






TF-IDF算法是一种用于信息检索与数据挖掘的常用加权技术。TF的意思是词频(Term - frequency),IDF的意思是逆向文件频率(inverse Document frequency).
TF-IDF是传统的统计算法,用于评估一个词在一个文档集中对于某一个文档的重要程度。它与这个词在当前文档中的词频成正比,与文档集中的其他词频成反比。
首先说一下TF(词频)的计算方法,TF指的是当前文档的词频,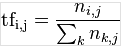 ,在这个公式中,分子表示的是改词在某一文档中出现的次数,分母表示在该文档中所有关键词出现的次数之和。
,在这个公式中,分子表示的是改词在某一文档中出现的次数,分母表示在该文档中所有关键词出现的次数之和。
然后来说下IDF(逆向词频)的计算方法,IDF指的是某个词汇普遍性的度量。 ,这个公式中,log内的部分,分子表示的是文档集中文档的个数,分母表示的是包含当前关键词的文档的个数,对于这个分数取对数,得到的就是,当前词汇的IDF的值。
,这个公式中,log内的部分,分子表示的是文档集中文档的个数,分母表示的是包含当前关键词的文档的个数,对于这个分数取对数,得到的就是,当前词汇的IDF的值。
下面,我来介绍下通过python对TF-IDF算法的设计及实现:
对象1:文章集(属性:文章对象的集合,包含关键字的文章数)
对象1: 文章(属性:关键词对象的集合;关键词出现的总次数;关键词对应对象的字典)
对象2:文章-关键词(属性:关键词名称;关键词在当前文章中出现的次数;TF_IDF)
实现流程:
1、创建文章对象,初始关键字的Map集
2、遍历关键字,每遍历一个关键字,
2.1 关键词出现的总次数加一
2.2 判断文章关键字中是够存在当前关键字,如果存在,找出他,加一,如果不存在,创建一个文章关键字对象,塞到文章的关键字的集中去;
2.3 若果这个关键字是第一次出现,则记录关键字出现的文章数(如果关键字在关键字-文章数 字典中存在,则文章数+1,否则将其加入到关键字-文章数字典中,并赋初始值1)
2.4 遍历完成,文章的关于关键词的Map集装载完成,然后将当前的文章add到文章集的对象中去
3 遍历文章集,计算出关键字对应的TF-IDF,并输出
实现代码:(实现代码以读取一个文件模拟多个文档)
# TF_IDF.py
# -*- coding: utf-8 -*-
import jieba
import math
class DocumentSet():
documentList = []
key_Count = {} #关键词对应的文章数
class Document():
docKeySumCount=0 #文章中所有关键词总次数
docKeySet={} #关键词对象列表
def __init__(self,docid):
self.docid = docid
class DocKey():
docKeyCount = 1 #当前关键词在当前文章中出现的次数
TF_IDF = 0 #当前关键词的TF-IDF值
def __init__(self,word):
self.word = word
f = open("C:/Users/zw/Desktop/key-words.txt", 'r')
line='start'
docList = DocumentSet()
while line:
line = f.readline()
datafile = line.split('\t')
if(datafile.__len__()>=2):
doc = Document(datafile[0])
wordList = list(jieba.cut(datafile[1]))
for i in wordList:
doc.docKeySumCount = doc.docKeySumCount + 1
if i not in doc.docKeySet.keys():
doc.docKeySet[i] = DocKey(i)
else:
doc.docKeySet[i].docKeyCount = doc.docKeySet[i].docKeyCount+1
#记录包含关键词的文章数
if doc.docKeySet[i].docKeyCount <= 1:
if i not in docList.key_Count.keys():
docList.key_Count[i]=1
else:
docList.key_Count[i]=docList.key_Count[i]+1
docList.documentList.append(doc)
f.close()
for d in docList.documentList:
for k in d.docKeySet.keys():
d.docKeySet[k].TF_IDF = d.docKeySet[k].docKeyCount/d.docKeySumCount + math.log(docList.documentList.__len__()/docList.key_Count[k])
print ('文章id :%s 关键字【%s】的TF-IDF值为:%s',d.docid ,k, d.docKeySet[k].TF_IDF)















 430
430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









