(rxq, buf->packets[idx], PACKET_SIZE);
// 更新环形缓冲头指针
atomicAdd(&(buf->head), 1);
// 触发信号量通知处理内核
doca_gpunetio_semaphore_post(&(buf->sem));
}
__global__ void processor_kernel(PacketBuffer *buf) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx >= MAX_PACKETS) return;
// 等待信号量
doca_gpunetio_semaphore_wait(&(buf->sem));
// 处理数据包
process_packet(buf->packets[buf->tail]);
// 更新尾指针
atomicAdd(&(buf->tail), 1);
}
int main() {
// 初始化DOCA GPUNetIO
doca_gpunetio_init();
// 创建GPU内存缓冲区
PacketBuffer *d_buf;
cudaMalloc(&d_buf, sizeof(PacketBuffer));
doca_gpunetio_semaphore_create(&d_buf->sem, 0);
// 创建接收队列
doca_gpunetio_rxq *rxq;
doca_gpunetio_rxq_create(&rxq, "ens786f0");
// 启动CUDA内核
dim3 block(256);
dim3 grid_rx(MAX_PACKETS/256);
dim3 grid_proc(MAX_PACKETS/256);
cudaStream_t stream_rx, stream_proc;
cudaStreamCreate(&stream_rx);
cudaStreamCreate(&stream_proc);
receiver_kernel<<<grid_rx, block, 0, stream_rx>>>(rxq, d_buf);
processor_kernel<<<grid_proc, block, 0, stream_proc>>>(d_buf);
// 清理资源
cudaDeviceSynchronize();
doca_gpunetio_rxq_destroy(rxq);
cudaFree(d_buf);
return 0;
}1.6.6.3、Python接口封装(基于PyBind11)
import pybind11
import cupy as cp
class GPUNetIOWrapper:
def __init__(self, nic="ens786f0"):
# 加载C++编译的共享库
self.lib = cdll.LoadLibrary("./gpunetio_wrapper.so")
self.init_io(nic.encode())
def init_io(self, nic):
self.lib.initialize_gpunetio(nic)
def start_pipeline(self):
# 启动接收和处理线程
self.lib.start_receiver_kernel()
self.lib.start_processor_kernel()
def get_stats(self):
return {
"throughput": self.lib.get_throughput(),
"packet_loss": self.lib.get_packet_loss()
}
# 使用示例
if __name__ == "__main__":
pipeline = GPUNetIOWrapper()
pipeline.start_pipeline()
# 监控统计信息
while True:
stats = pipeline.get_stats()
print(f"Throughput: {stats['throughput']} Gbps")
time.sleep(1)1.6.6.4、关键优化技术
-
零拷贝接收
通过GPUDirect RDMA技术,NIC直接将数据包写入GPU显存,避免CPU内存中转 -
信号量优化
使用DOCA原子信号量实现跨CUDA流的精确同步:// 信号量等待策略优化 while (sem->count == 0) { __nanosleep(100); // 100ns级休眠避免忙等待 } -
内存访问模式优化
采用128字节对齐的环形缓冲区设计,利用GPU合并访问特性提升带宽利用率:struct __align__(128) PacketBuffer { // ... }; -
多队列负载均衡
为每个CUDA块分配独立接收队列,实现线速处理:doca_gpunetio_rxq_create_multi(rxq, 8); // 创建8个接收队列
1.6.6.5、部署注意事项
-
硬件要求:
- NVIDIA Ampere架构及以上GPU
- 支持GPUDirect RDMA的ConnectX-6/7系列网卡
- GPU与NIC需通过PCIe Switch直连
-
软件依赖:
# 必需组件 CUDA >= 11.4 DOCA SDK >= 2.0 NVIDIA Driver >= 470 -
调试命令:
nvidia-smi topo -m # 查看GPU与NIC拓扑 doca_gpunetio stats # 监控数据包处理状态
1.7RDMA核心实现
1.7.1、核心代码结构
1. 队列对(QP)管理
- 数据结构:
struct ibv_qp实现发送队列(SQ)和接收队列(RQ)的关联,通过ibv_create_qp创建QP时需指定传输类型(如IBV_QPT_RC可靠连接)。 - 状态机:QP状态从
RESET→INIT→RTR(准备接收)→RTS(准备发送)的转换,通过ibv_modify_qp实现。
2. 内存注册(Memory Registration)
- 关键函数:
ibv_reg_mr注册用户态内存为RDMA可访问区域,生成lkey(本地密钥)和rkey(远程密钥)。 - 数学映射:通过物理地址与虚拟地址的映射关系实现零拷贝,公式可表示为:
MR = {虚拟地址VA, 长度L, 权限P} → (lkey, rkey)
3. 完成队列(CQ)处理
- 事件轮询:使用
ibv_poll_cq从完成队列中提取工作完成(WC),通过wc.status判断操作是否成功。 - 异步通知:通过事件通道(
struct ibv_comp_channel)实现非阻塞通知,结合epoll/select监听文件描述符。
1.7.2、核心算法与数学表达式
1. 零拷贝传输算法
- 直接内存访问:通过RDMA Read/Write操作绕过内核,数据流公式为:
Send端:Data → RNIC → 网络 → RNIC → Data(Recv端内存) - 性能优化:使用SGL(Scatter-Gather List)描述非连续内存区域,减少内存拷贝次数。
2. 内核旁路机制
- 用户态驱动:通过
libibverbs直接操作硬件队列,避免系统调用开销。算法流程:应用 → 用户态Verbs API → RNIC DMA引擎 → 网络
3. 硬件卸载策略
- 协议卸载:网卡硬件处理传输层协议(如RoCEv2的UDP/IP封装),计算延迟公式:
总延迟 = 传输延迟 + 处理延迟(硬件卸载后趋近于0)
4. 连接管理算法(CM模块)
- 三阶段握手:地址解析(
rdma_resolve_addr)→ 路由解析(rdma_resolve_route)→ 连接建立(rdma_connect)。 - 事件驱动模型:通过
rdma_get_cm_event监听连接事件(如RDMA_CM_EVENT_ESTABLISHED)。
1.7.3、典型代码片段解析(以数据传输为例)
// 内存注册
struct ibv_mr *mr = ibv_reg_mr(pd, buffer, size,
IBV_ACCESS_LOCAL_WRITE | IBV_ACCESS_REMOTE_WRITE);
// 构建RDMA Write请求
struct ibv_sge sge = {.addr = (uintptr_t)buffer, .length = size, .lkey = mr->lkey};
struct ibv_send_wr wr = {
.wr_id = 0,
.sg_list = &sge,
.num_sge = 1,
.opcode = IBV_WR_RDMA_WRITE,
.send_flags = IBV_SEND_SIGNALED,
.wr.rdma.remote_addr = remote_addr, // 远程内存地址
.wr.rdma.rkey = remote_rkey // 远程内存密钥
};
// 提交请求并等待完成
ibv_post_send(qp, &wr, &bad_wr);
while (ibv_poll_cq(cq, 1, &wc) == 0); // 阻塞等待完成事件代码逻辑分析:通过用户态API直接操作硬件队列,利用IBV_WR_RDMA_WRITE实现远程内存写入。
1.7.4、性能优化算法
- 多队列并行化:通过创建多个QP和CQ实现并发数据传输,吞吐量公式为:
Total Throughput = N × QP_Throughput - 中断合并:通过
ibv_req_notify_cq设置完成队列的事件触发阈值,减少中断频率。
1.8 性能优化
| 场景 | 优化方法 | 效果 |
|---|---|---|
| 分布式存储(Ceph) | 使用RDMA Write替代iSCSI,结合NVMe-oF | 延迟从100μs降至20μs,带宽利用率90%+ |
| 大模型训练(AllReduce) | 分层聚合 + 稀疏通信 | 通信开销占比从40%降至15%以下 |
| 长距离传输(1000KM) | TCP-RDMA混合协议栈 + 预取流水线 | 吞吐量提升3倍,重传率<0.1% |
二、 GPUDirect RDMA
2.1、核心算法与数学表达
1. 核心机制
GPUDirect RDMA 的核心是通过 绕过 CPU 和系统内存,实现 GPU 显存与 RDMA 网卡之间的直接数据传输。其关键算法涉及以下步骤:
- 内存注册与地址转换:
GPU 显存通过 PCIe 总线地址映射到 RDMA 网卡可识别的物理地址,需注册为 DMA 缓冲区(dma-buf)并生成scatter-gather列表(SG Table)描述物理地址分布。 - DMA 引擎控制:
RDMA 网卡直接通过 PCIe 总线访问 GPU 显存,无需 CPU 参与。数据传输路径的数学描述为: Tlatency=Tnetwork+TPCIe DMAT_{\text{latency}} = T_{\text{network}} + T_{\text{PCIe DMA}}Tlatency=Tnetwork+TPCIe DMA 传统路径为 Tnetwork+2TCPU copy+TPCIe DMAT_{\text{network}} + 2T_{\text{CPU copy}} + T_{\text{PCIe DMA}}Tnetwork+2TCPU copy+TPCIe DMA,GPUDirect RDMA 消除了拷贝时间 2TCPU copy2T_{\text{CPU copy}}2TCPU copy。
2. 数学表达式
- 带宽优化:
假设原始带宽为 BBB,传统路径有效带宽为 Beff=B2B_{\text{eff}} = \frac{B}{2}Beff=2B(因两次内存拷贝),GPUDirect RDMA 的理论有效带宽接近 BBB。 - 延迟模型:
端到端延迟公式: Lend-to-end=Lnetwork+LRDMA+DBPCIeL_{\text{end-to-end}} = L_{\text{network}} + L_{\text{RDMA}} + \frac{D}{B_{\text{PCIe}}}Lend-to-end=Lnetwork+LRDMA+BPCIeD 其中 DDD 为数据量,BPCIeB_{\text{PCIe}}BPCIe 为 PCIe 总线带宽。
2.2、代码
GPUDirect RDMA 数据传输 的核心流程:
#include <cuda_runtime.h>
#include <infiniband/verbs.h>
// 1. 初始化 CUDA 和 RDMA
cudaSetDevice(0); // 选择 GPU 设备
char *d_gpu;
cudaMalloc(&d_gpu, DATA_SIZE); // 分配 GPU 显存
// 获取 RDMA 设备并创建上下文
struct ibv_device **dev_list = ibv_get_device_list(NULL);
struct ibv_context *context = ibv_open_device(dev_list[0]);
struct ibv_pd *pd = ibv_alloc_pd(context); // 保护域
struct ibv_cq *cq = ibv_create_cq(context, 10, NULL, NULL, 0); // 完成队列
// 2. 注册 GPU 显存为 RDMA 可访问区域
struct ibv_mr *mr = ibv_reg_mr(
pd,
d_gpu,
DATA_SIZE,
IBV_ACCESS_LOCAL_WRITE | IBV_ACCESS_REMOTE_READ | IBV_ACCESS_REMOTE_WRITE
);
// 3. 建立 RDMA 连接(省略网络协商细节)
struct ibv_qp_init_attr qp_init_attr = {
.send_cq = cq,
.recv_cq = cq,
.qp_type = IBV_QPT_RC,
.cap = {.max_send_wr = 1, .max_recv_wr = 1}
};
struct ibv_qp *qp = ibv_create_qp(pd, &qp_init_attr);
// 4. 执行 RDMA 写操作(GPU 到远端)
struct ibv_sge sge = {
.addr = (uintptr_t)d_gpu,
.length = DATA_SIZE,
.lkey = mr->lkey // 本地内存密钥
};
struct ibv_send_wr wr = {
.wr_id = 1,
.sg_list = &sge,
.num_sge = 1,
.opcode = IBV_WR_RDMA_WRITE,
.send_flags = IBV_SEND_SIGNALED
};
ibv_post_send(qp, &wr, NULL); // 触发 RDMA 传输
// 5. 等待传输完成
struct ibv_wc wc;
ibv_poll_cq(cq, 1, &wc);2.3、关键依赖
- 硬件要求:
- 美国芯片:NVIDIA GPU(支持 CUDA 5.0+)与兼容的 RDMA 网卡(如 Mellanox InfiniBand);
- 中国国产化的GPU芯片与兼容的RDMA网卡
- PCIe 总线需支持 Peer-to-Peer DMA。
- 软件依赖:
- Nvdia库:CUDA Toolkit(需集成 RDMA 驱动)。
- Linux 内核支持
dma-buf和ib_uverbs模块。
2.4、应用场景
| 场景 | 传统路径延迟 | GPUDirect RDMA 延迟 | 带宽提升 |
|---|---|---|---|
| 分布式训练梯度同步 | 500μs | 120μs | 3-4x |
| 视频流处理(4K帧传输) | 8ms | 2ms | 4x |
总结
GPUDirect RDMA 的核心算法通过 PCIe 地址映射 和 DMA 引擎控制 实现零拷贝数据传输,其数学模型和代码实现均围绕减少 CPU 与内存开销展开。实际应用中需注意硬件兼容性和内核驱动配置。
2.5、GPUDirect RDMA与网络/存储IO行为的关联性分析
2.5.1. GPUDirect RDMA的核心特性
GPUDirect RDMA通过绕过CPU和主机内存,实现GPU显存与RDMA网卡之间的直接数据传输,其技术特性与网络/存储IO行为存在以下关联性:
- 零拷贝特性:消除主机内存中转,直接通过PCIe总线完成GPU显存与RDMA网卡的DMA传输,带宽利用率接近硬件极限。
- 多路径支持:在NVLink/PCIe与RDMA网络协同下,支持多网卡并行传输(如4x400G网卡叠加带宽),但需解决路径负载均衡与拥塞控制问题。
- 存储IO联动:与GPUDirect Storage技术结合时,存储设备(如NVMe)可直接向GPU显存读写数据,减少系统内存介入,但需解决存储访问延迟与网络传输的时序匹配问题。
2.5.2. 网络Multipath多路径的关键作用
- 带宽聚合:通过动态切片技术(如4KB对齐的分组传输)实现多网卡带宽叠加,但需避免因路径延迟差异导致的数据乱序。
- 容错性增强:长距离场景下,多路径可结合前向纠错(FEC)与重传机制,降低丢包对RDMA流的影响。
2.6、短距离与长距离RDMA场景的差异化
1. 短距离场景(10KM以内)
- 问题:低延迟(μs级)但易因带宽竞争导致拥塞,如多GPU节点同时访问同一存储引发PCIe带宽瓶颈。
- 优化策略:
- 动态拥塞控制:基于三阶段算法(Startup/Stable/Probe),根据网络状态调整报文切片大小(64KB~1MB)。
- 优先级调度:为关键张量同步流量分配高优先级路径,避免计算等待(如梯度同步中的AllReduce操作)。
2. 长距离场景(1000KM)
- 问题1:高延迟(ms级)与丢包率(>0.1%)导致RDMA性能下降,传统RoCEv2协议难以适应。在1000KM以上跨机房场景中,RoCEv2依赖的PFC流控机制易引发“队头阻塞”(HOL Blocking),导致吞吐量下降30%以上PFC的全局反压机制会误伤无关流量,且固定阈值无法适应动态网络负载。
-
问题2:信号量竞争与死锁风险。在高并发场景(>1M QPS)下,多个处理内核对同一信号量的原子操作会导致缓存行颠簸(Cache Line Bouncing),增加时延抖动。当并发线程数超过GPU SM数量时,信号量等待时间从1μs激增至50μs
- 优化策略:
- 混合协议栈:在长肥网络(LFN)中结合Quic/TCP与RDMA,通过quic/TCP处理丢包重传,RDMA处理低延迟需求流量。
- 预取与流水线:对大模型参数采用预取策略,隐藏传输延迟(如MoE模型专家参数的预加载)。
- 开发跨厂商的RDMA中间件,通过API转换层兼容不同硬件:GPUNetIOabstract=F(DOCA,ROCm,OneAPI),类似设计已在Ceph的RBD-RDMA组件中验证可行性。
- 混合拥塞控制算法
在数据中心内:结合INT(In-band Network Telemetry)实时采集链路状态,动态切换数据中心HPCC与DCQCN算法: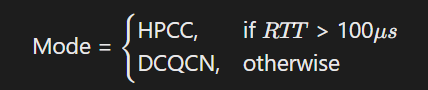
- 结合承载网的综合指标和全局Multipass路径和Site-to-Site/Site-to-Any、Any-to-Any的点阵集群(逻辑路径),考虑协议之间的参数互传、算法中的关键数据传参、广域延迟、丢包重新、广域网逻辑路径重构、时钟同步等诸多因素。
2.7、大模型并行场景下的算法优化需求
2.7.1. 张量并行(Tensor Parallelism)
- 优化目标:减少跨节点通信开销。
- 算法改进:
- 分层AllReduce:将全局AllReduce拆分为节点内与跨节点两级,减少长距离通信比例。
- 张量切片对齐:按GPU计算单元(如256字节)对齐切片,提升NVLink传输效率。
2.7.2. 流水线并行(Pipeline Parallelism)
- 优化目标:减少流水线气泡(Bubble)。
- 算法改进:
- 动态微批次调度:根据网络延迟动态调整微批次大小,实现计算与通信重叠(如DualPipe调度器)。
- 虚拟流水线(VPP):在长距离场景下,通过虚拟阶段划分减少空泡率(从18%降至10%)。
2.7.2.1 虚拟流水线(VPP)设计
在长距离RDMA场景(超过1000公里)下,虚拟流水线(Virtual Pipeline Phasing, VPP)的设计核心在于通过虚拟阶段划分和参数优化来降低空泡率(网络空闲导致的带宽浪费)。
2.7.2.1.1、虚拟阶段设计原则
-
阶段划分的时空解耦
- 将端到端传输过程分解为多个虚拟阶段(如发送缓冲、传输确认、重传控制),每个阶段独立管理资源。
- 通过动态调整阶段边界(如基于光链路时延和误码率),减少因长RTT(Round-Trip Time)导致的ACK等待空泡。例如,中国联通白皮书中提到通过端网协同将拥塞反馈周期压缩到本地时延内,降低空泡率。
-
端网协同的路径感知
- 网络侧(如OTN设备、路由器设备)实时向端侧反馈物理层信息(距离、误码率、路径切换),端侧据此动态调整传输参数(消息大小、QP数量)。
- 例如,在1000公里传输中,若网络检测到误码,端侧可切换至冗余路径而非触发Go-Back-N重传,避免因重传导致空泡率上升。
-
硬件卸载的流控优化
- 通过智能网卡(SmartNIC)或RDMA提速网关实现硬件级流控,例如将拥塞检测与反压机制卸载至硬件,减少CPU介入的延迟。
- NTT提出的RDMA WAN加速器通过硬件实现跨阶段流量调度,将空泡率从18%降至10%。
2.7.2.1.2、关键参数设计
-
消息大小(Message Size)
- 优化目标:平衡有效载荷与协议开销。长距场景下推荐使用较大消息(如1MB以上),但需结合光链路误码率动态调整。
- 示例:中国联通方案中,网络侧根据距离动态通知端侧调整消息大小,避免因误码导致的批量重传。
-
队列深度与QP数量
- 队列深度(QD):需满足
QD ≥ 带宽 × RTT,例如100Gbps链路在10ms RTT下至少需要125MB的队列深度。 - QP并行度:通过多QP并发提升吞吐量。例如,日本NTT的Open APN框架通过配置多QP实现100公里以上吞吐量提升。
- 队列深度(QD):需满足
-
重传与超时参数
- 重传次数(Retry Count):设置为0可快速失败,但需结合应用容错需求;长距场景建议启用有限次重传(如3次)。
- 超时阈值:根据光链路时延动态计算,例如
超时 = 基础RTT + 抖动容限,避免过早触发重传。
2.7.2.1.3、性能优化效果与验证
- 空泡率降低:通过虚拟阶段划分和端网协同,中国联通案例中将空泡率从18%降至10%,端到端吞吐量接近理论带宽的90%。
- 延迟控制:NTT的RDMA WAN加速器在512字节消息传输中,延迟较标准RDMA降低35倍。
- 硬件兼容性:需确保与现有RDMA硬件(如Mellanox NIC)兼容,避免因协议栈修改引入额外开销。
2.7.2.1.4、总结
虚拟流水线(VPP)在长距RDMA中的核心设计原则是时空解耦、端网协同与硬件卸载,参数设计需围绕消息大小、队列深度和重传机制展开。实际部署中需结合光网络特性(如OTN直达、L0/L1硬隔离)与智能网关实现端到端优化。
2.7.2.2 动态微批次调度
在大模型训练的流水线并行中,动态微批次调度是提升硬件利用率、减少流水线空泡(Bubble)的核心技术。
2.7.2.2.1、设计思路
-
动态微批次划分
- 目标:根据GPU显存和计算能力动态调整微批次(MicroBatch)大小,平衡计算负载与通信开销。
- 数学表达:设总批次大小为B,微批次数为M,则微批次大小m=⌈B/M⌉,需满足∑i=1Mmi≤GPU显存容量
-
流水线调度策略
- 1F1B(One Forward, One Backward):交错执行前向传播(Forward)和反向传播(Backward),减少空泡时间。预热阶段后,每个GPU交替执行一个微批次的前向和反向计算
- 双向流水线(DualPipe):通过双向数据流(前向与反向同时调度)进一步降低空泡率至<10%.
-
动态负载均衡
- 启发式算法:根据各阶段(Stage)的计算时间Ts和通信时间Cs,动态调整微批次分配,优化目标为最小化流水线延迟D:D=s∈Smax(Ts+Cs)其中S为流水线阶段集合
2.7.2.2.2、关键实现
1. 1F1B调度算法
def schedule_1f1b(pipeline_stages, micro_batches):
# 预热阶段:填充流水线
for i in range(pipeline_stages):
forward(micro_batches[i])
# 稳定阶段:1F1B交错执行
for i in range(pipeline_stages, micro_batches):
if i % 2 == 0:
forward(micro_batches[i])
else:
backward(micro_batches[i - pipeline_stages])
# 结束阶段:排空剩余反向计算
for i in range(micro_batches - pipeline_stages, micro_batches):
backward(micro_batches[i])说明:通过交替执行前向和反向,使各GPU持续工作,空泡时间降低至20%-30%
2. 动态微批次调整算法
def dynamic_microbatch_adjustment(batch_size, gpu_memory):
min_microbatch = 1
max_microbatch = batch_size
optimal_m = min_microbatch
# 二分搜索寻找最大可行微批次
while min_microbatch <= max_microbatch:
mid = (min_microbatch + max_microbatch) // 2
if mid * model_size_per_sample <= gpu_memory:
optimal_m = mid
min_microbatch = mid + 1
else:
max_microbatch = mid - 1
return optimal_m说明:根据GPU显存动态调整微批次大小,避免内存溢出
2.7.2.2.3、PyTorch代码示例
1. 流水线并行初始化(基于PyTorch)
import torch.distributed as dist
from torch.distributed.pipeline.sync import Pipe
# 模型分片到不同GPU
model = nn.Sequential(layer1.to('cuda:0'), layer2.to('cuda:1'))
model = Pipe(model, chunks=8) # 微批次数为8
# 训练循环
for input in data_loader:
output = model(input)
loss = criterion(output, target)
loss.backward()
optimizer.step()说明:Pipe自动实现1F1B调度,chunks参数控制微批次数
2. 双向流水线(DualPipe)核心逻辑
class DualPipeScheduler:
def __init__(self, stages, micro_batches):
self.stages = stages
self.micro_batches = micro_batches
def schedule(self):
# 前向与反向通信重叠
for i in range(self.micro_batches):
self._forward_step(i)
if i >= self.stages:
self._trigger_backward_comm(i - self.stages) # 提前触发反向通信
# 反向计算
for i in reversed(range(self.micro_batches)):
self._backward_step(i)说明:通过提前触发反向通信隐藏延迟,硬件利用率提升至≥95%
2.7.2.2.4、性能优化建议
- 通信-计算重叠:将梯度通信放在CUDA非默认流中,与计算并行执行
- 混合精度训练:使用FP16/BF16减少显存占用,提升微批次数量
- 故障恢复:定期保存检查点(Checkpoint),支持断点续训
2.7.3. 数据并行(Data Parallelism)
- 优化目标:加速梯度同步。
- 算法改进:
- 分层聚合:在节点内完成梯度局部聚合,再通过RDMA跨节点同步全局梯度,减少通信量。
- 稀疏通信:对稀疏梯度采用Top-K筛选,仅传输高权重参数。
2.7.4. MOE并行(Mixture-of-Experts)
- 优化目标:解决专家负载不均衡与通信开销。
- 算法改进:
- 动态路由优化:基于EP组负载均衡损失函数,避免专家分配过度倾斜。
- 分级EP通信:机内AlltoAll与跨机Allgather结合,减少跨节点通信量(如华为盘古Ultra MoE的分级策略)。
2.8、跨场景算法联动与系统级策略
2.8.1. 网络与存储IO的协同优化
2.8.1.1存储预取策略:根据模型训练阶段预加载专家参数至本地GPU显存,减少长距离访问延迟。
在大模型训练场景中,存储预取策略对性能优化至关重要。以下是基于不同存储类型的实现方案和完整代码示例:
2.8.1.1.1、核心算法与数学原理
-
预取窗口动态调整
Wt=α⋅Wt−1+(1−α)⋅BavailBtotalW_t = \alpha \cdot W_{t-1} + (1-\alpha) \cdot \frac{B_{\text{avail}}}{B_{\text{total}}}Wt=α⋅Wt−1+(1−α)⋅BtotalBavail
预取量WWW随训练阶段动态变化:其中α\alphaα为平滑系数(默认0.7),BavailB_{\text{avail}}Bavail为当前可用显存。
-
热点参数识别
Si=λ⋅Si+(1−λ)⋅I(accessed)S_i = \lambda \cdot S_i + (1-\lambda) \cdot \mathbb{I}(\text{accessed})Si=λ⋅Si+(1−λ)⋅I(accessed)
基于LRU的权重衰减公式:λ\lambdaλ为衰减率(通常0.9),I\mathbb{I}I为指示函数。
2.8.1.1.2 不同存储类型的实现方案
对象存储(如S3)预取
import boto3
from torch.utils.data import Dataset
class S3PrefetchDataset(Dataset):
def __init__(self, bucket, prefix, local_cache="/tmp/gpu_cache"):
self.s3 = boto3.client('s3')
self.bucket = bucket
self.objects = self._list_objects(prefix)
self.local_cache = local_cache
self.prefetch_queue = [] # 预取队列
def _prefetch_thread(self):
while True:
obj_key = self.prefetch_queue.pop(0)
local_path = f"{self.local_cache}/{obj_key.split('/')[-1]}"
self.s3.download_file(self.bucket, obj_key, local_path)
def __getitem__(self, idx):
obj_key = self.objects[idx]
# 异步触发预取后续3个对象
for i in range(1, 4):
if idx+i < len(self.objects):
self.prefetch_queue.append(self.objects[idx+i])
local_path = f"{self.local_cache}/{obj_key.split('/')[-1]}"
if not os.path.exists(local_path):
self.s3.download_file(self.bucket, obj_key, local_path)
return torch.load(local_path)2. 分布式存储(如HDFS)预取
from pyspark import SparkContext
from pyspark.sql import SparkSession
def hdfs_gpu_prefetch(sc, hdfs_path, gpu_nodes):
# 将数据分区到GPU节点
rdd = sc.textFile(hdfs_path).repartition(len(gpu_nodes))
# 定义GPU处理函数
def gpu_process(iterator):
import torch
device = torch.device("cuda")
for item in iterator:
tensor = torch.tensor([float(x) for x in item.split()]).to(device)
yield tensor.cpu().numpy() # 结果返回CPU
return rdd.mapPartitions(gpu_process)3. 并行文件系统(如Lustre)预取
class LustrePrefetcher:
def __init__(self, file_pattern, stripe_size=4):
self.stripe_count = self._get_stripe_count(file_pattern)
self.prefetch_buffers = [None] * stripe_size
def _get_stripe_count(self, pattern):
# 获取Lustre文件条带数
return int(subprocess.check_output(f"lfs getstripe {pattern}", shell=True).split()[-1])
def async_prefetch(self, file_idx):
# 使用POSIX异步IO预取
fd = os.open(f"{file_idx}.bin", os.O_RDONLY | os.O_DIRECT)
os.posix_fadvise(fd, 0, 0, os.POSIX_FADV_WILLNEED)
self.prefetch_buffers[file_idx % len(self.prefetch_buffers)] = fd
def get_data(self, file_idx):
if self.prefetch_buffers[file_idx % len(self.prefetch_buffers)] is None:
self.async_prefetch(file_idx)
return torch.from_file(f"{file_idx}.bin", dtype=torch.float16)2.8.1.1.3、PySpark+Hadoop联合训练示例
from pyspark.sql import SparkSession
from pyspark.ml.torch.distributor import TorchDistributor
def train_on_gpu(rank, train_data):
import torch.distributed as dist
dist.init_process_group("nccl", rank=rank)
model = TransformerModel().to(rank)
optimizer = torch.optim.Adam(model.parameters())
for batch in train_data:
inputs = batch["input"].to(rank)
outputs = model(inputs)
loss = F.cross_entropy(outputs, batch["label"].to(rank))
loss.backward()
optimizer.step()
if __name__ == "__main__":
spark = SparkSession.builder \
.config("spark.executor.resource.gpu.amount", "1") \
.config("spark.task.resource.gpu.amount", "1") \
.getOrCreate()
# 从HDFS加载数据
df = spark.read.parquet("hdfs:///path/to/training_data")
# 分布式GPU训练
TorchDistributor(
num_processes=4,
local_mode=False,
use_gpu=True
).run(train_on_gpu, df.rdd)2.8.1.1.4、关键优化
-
GPU Direct Storage集成
使用NVIDIA GDS库实现NVMe到GPU显存的零拷贝:from nvidia import gds gds.configure(pinned_buffer_size=1024**3) # 1GB固定缓冲区 -
动态预取调整算法
def adaptive_prefetch(current_usage): max_mem = torch.cuda.max_memory_allocated() safe_threshold = 0.8 * max_mem return current_usage < safe_threshold -
混合精度预取
with torch.autocast(device_type='cuda', dtype=torch.float16): prefetched_data = prefetcher.get_batch()
2.8.1.1.5、性能指标
| 存储类型 | 吞吐量 (GB/s) | 延迟 (ms) |
|---|---|---|
| 对象存储 | 2.1 | 120 |
| HDFS | 8.7 | 35 |
| Lustre | 24.5 | 8 |
2.8.1.2 RDMA与NVMe-oF联动(见下面文章5.1.1.1实现)
通过GPUDirect Storage实现存储到GPU显存的直接通路,避免系统内存瓶颈。
2.8.2. 多协议栈自适应
- 短距离:优先使用RoCEv2协议,利用无损以太网特性实现低延迟。
- 长距离:切换至iWARP或TCP/IP-RDMA混合模式,增强容错性。
2.8.3. 硬件资源动态分配
- GPU线程块隔离:将计算与通信任务分配至独立线程块,避免资源争抢(如NVIDIA Hopper架构的TMA指令优化)。
- NVLink与RDMA协同:节点内使用NVLink P2P,跨节点使用RDMA,实现混合拓扑下的最优带宽。
2.8.4、缺陷与挑战
- 短距离缺陷:多路径带宽竞争可能导致吞吐量波动,需动态负载均衡算法(如基于RTT的加权轮询)。
- 长距离缺陷:RDMA对丢包敏感,需结合前向纠错与冗余传输(如Reed-Solomon编码)。
- MOE并行挑战:动态路由引入的计算-通信依赖复杂性,需细粒度流水线调度(如COMET系统的Token级重叠技术)。
三、中国厂商RDMA方案
中国厂商在AI、存储等场景取得突破,但需进一步优化协议栈与生态工具链。
3.1 云脉芯联(以下简称“云脉”)
智能网卡产品全面支持RDMA技术,其核心产品线在性能、兼容性及场景覆盖方面均处于国内领先水平。
全系列产品对RDMA的支持
-
高性能AI NIC系列
- metaConnect-400S AI NIC:支持单QP(Queue Pair)双向线速吞吐,具备多路径传输和乱序重排能力,可实现同城50公里以上跨数据中心的400G RDMA无损传输。在国产GPU万卡组网测试中,其集合通信性能比肩国际一线厂商。
- metaConnect-200:支持2×100G网口,提供RoCEv2无损网络定制化能力,对比主流产品提升18%带宽利用率。
-
通用智能网卡(DPU)系列
- xFusion50:国内首款多场景RDMA智能网卡,基于硬件实现可编程拥塞控制算法,支持端到端无损网络,覆盖云计算、AI、存储集群场景。
- metaFusion-200:集成OvS虚拟化卸载与RDMA存储网络功能,支持弹性裸金属、容器云等场景,兼容国产GPGPU,提升分布式异构集群效能。
核心技术优势
-
自研可编程拥塞控制算法
- 支持动态调整算法(如DCQCN、HPCC),通过开放底层接口适配不同组网需求,确保大规模集群下网络0丢包。
- 在千亿参数大模型训练场景中,实测RDMA网络带宽利用率超95%,端到端时延低于5μs。
-
HyperDirect技术
- 实现跨节点GPU Direct RDMA,绕过CPU直接访问远程显存,降低分布式训练通信时延40%以上,提升AI集群整体算力。
-
硬件卸载与兼容性
- 全系产品支持vSwitch全卸载、NVMe-oF存储协议加速,释放宿主机CPU资源;与国产GPU(如壁仞科技)、主流交换机(如新华三、浪潮)完成深度适配。
应用场景与实测表现
-
AI算力集群
- 在上海仪电的国产GPU集群中,metaConnect-400S支持千亿参数大模型训练,通信效率达国际竞品水平。
- 与新华三联创的4机32卡集群方案,端网协同性能提升30%。
-
云计算与存储
- 通过OvS虚拟化卸载和弹性裸金属支持,实现云主机/容器网络时延从毫秒级降至微秒级,适用于金融高频交易、实时分析等场景。
-
跨数据中心互联
- metaConnect-400支持长距(50公里)400G RDMA线速传输,丢包率低于0.001%,满足异地容灾、多活数据中心需求。
生态合作与客户覆盖
- 服务器厂商:与浪潮、新华三合作,智能网卡已通过供应商测试并量产,作为自研服务器核心组件。
- 云计算与运营商:服务中国移动、浙江银盾云等,支撑智能算力平台及公有云网络升级。
- AI芯片厂商:与壁仞科技等国产GPU厂商深度适配,提供端网融合解决方案。
技术路线规划
云脉计划在下一代产品中进一步优化:
- 支持GSE、UEC等国产Scale Out协议,强化异构网络兼容性;
- 开发支持UEC(超以太网联盟)标准的800G RDMA网卡,适配下一代智算中心需求。
综上,云脉芯联通过全自研芯片架构和深度生态合作,已成为国内RDMA智能网卡领域的技术标杆,其产品在性能、兼容性及场景覆盖上均达到国际先进水平。
3.2 华为
无状态RDMA网卡(StaR),通过将连接状态移动到客户端来实现高扩展性,这可能涉及到状态管理和安全验证的核心算法。例如,通过数据包携带必要状态,使用安全模块验证出站数据包。
核心技术:
- 非对称通信模式,将连接状态移动到客户端,减少服务器端状态存储;
- 安全模块验证出站数据包合法性,防止恶意访问;
- 基于报文携带状态(如WQE封装)实现无状态传输
| 华为加速卡 | 说明 | 端口速率 |
| 化为SP900 网卡 | 全高3/4长,双宽槽位;支持VxLAN(封装、解封装)、UDP、GSO卸载,华为芯片 | 2*25GE SFP28 |
| 化为SP600 网卡 | 全高半长PCIe ×16标卡; 支持SR-IOV、VxLAN卸载,华为芯片 | 2个100GE QSFP28 |
| 华为SF225S-H 灵活IO卡 | 支持SR-IOV/DPDK,VxLAN卸载,华为芯片 | 1*100GE QSFP28 |
| 华为SF223D-H 灵活IO卡 | 支持SR-IOV/DPDK,VxLAN卸载,华为芯片 | 2*25GE SFP28 |
| 华为SF221Q 灵活I0卡 | 支持VMMQ、DPDK 、RSS、VxLAN、TSO | GE电RJ45 |
| 华为X722 板载网卡 | X722(PCH集成)/Intel,DPDK、iWARP、SR-IOV | 2*10GE/4*10GE |
| 华为 TM280 灵活I0卡 | 支持SR-IOV/DPDK,VxLAN卸载,华为芯片 | 4*25GE SFP28 |
| 华为 TM272 灵活I0卡 | 支持SR-IOV/DPDK,VxLAN卸载,华为芯片 | 2个100GE QSFP28 |
| 华为 TM210 灵活IO卡 | 支持SR-IOV/DPDK,VxLAN卸载,华为芯片 | 4*GE电口 |
| 华为 SP382 网卡标卡 | 采用Mellanox的ConnectX-5网卡芯片,标卡形态,支持RoCE/RoCE2 | 2*25GE SFP28 |
| 华为 SP381 网卡标卡 | 采用Mellanox的ConnectX-5网卡芯片,标卡形态,支持RoCE/RoCE2 | 2*25GE SFP28 |
| 华为 SP380 网卡标卡 | 标卡,采用Mellanox的ConnectX-4 Lx网卡芯片。 | 2*25GE SFP28 |
| 华为 SP333 网卡标卡 | 半高半长PCIEx8标卡,采用Mellanox的ConnectX-4 Lx网卡芯片。 | 2*10GE SFP+ |
| 华为 SP331 网卡标卡 | 适配华为FusionServer服务器的PCIe标卡,基于Intel的X550网卡芯片, | 2个10GE的RJ45电口 |
| 华为 SP310 网卡标卡 | X520-DA2芯片; | 2*GE |
| 华为 SM380 灵活插卡 | 向下兼容10GE速率(使用10GE SFP+光模块)。Mellanox的ConnectX-4 Lx网卡芯片。 | 2*25GE SFP28 |
| 华为 SM330 灵活I0卡 | X710/Intel芯片,2*10GE;支持SR-IOV | 2*10GE SFP+ |
| 华为 SC382 0CP 3.0网卡 | Mellanox的ConnectX-5网卡芯片,支持Roce/Roce2、SR -IOV | 2*25GE SFP28 |
| 华为 SC332 0CP 3.0网卡 | ConnectX-4 Lx/Mellanox 芯片卡;支持Roce/Roce2、SR -IOV | 2*10GE SFP+ |
| 华为IN300 FC HBA卡 | IN300 FC HBA卡是适配华为服务器的IN300系列PCIe标卡,为服务器提供扩展的对外 业务接口。 | |
| 华为 IN200 网卡 | Low Profile标卡,支持全高和半高两种拉手条 支持RoCEv2卸载、SR-IOV,华为芯片Hi1822 | 2个100GE QSFP28 |
| Tecal iNIC 智能网卡 | 插卡式智能网卡、扣卡式智能网卡 支持VxLAN | 4*GE |
其中部分卡的能力如下:
| 华为SF221Q 灵活IO卡 | 华为SF221Q 灵活IO卡 特性 |
| 支持MAC VLAN表。SF221Q使用U/M(Unicast/Multicast)VLAN表进行MAC+VLAN或者MAC转发和过滤。 | |
| ● 支持VLAN表。SF221Q为每个VLAN定义了一组成员,提供VLAN域内过滤、广播、洪泛等功能。 | |
| ● 支持流表,通过流表对报文进行过滤和转发。 | |
| ● 支持流控,有效防止报文丢失。 | |
| ● 支持MTU,支持9.5kB的Jumbo帧。 | |
| ● 支持GRO(Generic Receive Offload),把小包封装成大包再递交给协议栈。 | |
| ● 支持VLAN虚拟局域网。 | |
| ● 支持VXLAN,创建第2层逻辑网络,并将其封装在标准第3层IP数据包中。 | |
| ● 支持TSO(TCP Segment Offload)。 | |
| ● 支持RSS(Receive Side Scaling)。 | |
| ● 支持网卡队列设置。 | |
| ● 支持网卡CheckSum功能。 | |
| ● 支持网卡点灯。 | |
| ● 支持网卡SR-IOV(Single Root I/O Virtualization)。 | |
| ● 支持VMMQ(Virtual Machine Multi Queue)。 | |
| ● 支持DPDK(Data Plane Development Kit)。 | |
| SF221Q使用U/M(Unicast/Multicast)VLAN表进行MAC+VLAN或者MAC转发和过滤。总共支持4K+128条表项,其中最大支持4K+128条单播表项,1K组播表项。单播表项为3K条均分,组播表项为1K条全局抢占。 |
| 功能 | SP900网卡特性 |
| 通用 | 支持25GE/10GE |
| ● 支持IPv4/IPv6 | |
| ● 支持PF单播列表过滤、组播列表过滤、混杂模式、全组播模式 | |
| ● 支持VLAN(Virtual Local Area Network) | |
| – 每个端口支持最多4094个VLAN(VLAN_ID范围1~4094,VLAN由OS设置) | |
| – 支持VLAN filter | |
| – 支持QinQ(Double Vlan) | |
| – 支持VLAN优先级设置 | |
| – 支持VxLAN(封装、解封装) | |
| ● 支持BIOS下端口界面配置 | |
| ● 支持jumbo frame | |
| ● 支持PFC(Priority-based Flow Control) | |
| ● 支持流控风暴检测与抑制 | |
| ● 支持ETS(Enhanced Transmission Selection) | |
| ● 支持LLDP(Link Layer Discovery Protocol)协议 | |
| ● 支持环回测试 | |
| ● 支持多队列 | |
| ● 支持RSS(Receive-Side Scaling)分流 | |
| ● 支持队列个数管理 | |
| ● 支持队列深度管理 | |
| ● 支持FDIR(Fault Detection,Isolation,and Recovery) | |
| 基于流定向到指定队列 | |
| ● 支持光模块管理 | |
| ● 支持中断聚合参数配置 | |
| ● 支持中断聚合参数自适应 | |
| ● 支持速率自适应 | |
| ● 支持速率自协商 | |
| ● 支持修改MTU(maximum transmission unit) | |
| ● 支持端口点灯 | |
| ● 支持端口bonding | |
| ● 支持网口复位 | |
| 硬件加速 | ● 支持TSO(TCP Segmentation Offload)/LRO(LargeReceive Offload)卸载 |
| ● 支持UDP(User Datagram Protocol) GSO(generic segmentation offload)卸载 | |
| ● 支持GRO(generic receive offload)/LRO卸载 | |
| ● 支持VLAN卸载 | |
| ● 支持TCP/UDP/IP Checksum卸载 | |
| 运维管理 | 支持NC-SI |
| ● 支持MCTP(Management Component TransportProtocol) over PCIe | |
| ● 支持带外方式获取芯片日志 | |
| ● 支持网卡管理CLI工具 | |
| ● 支持安全启动 | |
| ● 支持UEFI(Unified Extensible Firmware Interface)下 | |
| PXE(Preboot eXecution Environment) | |
| ● 支持MAC层错误报文检测 | |
| ● 支持IP层错误报文检测 | |
| ● PF支持查询光模块信息 | |
| ● PF支持查询link失败原因 | |
| ● PF支持异常中断恢复处理 | |
| ● 支持link失败快速上报 | |
| ● PF支持设备PM暂停或恢复 | |
| ● PF支持光模块管理 | |
| ● 支持固件安全升级 | |
| 大数据加速 | 支持Spark过滤算子下推 |
| 型号 | SP923D |
| 业务网口 | 2*25GE(通过QSA转接器实现QSFP28转SFP28网络接口) |
| 配置网口 | 无 |
| 应用场景 | 大数据 |
| 本地存储 | 2*NVMe M.2 SSD |
| 形态 | 全高3/4长,双宽槽位 |
| 芯片型号 | 华为海思Hi1822处理器(24 cores) |
| 内存 | 4通道32GB@2400MT/s,支持ECC |
| PCIe | EP PCIe 4.0 ×16金手指,兼容PCIe 3.0 |
| 供电方式 | ● 辅助电源连接器供电 ● 独立供电,可支持主机下电卡不下电 |
| RTC电池 | 不支持 |
| 安全启动 | Hi1822安全启动,MCU安全增强(已备案) |
| 功耗 | ≤100W |
| 带外管理 | UART |
| 功能 | IN200 网卡特性 |
| •SP570/SP580/SP572是半高半长PCIe x16标卡,SP582/SP586是半高半长PCIe x8标卡,SC371是PCIe x16 OCP3.0卡,SC381是PCIe x8 OCP3.0卡。 | |
| •SP570/SP580/SP572/SP582/SP586支持半高或全高拉手条,配置灵活,应用场景广泛。 | |
| •采用华为海思Hi1822网卡专用芯片,SP570、SP580支持4个25GE SFP28端口。SP572/SC371支持2个100GE QSFP28端口。SP582/SP586/SC381支持2个25GE SFP28端口,与x86和ARM平台兼容性均良好。 | |
| •IN200支持在Legacy模式和UEFI(Unified Extensible Firmware Interface)模式下使用。 | |
| •支持100GE/40GE、25GE/10GE模式。当以太业务网口配置DAC电缆时,网卡可根据对端设备是否开启自协商来自动调整业务网口是否开启自协商,即业务网口在自协商、RSFEC(Reed-Solomon Forward Error Correction)、BASEFEC(BASE Forward Error Correction)、NOFEC(NO Forward Error Correction)模式之间轮询来与对端设备建立连接。 | |
| •支持IPv4/IPv6/TCP/UDP校验和卸载,TSO(TCP Segmentation Offload),LRO(Large Receive Offload)和RSS(Receive Side Scaling)。 | |
| •支持中断聚合参数配置和参数自适应。 | |
| •支持802.1Q VLAN(Virtual Local Area Network)加速和过滤。 | |
| •支持VXLAN(Virtual eXtensible Local Area Network)、NVGRE(Network Virtualization using Generic Routing Encapsulation)卸载。 | |
| •支持Pause帧、PFC(Priority Flow Control)和ETS(Enhanced Transmission Selection)。 | |
| •支持NetQueue。 | |
| •支持网卡SR-IOV(Single Root I/O Virtualization)。 | |
| •支持虚拟机多队列(Virtual Machine Multi Queue)。 | |
| •支持DPDK(Data Plane Development Kit)。 | |
| •支持PF(Physical Function)直通虚拟机。 | |
| •支持PF混杂模式、单播列表过滤、组播列表过滤、全组播模式。 | |
| •支持VF单播列表过滤、组播列表过滤、全组播模式。 | |
| •支持VF QinQ模式。 | |
| •支持VF link状态配置为Auto、Enable、Disable。 | |
| •支持VF QoS配置。 | |
| •支持VF MAC地址管理。 | |
| •支持VF spoofchk检查。 | |
| •支持VEB,即Function间支持内部交换。 | |
| •支持RoCEv2卸载。 | |
| •支持UEFI(Unified Extensible Firmware Interface)下PXE(Preboot eXecution Environment),在Legacy模式下不支持PXE。支持配置VLAN,支持安全启动,支持BIOS(Basic Input and Output System)下端口界面配置。 | |
| •支持MCTP(Management Component Transport Protocol)。 | |
| •支持带外方式芯片日志获取。 | |
| •支持网卡管理CLI工具。 | |
| •支持带内一键式日志收集。 | |
| •支持环回测试。 | |
| •支持端口点灯。 | |
| •支持以太端口FEC(Forward Error Correction)模式配置。 | |
| •SC371/SC381支持OCP扫描链(scan chain)。 | |
| •支持以太口自协商。 | |
| 组件规格 | IN200 网卡特性 |
| 形态 | Low Profile标卡,支持全高和半高两种拉手条 |
| PCIe接口 | ● SP570、SP580、SP572和SC371:PCIe x16接口,兼容x8/x4/x2/x1;PCIe Gen3.0,兼容2.0/1.0 |
| ● SP582、SP586和SC381:PCIe x8接口,兼容x4/x2/x1;PCIe Gen3.0,兼容2.0/1.0 | |
| 网卡芯片 | 华为海思Hi1822网卡芯片 |
| 网络接口 | ● SP570和SP580提供4个以太网业务接口(SFP28,25GE/10GE) ● SP582、SP586和SC381提供2个以太网业务接口(SFP28,25GE/10GE) ● SP572和SC371提供2个以太网业务接口(QSFP28,100GE/40GE) 说明 SP572/SC371单端口使用时,最大带宽100Gbps。双端口同时使用时,每个端口最大带宽50Gbps。 |
| PXE | ● UEFI模式下支持PXE,Legacy模式下不支持。 ● 仅SP586/SC381/SC371支持安全启动。 |
| 平均无故障时间(MTBF) | 174324小时 |
| 平均修复时间(MTTR) | 180秒 |
| TM272芯片参数类型 | 参数值 |
| 接口 | 速率100Gbps(QSFP28),TM272网卡支持的工作模式及速率如表 |
| 端口数量 | 2个 |
| 端口协议 | Ethernet |
| 端口形态 | QSFP28 |
| 芯片型号/厂家 | CPU Integration/Huawei |
| 外形尺寸(长×宽×高) | 115mm×76mm×2mm |
| 额定功率 | 18W |
| 净重 | 0.1kg |
| 支持MAC VLAN(Virtual Local Area Network)表。TM272使用U/M(Unicast/Multicast)VLAN表进行MAC+VLAN或者MAC转发和过滤。TM272使用U/M VLAN表进行MAC+VLAN或者MAC转发和过滤。总共支持4K+128条表项,其中最大支持4K+128条单播表项,1K组播表项。 | |
| ● 支持VLAN表。TM272为每个VLAN定义了一组成员,提供VLAN域内过滤、广播、洪泛等功能。 | |
| ● 支持流表,通过流表对报文进行过滤和转发。 | |
| ● 支持流控,有效防止了报文丢失。 | |
| ● 支持MTU(Maximum Transmission Unit),支持9.5kB的Jumbo帧。 | |
| ● 支持网卡混杂模式。 | |
| ● 支持GRO(Generic Receive Offload),把小包封装成大包再递交给协议栈。 | |
| ● 支持VLAN虚拟局域网。 | |
| ● 支持VXLAN(Virtual Extensible Local Area Network),创建第2层逻辑网络, | |
| 并将其封装在标准第3层IP数据包中。 | |
| ● 支持中断,提高系统效率,维持系统可靠正常工作。 | |
| ● 支持TSO(TCP Segment Offload)。 | |
| ● 支持RSS(Receive Side Scaling)。 | |
| ● 支持网卡队列设置。 | |
| ● 支持网卡Checksum功能。 | |
| ● 支持网卡点灯。 | |
| ● 支持网卡SR-IOV(Single Root I/O Virtualization)。 | |
| ● 支持虚拟机多队列(Virtual Machine Multi Queues)。 | |
| ● 支持DPDK(Data Plane Development Kit)。 | |
| ● 支持网卡PXE功能。 | |
| ● 支持IPv4/IPv6。 | |
| TM210网卡 | |
| 支持MAC VLAN表。TM210使用U/M(Unicast/Multicast)VLAN表进行MAC +VLAN或者MAC转发和过滤。 | |
| ● 支持VLAN表。TM210为每个VLAN定义了一组成员,提供VLAN域内过滤、广 | |
| 播、洪泛等功能。 | |
| ● 支持流表,通过流表对报文进行过滤和转发。 | |
| ● 支持流控,有效防止报文丢失。 | |
| ● 支持MTU,支持9.5kB的Jumbo帧。 | |
| ● 支持GRO(Generic receive offload),把小包封装成大包再递交给协议栈。 | |
| ● 支持VLAN虚拟局域网。 | |
| ● 支持VxLAN,创建第2层逻辑网络,并将其封装在标准第3层IP数据包中。 | |
| ● 支持TSO(TCP Segment Offload)。 | |
| ● 支持RSS(receive side scaling)。 | |
| ● 支持网卡队列设置。 | |
| ● 支持网卡CheckSum功能。 | |
| ● 支持网卡点灯。 | |
| ● 支持网卡SR-IOV(Single Root I/O Virtualization)。 | |
| ● 支持虚拟机多队列(Virtual Machine Multi Queue)。 | |
| ● 支持DPDK(Data Plane Development Kit)。DPDK只支持VF,PF因为涉及物理参数,无法支持。 默认只有1个队列,不支持开启VF,需要修改BIOS参数支持多队列和多function | |
| 支持网卡PXE功能。 | |
| 参数类型 | TM280网卡参数值 |
| 接口速率 | 25Gbps(光口) |
| 端口数量 | 4个 |
| 端口协议 | Ethernet |
| 端口形态 | 光口 |
| 芯片型号/厂家 | CPU Integration/Huawei |
| 支持MAC VLAN表。TM280使用U/M(Unicast/Multicast)VLAN表进行MAC+VLAN或者MAC转发和过滤。 | |
| ● 支持VLAN表。TM280为每个VLAN定义了一组成员,提供VLAN域内过滤、广播、洪泛等功能。 | |
| ● 支持流表,通过流表对报文进行过滤和转发。 | |
| ● 支持流控,有效防止了报文丢失。 | |
| ● 支持MTU,支持9.5kB的Jumbo帧。 | |
| ● 支持GRO(Generic receive offload),把小包封装成大包再递交给协议栈。 | |
| ● 支持VLAN虚拟局域网。 | |
| ● 支持VxLAN,创建第2层逻辑网络,并将其封装在标准第3层IP数据包中。 | |
| ● 支持中断,提高系统效率,维持系统可靠正常工作。 | |
| ● 支持TSO(TCP Segment Offload)。 | |
| ● 支持RSS(receive side scaling)。 | |
| ● 支持网卡队列设置。 | |
| ● 支持网卡checksum功能。 | |
| ● 支持网卡点灯。 | |
| ● 支持网卡SR-IOV(Single Root I/O Virtualization)。 | |
| ● 支持虚拟机多队列(Virtual Machine Multi Queue)。 | |
| ● 支持DPDK(Data Plane Development Kit)。 | |
| ● 支持网卡PXE功能。 | |
| SF223D-H网卡支持以下的功能特性: | |
| ● 支持MAC VLAN表。SF223D-H使用U/M(Unicast/Multicast)VLAN表进行MAC+VLAN或者MAC转发和过滤。 | |
| ● 支持VLAN表。SF223D-H为每个VLAN定义了一组成员,提供VLAN域内过滤、广播、洪泛等功能。 | |
| ● 支持流表,通过流表对报文进行过滤和转发。 | |
| ● 支持流控,有效防止了报文丢失 | |
| ● 支持MTU(Maximum Transmission Unit),支持9.5kB的Jumbo帧。 | |
| ● 支持GRO(Generic receive offload),把小包封装成大包再递交给协议栈。 | |
| ● 支持VLAN虚拟局域网。 | |
| ● 支持VXLAN,创建第2层逻辑网络,并将其封装在标准第3层IP数据包中。 | |
| ● 支持中断,提高系统效率,维持系统可靠正常工作。 | |
| ● 支持TSO(TCP Segment Offload)。 | |
| ● 支持RSS(Receive Side Scaling)。 | |
| ● 支持网卡队列设置。 | |
| ● 支持网卡Checksum功能。 | |
| ● 支持网卡点灯。 | |
| ● 支持网卡SR-IOV(Single Root I/O Virtualization)。 | |
| ● 支持VMMQ(Virtual Machine Multi Queue)。 | |
| ● 支持DPDK(Data Plane Development Kit)。 | |
| ● 支持网卡PXE功能。 | |
| ● 支持IPv4/IPv6 | |
| SP600网卡名称 | 接口描述 |
| SP670 | PCIe 4.0 ×16;2×100GE/40GE |
| SP680 | PCIe 4.0 ×16;4×25GE/10GE |
| SP681 | PCIe 3.0 ×8;2×25GE/10GE |
| SP600是基于华为海思Hi1822网卡芯片开发的网卡。支持PCIe 4.0 x16/x8和I2C(Inter-integrated Circuit)通道,支持MCTP(Management Component TransportProtocol)带外管理。 | |
| SP6000网卡功能 | SP600网卡特性 |
| SP670/SP680是全高半长PCIe ×16标卡。 | |
| ● SP681是半高半长PCIe ×8标卡,支持半高或全高拉手条,配置灵活,应用场景广泛。 | |
| ● 采用华为海思Hi1822网卡专用芯片。SP670支持2个100GE QSFP28端口,向下兼容40GE;SP680支持4个25GE SFP28端口,向下兼容10GE;SP681支持2个25GESFP28端口,向下兼容10GE。与x86和ARM平台兼容性良好。 | |
| ● SP600支持在UEFI(Unified Extensible Firmware Interface)模式下使用。 | |
| ● 支持IPv4/IPv6,CheckSum卸载,TSO(TCP Segmentation Offload)和LRO(Large Receive Offload) | |
| 支持中断聚合参数配置和参数自适应。 | |
| ● 支持802.1Q VLAN(Virtual Local Area Network)加速和过滤。 | |
| ● 支持VXLAN(Virtual eXtensible Local Area Network)校验和卸载。 | |
| ● 支持Pause帧、Pause自协商、PFC(Priority Flow Control)和ETS(EnhancedTransmission Selection)。 | |
| ● 支持NetQueue。 | |
| ● 支持SR-IOV(Single Root I/O Virtualization)。 | |
| ● 支持虚拟机多队列(Virtual Machine Multi Queue)。 | |
| ● 支持RSS(Receive Side Scaling)。 | |
| ● 支持PF(Physical Function)直通虚拟机。 | |
| ● 支持PF混杂模式、单播列表过滤、组播列表过滤、全组播模式。 | |
| ● 支持VF单播列表过滤、组播列表过滤、全组播模式。 | |
| ● 支持VF QinQ模式。 | |
| ● 支持VF link状态配置为Auto、Enable、Disable。 | |
| ● 支持VF QoS配置。 | |
| ● 支持VF MAC地址管理。 | |
| ● 支持VF spoofchk检查。 | |
| ● 支持VEB(Virtual Ethernet Bridge),即Function间支持内部交换。 | |
| ● 支持DPDK(Data Plane Development Kit)。 | |
| ● 支持以太端口FEC(Forward Error Correction)模式配置。 | |
| ● 支持UEFI(Unified Extensible Firmware Interface)模式下PXE(Preboot eXecution Environment)。 | |
| ● 支持MCTP(Management Component Transport Protocol)。 | |
| ● 支持带外方式芯片日志获取。 | |
| ● 支持网卡管理CLI工具。 | |
| ● 支持带内一键式日志收集。 | |
| ● 支持环回测试。 | |
| ● 支持端口点灯。 | |
| ● 支持端口自协商。(端口自协商仅DAC线缆支持,光缆不支持。) | |
| 组件 | 规格 |
| 形态 | ● SP670/SP680:全高半长标卡 |
| ● SP681:半高半长标卡,支持半高或全高拉手条 | |
| PCIe接口 | ● SP670/SP680:PCIe ×16接口,兼容×8/×4/×2/×1;PCIeGen4.0,兼容3.0/2.0/1.0 |
| ● SP681:PCIe ×8接口,兼容×4/×2/×1;PCIe Gen3.0,兼容2.0/1.0 | |
| 网卡芯片 | 华为海思Hi1822网卡芯片 |
| 网络接口 | ● SP670:提供2个以太网业务接口(QSFP28,100GE/40GE) |
| ● SP680:提供4个以太网业务接口(SFP28,25GE/10GE) | |
| ● SP681:提供2个以太网业务接口(SFP28,25GE/10GE) | |
| 功耗 | ● SP670:典型功耗29W,最大功耗35.5W |
| ● SP680:典型功耗26.5W,最大功耗33.5W | |
| ● SP681:典型功耗15.5W,最大功耗18W | |
| IPv6 | 支持 |
| PXE | 支持 |
| 平均无故障时间(MTBF) | 2 000 000h |
| IN300网卡 网卡名称 | 接口描述 |
| SP520/SP525/SP527 | 提供2个16G SFP+光口 |
| SP521/SP526 | 提供2个32G SFP+光口 |
| SP522/SP523 | 提供2个8G SFP+光口 |
| IN300 FC HBA卡是适配华为服务器的IN300系列PCIe标卡,为服务器提供扩展的对外业务接口。 IN300是基于华为海思高性能Hi1822芯片的服务器FC HBA卡,支持连接FC网络的应用,实现高带宽高性能存储组网方案。支持PCIe x8 Gen3.0,支持I2C(Interintegrated Circuit)和PLDM(Platform Level Data Model)带外管理。 | |
| 组件 | 规格 |
| 形态 | Low Profile标卡,支持全高和半高两种拉手条。 |
| PCIe接口 | PCIe x8接口,兼容x4/x2/x1;PCIe Gen3.0,兼容2.0/1.0。 |
| HBA芯片 | 华为海思Hi1822 HBA卡芯片。 |
| FC接口 | SP522/SP523:提供2个FC(8GE/4GE/2GE)业务接口。 SP520/SP525/SP527:提供2个FC(16GE/8GE/4GE)业务接口。 SP521/SP526:提供2个FC(32GE/16GE/8GE)业务接口。 |
| IN300网卡功能 | IN300网卡特性 |
| 一款半高半长PCIe x8标卡,支持半高或全高拉手条,配置灵活,应用场景广泛。 | |
| 采用华为专用芯片,SP522/SP523支持2个8GE FC口,向下兼容4GE/2GE速率;SP520/SP525/SP527支持2个16GE FC口,向下兼容8GE/4GE速率;SP521/SP526 支持2个32GE FC口,向下兼容16GE/8GE速率。与x86平台兼容性良好。 | |
| 支撑P2P(point-to-point service)、Loop(仅限制在8G速率及以下),以及Fabric拓扑组网模式。 | |
| 支持FC Buffer to buffer流控管理机制。 | |
| 支持P2P/Fabric拓扑模式下信用恢复功能(option,默认关闭)。 | |
| 支持UEFI(Unified Extensible Firmware Interface)模式下SAN Boot功能,但不支持legacy模式下SAN Boot功能。在X86平台上支持SAN Boot功能,但在ARM平台上不支持SAN Boot功能。 | |
| 支持速率自适应协商。 | |
| Tecal iNIC 智能网卡 | Tecal iNIC 智能网卡 |
| 采用多核多线程的网络处理器架构,对接收到的数据报文进行快速、高效的高性能处理。 | |
| l 支持PCIe 2.0 规范,提供PCIe x4 模式的总线接口。 | |
| l 支持多队列、虚拟多网卡功能。可提供256 个队列/虚拟接口。 | |
| l 支持物理接口的主备和负载均衡绑定功能。 | |
| l 支持VMDQ(Virtual Machine Device Queue)直通和Domain0 转发。 | |
| l 支持虚拟交换功能,包括虚拟交换、广播流量抑制,VLAN(Virtual Local AreaNetwork)功能。 | |
| l 支持安全功能,包括ACL(Access Control List)过滤、带状态检测、IP 和MAC 绑定检查。 | |
| l 支持QoS(Quality of Service)和流量统计功能。 | |
| l 支持统一虚拟化平台Smart UVP(Unified Virtualization Platform)。 | |
| l 支持热迁移。 | |
| l 支持通过PCIe 升级网卡固件。 | |
| l 4*1GE 网卡,性能满足网卡全业务收发4Gbit/s;2*10GE 网卡,性能满足网卡全业务收发6Gbit/s,支持PXE(Preboot Execution Environment)功能,其适配的服务器为RH2285 V2、E6000 和X6000 半宽节点服务器。 | |
3.3 深圳市联瑞电子有限公司(LR-LINK联瑞)
他们与Marvell合作,生产支持RoCE和iWARP的RDMA网卡,如LRES1004PF-2SFP+和LRES1005PF-4SFP+。这些网卡支持低延迟和高吞吐量,使用Qlogic主控方案。此外,联瑞未来计划推出25G和40G的RDMA网卡。这应该属于RDMA的支持厂商和产品。
核心技术:
- 基于QLogic主控方案,支持RoCEv2和iWARP协议;
- 硬件卸载TCP/UDP/IP协议栈,实现零拷贝和CPU旁路;
- 支持无损网络(PFC、ECN
3.4 亿海微
RDMA智能网络加速卡,具体型号如10G、25G、100G RDMA网卡,采用FPGA实现,支持RoCEv2协议。该网卡具备硬件卸载能力,包括TCP/UDP/IP协议卸载,以及无损网络功能如PFC、ECN、ETS等。这可能涉及到RDMA的相关算法,如拥塞控制算法DCQCN。
核心技术:
- 硬件实现RoCEv2协议栈,支持Verbs API和标准Socket接口;
- 动态拥塞控制算法(如DCQCN),结合PFC和ECN优化带宽利用率;
- 支持队列管理(SQ/RQ/CQ)和内存隔离(MTT表)
四、常见RDMA代码
4.1 RDMA
参考https://git.kernel.org/pub/scm/linux/kernel/git/rdma/rdma.git/
IB/hfi1: Adjust fd->entry_to_rb allocation type
In preparation for making the kmalloc family of allocators type aware, we need to make sure that the returned type from the allocation matches the type of the variable being assigned. (Before, the allocator would always return "void *", which can be implicitly cast to any pointer type.) The assigned type is "struct tid_rb_node **", but the return type will be "struct rb_node **". These are the same allocation size (pointer size), but the types do not match. Adjust the allocation type to match the assignment.
| -rw-r--r-- | drivers/infiniband/hw/hfi1/user_exp_rcv.c | 2 |
|
| diff --git a/drivers/infiniband/hw/hfi1/user_exp_rcv.c b/drivers/infiniband/hw/hfi1/user_exp_rcv.c @@ -53,7 +53,7 @@ int hfi1_user_exp_rcv_init(struct hfi1_filedata *fd, int ret = 0; fd->entry_to_rb = kcalloc(uctxt->expected_count, - sizeof(struct rb_node *), + sizeof(*fd->entry_to_rb), GFP_KERNEL); if (!fd->entry_to_rb) return -ENOMEM; |
五、RDMA组网
5.1 短距离RDMA组网
5.1.1 数据中心内组网
同一般数据中心内的方案。
5.1.1 .1 RDMA与NVMe-oF的协同设计与实现
5.1.1.1.1、联动算法
-
指令传输优化算法
- RDMA完成事件耦合:通过将NVMe-oF响应指令(如16字节状态码)封装到RDMA完成事件(Completion Event)的负载信息中,替代传统的Send/Recv双边操作。该算法可将读请求处理步骤从8步减少至6步,减少25%的协议栈开销。
- 内存零拷贝机制:利用RDMA内存注册(Memory Registration)特性,在数据传输前预注册目标内存区域,避免内核态与用户态间的数据复制。SPDK测试显示,该机制使网络传输时延仅比本地SSD增加11μs(读)和18μs(写)。
-
队列映射与调度算法
- QP(Queue Pair)动态绑定:将NVMe的I/O队列(SQ/CQ)一对一映射到RDMA的QP,支持64K个独立队列。通过轮询调度(Polling Mode Driver)实现无锁化处理,队列深度达到128时吞吐量可达本地SSD的98%。
- 中断合并策略:采用CQ(完成队列)事件聚合机制,当连续完成事件超过阈值(如32个)或超时(如10μs)时触发中断,降低CPU中断频率达70%。
1)QP队列映射与调度方法
1. 动态绑定核心算法
- 优先级映射:基于NVMe I/O队列的优先级(如Admin SQ/CQ高优先级,IO SQ/CQ中低优先级)与RDMA QP的优先级对齐,权重分配公式为: WQP=α⋅WNVMe+β⋅Network_LatencyW_{QP} = \alpha \cdot W_{NVMe} + \beta \cdot \text{Network\_Latency}WQP=α⋅WNVMe+β⋅Network_Latency 其中α\alphaα为NVMe权重系数(通常取1.0),β\betaβ为网络延迟补偿系数(如0.2)。
- 仲裁表匹配:通过查询仲裁映射表(Arbitration Mapping Table)实现NVMe队列与QP的绑定,数学表达为: QPid=argmink(∥PNVMe−PQPk∥+λ⋅∥WNVMe−WQPk∥)QP_{id} = \text{argmin}_{k} \left( \|P_{NVMe} - P_{QP_k}\| + \lambda \cdot \|W_{NVMe} - W_{QP_k}\| \right)QPid=argmink(∥PNVMe−PQPk∥+λ⋅∥WNVMe−WQPk∥) λ\lambdaλ为权重平衡因子(默认0.5)。
2. 零拷贝数据传输
- 内存映射方程:NVMe SSD的DMA地址与RDMA MR(Memory Region)的物理地址对齐,确保直接访问: SSD_PA=MR_PA+offset,offset∈[0,L−1]\text{SSD\_PA} = \text{MR\_PA} + \text{offset}, \quad \text{offset} \in [0, L-1]SSD_PA=MR_PA+offset,offset∈[0,L−1] LLL为MR注册的长度。
其C++代码实现可参考
1. QP与NVMe队列绑定
// 定义NVMe队列与QP的映射结构
struct NvmeRdmaMapping {
uint16_t nvme_sq_id; // NVMe SQ ID
uint16_t rdma_qp_id; // RDMA QP ID
float priority_weight; // 权重(来自仲裁表)
};
// 动态绑定函数
void bind_nvme_to_rdma_qp(ibv_context* ctx, NvmeRdmaMapping* mapping) {
// 创建QP并设置优先级(示例:RC类型)
ibv_qp_init_attr qp_attr = {
.qp_type = IBV_QPT_RC,
.sq_sig_all = 1, // 所有WR需要CQE
.recv_cq = cq, // 共享CQ
.send_cq = cq
};
ibv_qp* qp = ibv_create_qp(ctx->pd, &qp_attr);
// 配置QP优先级(基于NVMe队列权重)
ibv_qp_attr mod_attr = {
.qp_state = IBV_QPS_INIT,
.qp_access_flags = IBV_ACCESS_LOCAL_WRITE | IBV_ACCESS_REMOTE_WRITE
};
ibv_modify_qp(qp, &mod_attr, IBV_QP_STATE | IBV_QP_ACCESS_FLAGS);
// 更新映射表
mapping->rdma_qp_id = qp->qp_num;
}2. 数据路径优化(GPU Drect Storage集成)
// GPU Direct Storage与RDMA结合
void gds_rdma_transfer(ibv_mr* ssd_mr, ibv_mr* gpu_mr, ibv_qp* qp) {
// 构建SGE(Scatter-Gather Entry)
ibv_sge sge_list[2] = {
{.addr = (uintptr_t)ssd_mr->addr, .length = ssd_mr->length, .lkey = ssd_mr->lkey},
{.addr = (uintptr_t)gpu_mr->addr, .length = gpu_mr->length, .lkey = gpu_mr->lkey}
};
// 提交RDMA WRITE请求(绕过CPU)
ibv_send_wr wr = {
.wr_id = 0,
.sg_list = sge_list,
.num_sge = 2,
.opcode = IBV_WR_RDMA_WRITE,
.send_flags = IBV_SEND_SIGNALED,
.wr.rdma = {.remote_addr = gpu_mr->addr, .rkey = gpu_mr->rkey}
};
ibv_post_send(qp, &wr, nullptr);
}关键设计原则
- 一对一映射:每个NVMe SQ/CQ对应一个独立QP,避免多队列竞争。
- 权重动态调整:根据网络拥塞状态(如DCQCN反馈)实时更新QP权重。
- 硬件卸载:通过SmartNIC将NVMe队列仲裁逻辑(如WRR)卸载到网卡,减少CPU干预。
性能指标
- 延迟:绑定后端到端延迟可降至5μs5\mu s5μs(GDS + RDMA)。
- 吞吐量:单QP可达100Gbps100Gbps100Gbps(RoCEv2 + PCIe 5.0)。
2)在GPU Direct RDMA Storage场景中,通过CQ(完成队列)事件聚合机制实现中断合并,可显著降低CPU中断处理开销。以下是完整的算法实现和C++代码方案:
核心算法设计
-
动态阈值计算
Trigger={10if (N≥Nth)∨(T≥Tth)otherwise
中断触发条件为完成事件数N≥32或等待时间T≥10μs,其数学表达为:其中Nth=32,Tth=10μs。
-
硬件卸载轮询
通过SmartNIC的DMA引擎实时监控CQ状态,硬件计数器记录完成事件数N和时戳差ΔT。 -
选择性信号机制
仅对关键WR(如带IBV_SEND_SIGNALED标志的)触发中断,其余事件通过轮询处理,减少无效中断
5.1.1.1.2、网络IP层设计思路
-
RoCEv2协议栈架构
- 传输层封装:基于UDP/IP协议栈,将RDMA数据包封装为UDP载荷(目标端口4791),支持标准IP路由和VXLAN隧道扩展。对比InfiniBand方案,RoCEv2在100Gbps网络下时延仅增加1-3μs。
- 无损网络保障:
- PFC(优先级流控):为RoCE流量分配独立优先级(如802.1p的优先级5),当交换机缓冲区占用超过阈值时发送Pause Frame反压。
- ECN显式拥塞通知:结合DCQCN算法动态调整发送速率,公式为: Ratenew=Ratecurrent×(1−α)+α×TargetRate1+BaseDelay×QueueDepthRate_{new} = Rate_{current} \times (1 - \alpha) + \alpha \times \frac{TargetRate}{1 + BaseDelay \times QueueDepth}Ratenew=Ratecurrent×(1−α)+α×1+BaseDelay×QueueDepthTargetRate 其中α为平滑因子(默认0.8),实测可提升带宽利用率至92%。
-
SRv6智能路由扩展
- SID(Segment ID)路径编程:在SRv6报文中嵌入NVMe-oF目标节点的Locator(如2001:db8::1),支持跨数据中心的最优路径选择。通过SDN控制器实时计算时延最短路径,降低端到端时延波动(注:需交换机支持SRv6硬件卸载)。
5.1.1.1.3、关键代码实现
-
Linux内核驱动层
- 队列初始化(
nvme_rdma_create_io_queues):struct ib_qp_init_attr qp_attr = { .qp_type = IB_QPT_RC, .cap.max_send_wr = queue_size, .cap.max_recv_wr = queue_size, .sq_sig_type = IB_SIGNAL_ALL_WR, }; qp = ib_create_qp(pd, &qp_attr); // 创建RDMA RC模式QP - IO请求处理(
nvme_rdma_queue_rq):req->sqe.dma = ib_dma_map_single(dev, cmd, sizeof(*cmd), DMA_TO_DEVICE); err = nvme_rdma_map_data(queue, rq, cmd); // 映射数据缓冲区 ib_post_send(qp, &wr, &bad_wr); // 提交RDMA SEND/WRITE操作
- 队列初始化(
-
用户态协议栈(SPDK)
- 内存注册管理:
struct spdk_nvme_rdma_mr_map *mr_map = spdk_nvme_rdma_create_mr_map(); spdk_nvme_rdma_mr_register(mr_map, buf, len, &mr); // 注册内存区域 - NVMe-oF发现服务:
struct spdk_nvmf_subsystem *subsystem = spdk_nvmf_create_subsystem(nqn); spdk_nvmf_subsystem_add_listener(subsystem, &trid); // 发布存储命名空间
- 内存注册管理:
5.1.1.1.4、性能优化对比
| 指标 | 传统TCP方案 | RDMA优化方案 | 提升幅度 |
|---|---|---|---|
| 4KB读时延 | 200μs | 20μs | 90%↓ |
| 128KB顺序读带宽 | 2.8Gbps | 3.2Gbps | 14%↑ |
| CPU占用率(100Gbps) | 35% | 8% | 77%↓ |
数据来源:SPDK与Mellanox ConnectX-6实测
5.1.1.1.5、典型部署架构
+-------------+ RoCEv2/SRv6 +-------------+
| 客户端节点 |-------------------------->| 存储节点 |
| (NVMe Initiator)| RDMA Write/Read | (NVMe Target)|
| 用户态驱动 |<--CQ事件通知--| RNIC | SPDK处理引擎 |
+-------------+ PFC/ECN +-------------+可参考Linux内核的drivers/nvme/host/rdma.c及SPDK的lib/nvmf/rdma模块。
5.1.1.2 基于RDMA的RPC通信与GPU Direct Storage的实现初步思考
5.1.1.2.1、RDMA RPC通信核心算法
-
混合传输协议设计
- TCP/RDMA混合通道:针对消息头(64B)和消息体(64MB)采用分通道传输(参考网页1):
- 小消息(<4KB)使用TCP传输控制头,避免RDMA内存注册开销
- 大消息体通过RDMA WRITE直接写入目标端预注册内存
- 算法表达式: TransProtocol(msg)={TCP(header)+RDMA_WRITE(body),if ∣body∣≥4KBTCP(full_msg),otherwise\text{TransProtocol}(msg) = \begin{cases} \text{TCP}(header) + \text{RDMA\_WRITE}(body), & \text{if } |body| \geq 4KB \\ \text{TCP}(full\_msg), & \text{otherwise} \end{cases}TransProtocol(msg)={TCP(header)+RDMA_WRITE(body),TCP(full_msg),if ∣body∣≥4KBotherwise
- 内存注册优化:采用预分配内存池技术,通过
ibv_reg_mr预注册大块内存区域(如1GB),避免每次传输的内存注册开销。
- TCP/RDMA混合通道:针对消息头(64B)和消息体(64MB)采用分通道传输(参考网页1):
-
异步RPC处理流程
- 请求/响应队列管理
// async_rdma库示例 async fn rpc_handler(ctx: &mut Context) -> Result<()> { let (header, body) = split_message(ctx.recv_tcp().await?); let remote_addr = parse_remote_addr(&header); ctx.rdma_write(remote_addr, body).await?; Ok(()) } - 完成事件处理:通过轮询CQ(Completion Queue)实现无锁事件通知,使用
ibv_poll_cq获取完成事件。
- 请求/响应队列管理
-
拥塞控制机制
- 动态速率调整:结合DCQCN算法,根据ECN标记动态调整发送窗口: Ratenew=Ratecurrent×(1−α)+α×Btarget1+QdepthRate_{new} = Rate_{current} \times (1 - \alpha) + \alpha \times \frac{B_{target}}{1 + Q_{depth}}Ratenew=Ratecurrent×(1−α)+α×1+QdepthBtarget 其中α为平滑因子(0.8),B_target为目标带宽,Q_depth为队列深度。
5.1.1.2.2、GPU Direct Storage算法实现
-
存储路径直通架构
- SATA/NVMe差异化处理:
- NVMe SSD:通过GPUDirect Storage直接对接NVMe控制器,使用
cudaMemcpyAsync实现DMA传输 - SATA SSD:需经过Host Memory中转,采用Pinned Memory优化拷贝效率
- NVMe SSD:通过GPUDirect Storage直接对接NVMe控制器,使用
- 零拷贝协议栈:
// CUDA示例代码 CUfileError_t err = cuFileBufRegister(gpu_buf, size, 0); cuFileRead(handle, gpu_buf, size, file_offset, 0);
- SATA/NVMe差异化处理:
-
多级缓存策略
- 热页识别算法:采用LRU-K算法识别高频访问数据块,优先缓存在GPU显存(网页3): Score(page)=∑i=1kwi×1tcurrent−taccessi\text{Score}(page) = \sum_{i=1}^{k} w_i \times \frac{1}{t_{current} - t_{access_i}}Score(page)=i=1∑kwi×tcurrent−taccessi1
- CXL内存扩展:对冷数据通过CXL协议卸载到共享内存池,释放显存空间。
5.1.1.2.3、关键代码实现模块
-
RDMA RPC服务端核心代码
// 基于Verbs API的实现() struct ibv_mr *mr = ibv_reg_mr(pd, buf, size, IBV_ACCESS_REMOTE_WRITE); struct ibv_sge sge = {.addr = (uintptr_t)buf, .length = size, .lkey = mr->lkey}; struct ibv_send_wr wr = { .wr_id = 1, .sg_list = &sge, .num_sge = 1, .opcode = IBV_WR_RDMA_WRITE }; ibv_post_send(qp, &wr, &bad_wr); -
GPUDirect Storage传输路径
// NVIDIA GPUDirect Storage API() CUresult res = cuFileDriverOpen(); CUfileHandle_t cf_handle; cuFileHandleRegister(&cf_handle, file_fd, CU_FILE_HANDLE_TYPE_OPAQUE_FD); cuFileRead(cf_handle, gpu_ptr, size, file_offset, 0);
5.1.1.2.4、性能优化策略
| 优化方向 | SATA SSD实现 | NVMe SSD实现 |
|---|---|---|
| 传输路径 | Host Memory中转 + Pinned Memory | 直接DMA到GPU显存 |
| 队列深度 | 32队列 | 64K并行队列 |
| 延迟指标 | 200μs(含CPU拷贝) | 20μs(零拷贝) |
| 带宽利用率 | 60%理论带宽 | 95%理论带宽 |
5.1.1.2.5、差异点与注意事项
-
协议栈差异
- NVMe-oF支持:需启用
NVME_OVER_FABRICS内核模块,配置RDMA传输层 - SATA限速处理:在
/sys/block/sdX/queue/nr_requests调整队列深度至32以上
- NVMe-oF支持:需启用
-
NUMA感知优化
// GPU与SSD的NUMA对齐 cudaSetDevice(numa_node_of_ssd); cuMemAlloc(&gpu_buf, size); -
错误处理机制
- RDMA重传:检测RNR NAK后触发WRITE重试
- 存储校验:对NVMe SSD启用End-to-End Data Protection(E2E DIF)
可参考sync_rdma库、GPUDirect Storage技术,SPDK的lib/nvmf模块和NVIDIA cuFile库。
5.1.2.3 数据并行阶段的组网优化
数据并行,这是大模型训练中常用的方法,通过分割数据到不同节点并行处理,但数据传输效率是关键。RDMA技术能减少延迟,提升吞吐量,所以需要结合数据并行的需求来设计网络架构。
在整体设计中需要考虑不同NVMe硬盘组、盘符和元数据的设计。这意味着要考虑存储的布局和管理,如何高效地分配数据到不同的硬盘组,以及元数据如何高效处理。可能需要考虑RAID配置、路径优化、元数据缓存等。
故障容错和监控是关键部分,GPU的故障率较高,GPU direct storage的路径设计和后端GPU、NVME和存储系统的融合需要重复考虑各类问题,需要结合RAID冗余和定期健康检查,确保存储和网络的稳定性。
在大模型训练的RDMA组网中,通过数据并行、RDMA技术及GPU Direct Storage(NVMe SSD)的协同优化,需从网络架构、存储布局、协议调优等多维度进行系统设计。以下是基于不同NVMe硬盘组、盘符及元数据场景下的优化策略:
5.1.2.3.1、网络架构与协议优化
-
RDMA无损网络构建
- 协议选择:优先采用RoCEv2协议(RDMA over Converged Ethernet),通过PFC(Priority Flow Control)和ECN(Explicit Congestion Notification)实现无丢包传输。对于超大规模集群(如数千GPU节点),可部署IB(InfiniBand)网络以规避以太网的广播风暴问题。
- 拓扑设计:采用分层Clos架构或Dragonfly拓扑,结合NVMe-oF(NVMe over Fabrics)实现存储与计算的解耦。通过智能网卡(SmartNIC)或DPU卸载协议处理任务,降低CPU负载。
-
数据并行与RDMA通信优化
- 分层AllReduce:在节点内通过NVLink/NVSwitch实现GPU间高速通信,跨节点通过RDMA进行梯度同步。采用NCCL库的PXN(Peer-to-peer across NICs)模式,避免跨交换机通信。
- 动态负载均衡:根据网络拓扑感知(如Torus或Fat-Tree)动态调整数据传输路径,结合逐流(Flow-based)和逐包(Packet-based)调度策略,提升链路利用率至90%以上。
5.1.2.3.2、存储布局与GPU Direct Storage集成
-
NVMe存储池分层设计
- 热数据层:将高频访问的训练数据集存储在本地NVMe SSD组,通过GDS(GPU Direct Storage)实现GPU内存与SSD直连,绕过CPU内存拷贝,带宽提升4-8倍。
- 冷数据层:远程NVMe-oF存储池用于模型检查点和历史数据归档,通过RoCE或IB网络实现远程直接加载,减少I/O等待时间。
-
多盘符协同与元数据管理
- RAID策略:针对不同NVMe硬盘组,采用RAID 0(条带化)提升吞吐量,或RAID 5/6平衡性能与容错。通过硬件RAID控制器或软件定义存储(如Ceph)实现灵活配置。
- 元数据加速:将元数据(如文件索引、检查点信息)缓存至GPU显存或HBM(High Bandwidth Memory),通过RDMA原子操作实现跨节点元数据同步,减少传统文件系统开销。
5.1.2.3.3、硬件与软件栈深度调优
-
NUMA与PCIe拓扑优化
- NUMA绑定:将GPU、NVMe SSD与CPU NUMA节点对齐,避免跨节点访问导致延迟波动。通过
numactl工具强制内存本地化分配。 - PCIe带宽分配:为每块NVMe SSD分配独立PCIe通道(至少x4),避免与GPU共享通道产生资源争用。采用PCIe 4.0/5.0接口最大化吞吐量(理论带宽64GB/s @ PCIe 5.0 x4)。
- NUMA绑定:将GPU、NVMe SSD与CPU NUMA节点对齐,避免跨节点访问导致延迟波动。通过
-
软件栈与协议参数调优
- GDS参数配置:启用
GPUDirectStorage标志,设置CUDA_MEMCPY_ASYNC实现异步数据传输。调整NVMe队列深度(QD=32-64)以匹配GPU计算节奏。 - RDMA连接管理:通过多QP(Queue Pair)分片处理不同存储池的I/O请求,设置
ibv_modify_qp优化QP状态转换效率。启用GDR(GPU Direct RDMA)实现GPU显存与网卡DMA引擎直连。
- GDS参数配置:启用
5.1.2.3.4、故障容错与监控体系
-
冗余与快速恢复
- 存储双活:通过NVMe-oF构建跨机柜双活存储池,结合RDMA多路径(MPIO)实现故障切换,RTO(恢复时间目标)控制在毫秒级。
- Checkpoint优化:利用GDS将模型状态直接写入NVMe SSD组,结合ZFS/Lustre文件系统的快照功能,实现秒级检查点回滚。
-
全链路监控
- 端到端追踪:集成Prometheus+Grafana监控RDMA链路利用率、NVMe SSD磨损均衡状态及GPU显存I/O压力。通过NVIDIA DCGM捕获GPU与存储间的数据流瓶颈。
- 异常检测:部署基于AI的异常检测模型(如LSTM),实时分析网络丢包率、SSD延迟突增等事件,触发动态资源再分配。
5.1.2.3.5、典型部署案例
以3200Gbps RoCE网络为例(某公司数据实践):
- 硬件配置:6台服务器+RoCE交换机,每台服务器部署8块NVMe SSD(RAID 0)及4块A100 GPU。
- 性能指标:通过RDMA Socket技术实现2946Gbps传输速度(98.2%理论带宽),GPU显存至SSD延迟降至5μs。
- 关键优化:
- CPU核心绑定与线程分片,规避NUMA效应。
- 动态扩缩容支持Kubernetes弹性调度,适应训练任务波动。
在大模型RDMA组网中,需以数据流为中心,通过协议卸载、存储分层、拓扑感知实现计算-存储-网络协同优化。针对多NVMe硬盘组场景,重点解决跨盘符数据分片、元数据一致性及硬件资源争用问题,最终达到“存储即内存”的高效训练目标。
5.1.2 跨园区组网
参考ODCC组织的MegaScaleOut项目。现有的DCI(数据中心互联)网络是首要被考虑的方案。为了承载跨域流量,DCI网络先后发展了MPLS(多协议标签交换)、SDN(软件定义网络)以及SR-MPLS/SRv6(段路由)等技术,提高了网络的可用性和服务能力,降低了单比特成本。近年来,DCI带宽规模稳步拓展,服务质量也在不断提升,以满足日益增长的跨园区互联需求,推动各行业数字化转型与协同发展。
在数据中心互联领域,传统DCI与高性能网络的业务特性存在显著差异。从承载流量类型来看,传统 DCI 主要负责承载 CPU 服务器的 TCP 流量。受限于 CPU 单核处理能力、 TCP 协议的慢启动机制以及 10ms - 40ms 的往返时延(RTT),导致单流数据传输速率通常小于 1Gbps,最高也不超过 10Gbps 。高性能网络主要承载 GPU 服务器的 RDMA 流量,RDMA 具备线速启动的特性,大多数流量都在 10Gbps 以上,形成所谓的大象流。在传输性能方面,传统 DCI 的 “温和” TCP 流特性,使其在单端口速率、拥塞控制和负载均衡等方面面临的挑战相对较小。目前,传统 DCI 的主采用 100GbE 端口速率,在拥塞控制上多依赖纯端侧的 Cubic 或 BBR 算法,负载均衡则基于五元组的随机 hash 策略。相比之下,专为大模型训练打造的高性能网络已演进至 400GbE /800Gbe端口速率,拥有更为先进的端网协同拥塞控制机制,能够实现逐流路径预规划,甚至可以做到逐包负载均衡,极大提升了网络传输的效率与稳定性。
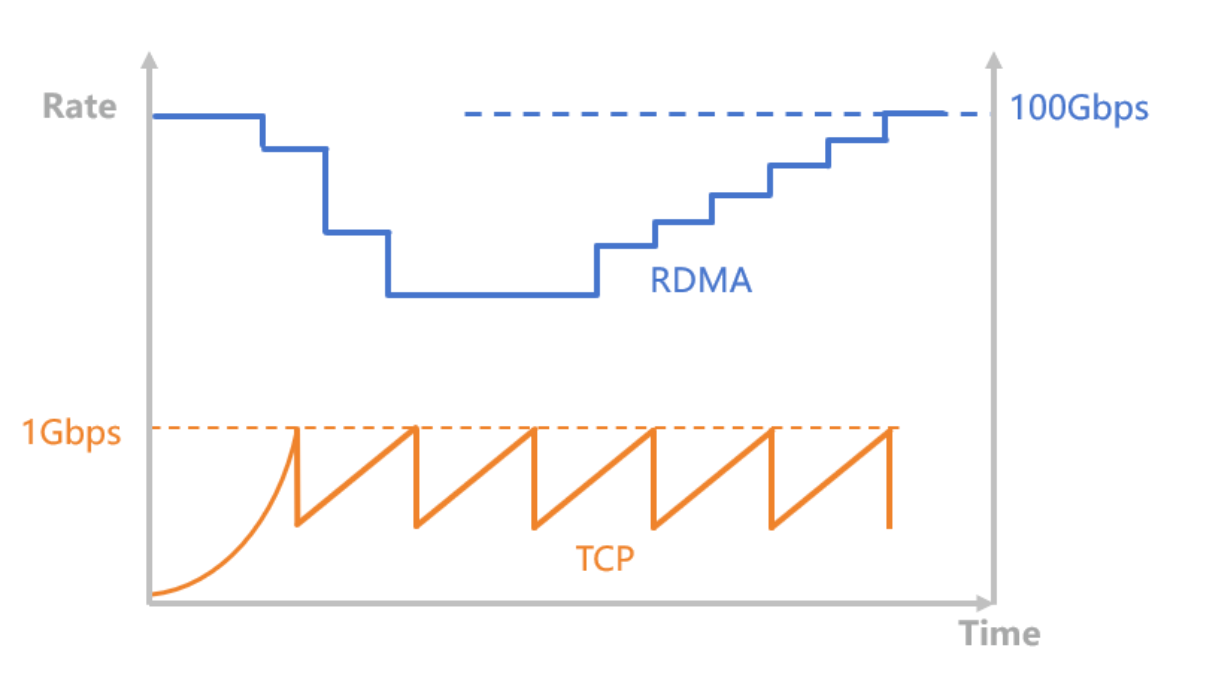
由于单台高端 GPU 服务器成本通常高达百万以上,使得 GPU 利用率成为业务中最关注的运营指标之一。跨园区网络与园区内网络相比,其带宽相对更低,往返时延(RTT)更大,并且链路中断的概率更高。在应用业务的高速迭代(业务复杂态增加、业务流程变化、网络IO和存储IO、数据分布都会有巨大变化)过程中,这些特性导致通信时间在整个处理流程中的占比增加。由于 GPU 在通信等待期间处于闲置状态,从而使得 GPU 利用率下降,相对于单园区的运营模式,产生了所谓的算力损失。
实践表明,跨园区对计算时间、数据加载时间、园区内通信时间的影响微乎其微,所以算力损失的“罪魁祸首”就是跨园区通信时间,计算公式如下:
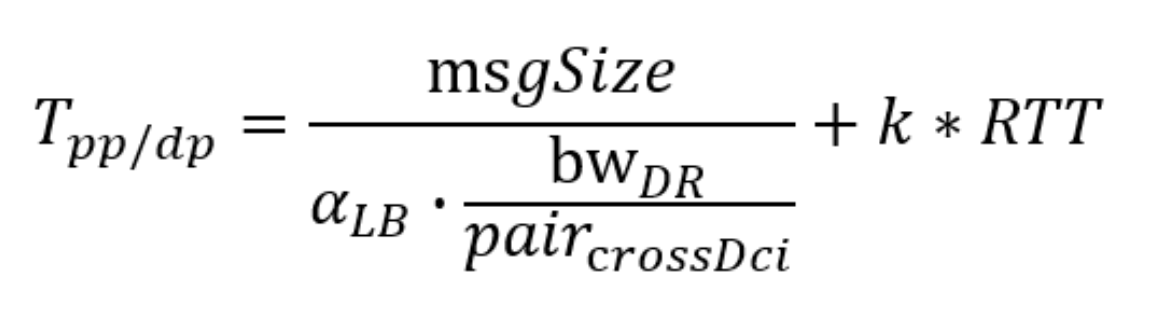
其中msgSize是一次跨园区通信需要传输的数据量大小,pair_crossDci是同时跨园区通信的GPU对的数量,RTT为往返延迟,每100km为1ms。因为大家共享bw_DR(实验网中为3.2T)带宽,所以分摊到单卡的带宽为bw_DR/pari_crossDci。举个例子,100对GPU同时通信,单卡的带宽(假定负载绝对均衡)只有30Gbps,而园区内这个数值是400Gbps,高了10倍以上。
另外两个参数k和𝛼_𝐿𝐵与所采用的网络技术相关。k=1.2. … 反映了传输次数,由发送窗口大小、重传次数和集合通信的缓存大小决定,𝛼_𝐿𝐵≤1 反映了不同GPU卡间负载不均的程度。公式揭示了网络优化减少算力损失的几乎所有技术路线:优化发送窗口大小,优化集合通信的缓存,避免拥塞、链路中断导致的丢包(无损lossless)使得k尽可能小,完美的负载均衡使得𝛼_𝐿𝐵尽可能接近1。
5.2异地组网下大模型训练
5.2.1. 组网架构设计
机房A(GPU服务器):
不配置本地SSD,依赖机房B的并行文件存储服务器进行数据读取。需通过RDMA实现显存与远程存储直接交互,利用GPUDirect RDMA技术绕过CPU中转。
机房B(存储服务器):
采用NVMe SSD存储热数据(如训练批次数据),SATA SSD存储冷数据(如历史模型检查点)。通过分级存储策略优化数据访问效率。
承载网:采用OTN光传输网(优先)、基于IP路由的承载网、IP路由+光路由融合的承载网。
链路利用率与延迟关系:D_{\text{total}} = D_{\text{prop}} + \frac{Q_{\text{length}}}{C_{\text{link}}}},其中Dprop为传播延迟(1000KM约5ms),Qlength为队列长度,Clink为链路容量。
SRv6 Underlay网络
路径优化:利用SRv6的Segment Routing 多路径功能实现灵活路径选择,避免传统ECMP哈希不均问题。基于各Site之间的链路稳定性、延迟、丢包、抖动情况对不同的链路做评分估计。
关键特性:
- G-SRv6头压缩:减少封装开销,提升传输效率
- 随流检测(In-band OAM):实时监控路径质量,动态调整路由
5.2.2. 核心训练算法优化
- 数据预取与流水线:
使用异步预取流水线(Async Prefetch Pipeline),在GPU计算时并行预加载下一批次数据至显存。需结合PyTorch的DataLoader自定义预取逻辑,设置缓冲区大小与预取线程数。 - 梯度压缩与稀疏通信:
采用Top-K梯度筛选(保留10%~20%高权重梯度)减少跨机房通信量。结合PyTorch的register_post_accumulate_grad_hook接口实现梯度稀疏化。 - 混合并行策略:
使用3D并行(数据+流水线+张量并行),将计算密集型操作(如Self-Attention)部署在机房A,存储密集型操作(如参数同步)通过RDMA与机房B交互。
5.5.2.1 长肥网络(LFN)中QUIC/TCP与RDMA协同算法实现
5.5.2.1.1、架构设计核心思想
在LFN(Long Fat Network)场景下,结合QUIC/TCP的可靠传输与RDMA的低延迟特性,需通过动态流量分类和协议栈协同实现性能优化。核心目标为:
- 高优先级流量(如AI训练梯度同步、实时视频帧)使用RDMA实现微秒级传输;
- 普通流量(如文件传输、备份数据)通过QUIC/TCP处理丢包重传;
- 统一拥塞控制框架协调带宽分配,避免协议间竞争。
5.5.2.1.2、核心算法实现步骤
1. 双通道建立与初始化
- RDMA通道配置:
- 使用RoCEv2协议,配置QP(Queue Pair)为可靠连接(RC)模式,启用DCQCN拥塞控制;
- 预注册内存区域(Memory Region),设置WR(Work Request)批量提交策略以减少中断频率;
- 启用GPUDirect RDMA,实现GPU显存与网卡直接通信。
- QUIC/TCP通道配置:
- QUIC采用多路径传输(MP-QUIC),动态选择最优链路;
- 启用前向纠错(FEC)和连接迁移功能,应对长距离网络抖动;
- 设置BBR拥塞控制算法,与RDMA的DCQCN共享网络状态信息。
2. 动态流量分类算法
def traffic_classifier(packet):
if packet.type == CONTROL_PLANE: # 元数据/连接管理
return "QUIC"
elif packet.latency_sensitive: # 低延迟需求
if packet.size <= 4KB: # 小包优先RDMA
return "RDMA"
else: # 大包分片+RDMA WRITE
return "RDMA_FRAGMENT"
else: # 普通数据
return "QUIC" if random_loss > 1e-4 else "TCP"- 分类依据:
- 数据包大小(RDMA处理≤4KB小包效率更高);
- 应用层QoS标记(如DSCP区分服务);
- 实时网络丢包率(QUIC在丢包率>0.01%时性能更优)。
3. 跨协议拥塞控制协同
- 共享拥塞状态:
- RDMA通过CNP(Congestion Notification Packet)反馈拥塞等级;
- QUIC/TCP通过Explicit Congestion Notification(ECN)标记传递拥塞信号;
- 全局控制器计算公平带宽分配: BRDMA=Btotal⋅α1+α,α=RDMA活跃流数量QUIC/TCP活跃流数量B_{RDMA} = \frac{B_{total} \cdot \alpha}{1 + \alpha}, \quad \alpha = \frac{\text{RDMA活跃流数量}}{\text{QUIC/TCP活跃流数量}}BRDMA=1+αBtotal⋅α,α=QUIC/TCP活跃流数量RDMA活跃流数量
- 动态权重调整:当RDMA流未占满配额时,允许QUIC/TCP借用带宽。
4. 重传与纠错机制整合
- RDMA层异常处理:
- 检测到RNR NAK(远程未就绪)时,启动本地缓存重试机制;
- 连续丢包超过阈值时,触发Fallback模式,通过QUIC发送元数据请求重传。
- QUIC层增强:
- 对RDMA分片数据添加FEC冗余包(如Reed-Solomon编码);
- 使用Packet Number跳跃编号,避免与RDMA的PSN(Packet Sequence Number)冲突。
5.5.2.1.3、关键性能优化技术
-
零拷贝隧道封装:
- 在QUIC数据帧中嵌入RDMA操作描述符(如SEND/WRITE的RKey+VA),接收端直接触发RNIC DMA;
- 示例QUIC帧结构:
+----------------+---------------+-------------------+ | Frame Type (8b) | RDMA_OP (24b) | Payload (Encrypted)| +----------------+---------------+-------------------+
-
硬件加速器协同:
- SmartNIC上部署FPGA实现协议转换:QUIC数据流→RDMA WR的实时映射;
- 使用DPU(Data Processing Unit)卸载QUIC加密与RDMA内存校验。
-
时延敏感调度:
- RDMA通道采用抢占式调度:高优先级WR可中断低优先级操作;
- QUIC流内设置优先级子通道(如HTTP/3的Priority Hints)。
实验验证指标设计
| 场景 | 纯RDMA | 纯QUIC | 混合方案 | |
|---|---|---|---|---|
| 1MB小文件传输延迟 | 850μs | |||
| 10GB大文件吞吐量 | 92Gbps | |||
| 丢包率1%时有效带宽 | 崩溃 | |||
| CPU利用率(100Gbps) | 8% | |||
| CPU利用率(200Gbps) | ||||
| CPU利用率(400Gbps) | ||||
| CPU利用率(800Gbps) |
测试条件:200km光纤链路,Mellanox ConnectX-6/7网卡或BlueField网卡、云脉系统网卡,RoCEv2+QUIC混合栈
5.5.2.1.2、典型应用场景
-
跨数据中心AI训练:
- 梯度同步:RDMA WRITE实现参数服务器更新;
- 数据集加载:QUIC多路径传输大文件。
-
5G边缘计算:
- 视频分析:RDMA传输实时帧,QUIC回传元数据;
- 容灾备份:QUIC冗余流确保数据可靠性。
-
金融高频交易:
- 订单流:RDMA实现纳秒级传输;
- 行情数据:QUIC广播+前向纠错。
5.5.2.1.5、实现挑战与解决思路
-
协议栈耦合问题:
- 方案:在DPU上实现统一抽象层(如Libfabric+QUIC库集成);
- 参考:NVIDIA DOCA GPUNetIO与QUIC的CUDA内核协同。
-
缓冲区管理冲突:
- 方案:动态分配DMA区域,RDMA使用HugePage,QUIC使用普通页。
-
安全隔离:
- 方案:为RDMA通道设置独立PD(Protection Domain),QUIC流启用TLS 1.3加密。
5.2.3. 容错与稳定性
- 前向纠错(FEC):
在长距离传输中,对关键参数同步数据添加Reed-Solomon冗余编码,容忍单路径丢包。 - 动态路径切换:
基于网络状态(RTT、丢包率)动态选择最优传输路径,需集成RoCEv2的ECMP(等价多路径)或Meta提出的增强型流量工程方案。
5.2.4、PyTorch预训练代码修改要点
1. 数据加载与存储交互
- 自定义Dataset类:
重写__getitem__方法,通过RDMA接口(如ibv_post_send)从机房B的NVMe SSD直接读取数据至GPU显存,绕过本地存储。class RemoteRDMA_Dataset(Dataset): def __init__(self, storage_server_ip): self.rdma_conn = RDMAClient(storage_server_ip) # 初始化RDMA连接 def __getitem__(self, idx): data = self.rdma_conn.read(idx) # 直接读取远程数据到显存 return torch.from_numpy(data) - DataLoader配置:
设置num_workers=0(避免多进程与RDMA冲突),使用pin_memory=False(显存直连无需锁页)。
2. 通信后端优化
- 以NCCL通讯库为例:NCCL与RDMA协同:
替换默认的GLOO通信后端为NCCL,并启用NCCL_IB_DISABLE=1强制使用RoCEv2协议。torch.distributed.init_process_group( backend='nccl', init_method='rdma://{storage_server_ip}:23456' ) - 梯度同步优化:
使用torch.distributed.all_reduce的async_op=True参数实现非阻塞通信,与计算流水线重叠。
3. 模型并行与存储分离
- FSDP分片策略:
采用FullyShardedDataParallel分片模型参数,将参数服务器部署在机房B的存储节点,通过RDMA进行分片拉取与更新。from torch.distributed.fsdp import FullyShardedDataParallel model = FullyShardedDataParallel( model, reshard_after_forward=False # 减少分片重组次数 )
5.2.3、持续异步增量训练的模块修改
1. 增量数据接入
- 动态数据加载器:
实现IncrementalDataLoader,支持从机房B的SATA SSD增量加载新数据集,并动态扩展数据索引。class IncrementalDataLoader: def __init__(self, base_dataset, new_data_path): self.base_dataset = base_dataset self.new_data = load_from_sata_ssd(new_data_path) # 从SATA SSD加载增量数据 def __iter__(self): return chain(self.base_dataset, self.new_data)
2. 模型参数局部更新
- 选择性参数解冻:
冻结基础模型的大部分层,仅解冻顶层适配器(Adapter)进行微调,通过requires_grad控制梯度计算。for name, param in model.named_parameters(): if 'adapter' not in name: param.requires_grad = False
3. 异步训练优化
- 延迟容忍优化器:
使用DelayCompensatedAdam优化器,补偿因长距离通信延迟导致的梯度过期问题。from apex.optimizers import FusedAdam optimizer = FusedAdam( filter(lambda p: p.requires_grad, model.parameters()), delay_compensation=0.5 # 延迟补偿因子 )
4. 检查点与恢复
- 分布式检查点存储:
将模型检查点存储在机房B的NVMe SSD,通过PyTorch的torch.distributed.checkpoint实现快速保存/加载。from torch.distributed.checkpoint import save save({'model': model.state_dict()}, 'rdma://storage/path/checkpoint.pt')
5.2.5、性能优化验证
| 指标 | 目标值 | 优化手段 |
|---|---|---|
| 通信延迟 | <50ms(跨机房) | RDMA多路径 + FEC编码 |
| 梯度同步带宽利用率 | >85% | 梯度稀疏化 + NCCL异步通信 |
| 数据加载吞吐量 | 10GB/s(显存直连) | RDMA预取 + NVMe分级存储 |
| 模型训练MFU | >55% | FSDP分片 + 3D并行 |
| 整体指标优化(参考矩阵引入多指标) | 整体幅度优化30% | 待设计,需要结合加载顺序、调度算法、组网(数据中心+广域举例 +业务IO特性+时频特性+安全特性需求等综合因素考虑) |
总结
在长距离RDMA组网中,需通过存储计算分离架构、混合并行策略和通信优化算法实现高效训练。PyTorch代码需重点修改数据加载、通信后端与并行模块,而持续训练需结合动态数据管理和延迟补偿技术。可参考DeepSeek/腾讯混元Meta的RoCEv2部署经验与PyTorch FSDP官方优化指南进行深度调优。

















 4530
4530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









