






任务目的
- 理解 Shuffle 的概念和作用
- 理解 Map 端 Shuffle 的详细过程
- 理解 Reduce 端 Shuffle 的详细过程
任务清单
- 任务1:Shuffle 简介
- 任务2:Shuffle 主要流程
- 任务3:Map 端的 Shuffle 过程
- 任务4:Reduce 端的 Shuffle 过程
详细任务步骤
任务1:Shuffle 简介
在 Hadoop 中数据从 Map 阶段传递给 Reduce 阶段的过程就叫 Shuffle,Shuffle 机制是整个 MapReduce 框架中最核心的部分。
Shuffle的本义是洗牌、混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好。MapReduce中的Shuffle更像是洗牌的逆过程,把一组无规则的数据尽量转换成一组具有一定规则的数据。
MapReduce计算模型为什么需要 Shuffle 过程?
我们都知道MapReduce计算模型一般包括两个重要的阶段:Map是映射,负责数据的过滤分发;Reduce是规约,负责数据的计算归并。Reduce的数据来源于Map,Map的输出即是Reduce的输入,Reduce需要通过Shuffle来获取数据。
具体来说:就是将 MapTask 输出的处理结果数据,分发给 ReduceTask,并在分发的过程中,对数据按 key 进行了分区和排序。
任务2:Shuffle 主要流程
Shuffle 描述的是数据从 Map 端到 Reduce 端的过程,大致分为排序(sort)、溢写(spill)、合并(merge)、拉取拷贝(Copy)、合并排序(merge sort)这几个过程,大体流程如下: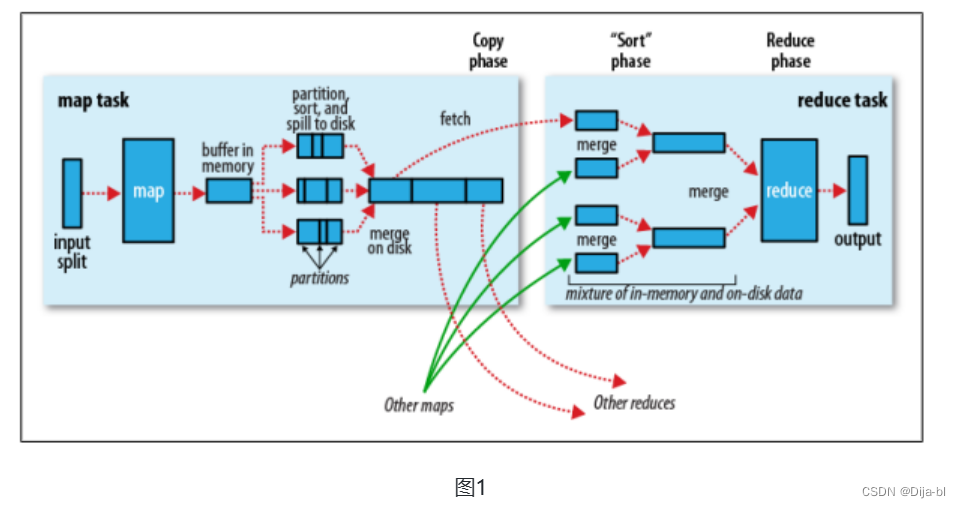
Shuffle 是 MapReduce 处理流程中的一个过程,它的每一个处理步骤是分散在各个 MapTask 和 ReduceTask 节点上完成的,整体来看,分为 3个操作:
- Partition(分区,必要)
- Sort (根据 key 排序,必要)
- Combiner (进行局部 value 的合并,非必要)
任务3:Map 端的 Shuffle 过程
Map 端做了下图所示的操作: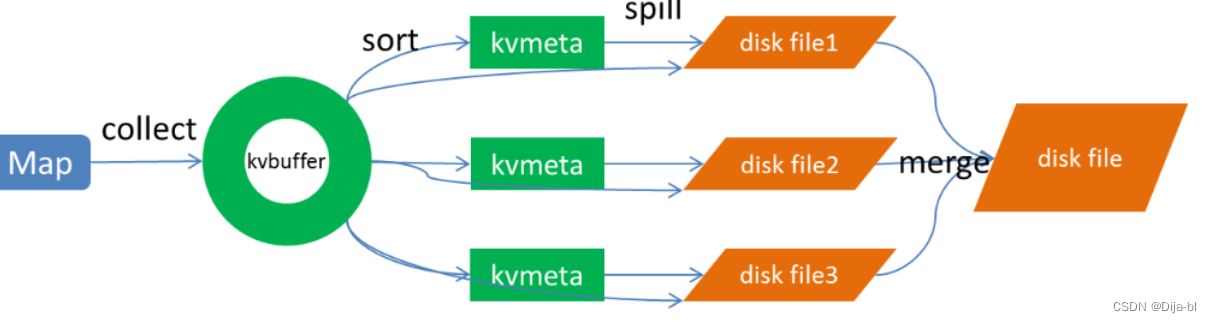
1. Collect (收集)阶段
MapTask 收集我们的 map() 方法输出的 kv 对,放到内存缓冲区Kvbuffer中。每一个 MapTask 都有一个环形内存缓冲区,用于存储任务的输出,默认大小100MB( mapreduce.task.io.sort.mb属性)。
提问:什么是环形缓冲区?
每一个 MapTask 都有一个环形 Buffer,Map 将输出写入到这个环形缓冲区中。环形缓冲区是内存中的一种首尾相连的数据结构,专门用来存储 Key-Value 格式的数据,可以叫做Kvbuffer:
举例来说,下图中总共涉及三个变量:kvstart、kvindex和kvend。kvstart表示当前已写的数据的开始位置,kvindex表示写一个下一个可写的位置,因此,从kvstart到(kvindex-1)这部分数据就是已经写的数据,另外一个线程来Spill的时候,读取的数据就是这一部分。而写线程仍然从kvindex位置开始,并不冲突(如果写得太快而读得太慢,追了一圈后可以通过变量值判断,也无需加锁,只是等待)。
最初往环形缓冲区中添加数据的时候kvend=kvstart,但kvindex递增;当触发Spill的时候,kvend=kvindex,Spill的值涵盖从kvstart到kvend-1区间的数据,kvindex不影响,继续按照进入的数据递增;当进行完Spill的时候,kvindex增加,kvstart移动到kvend处,在Spill这段时间,kvindex可能已经往前移动了,但并不影响数据的读取,因此,kvend实际上一般情况下不变,只有在要读取环形缓冲区中的数据时发生一次改变(即设置kvend=kvindex):
提问:为什么要用环形缓冲区?
使用环形缓冲区,便于写入缓冲区和写出缓冲区同时进行。
提问:为什么不等缓冲区满了再spill?
如果写满了才溢出到磁盘,那么在溢出磁盘的过程中不能写入,写就被阻塞了,但是如果到了一定程度就溢出磁盘,那么缓冲区就一直有剩余空间可以写,这样就可以设计成读写不冲突,提高吞吐量。
2. sort (排序)阶段
当内存中的数据量达到一定的阈值80%,即80MB(可通过 mapreduce.map.sort.spill.percent 配置),一个后台线程就会不断地将数据溢出(spill)到本地磁盘文件中,可能会溢出多个文件;但溢写之前会有一个 sort 操作,这个 sort 操作先把 Kvbuffer 中的数据按照 partition 值和 key 两个关键字来排序,移动的只是索引数据,排序结果是 Kvmeta 中数据按照 partition 为单位聚集在一起,同一 partition 内的按照 key 有序。如果有 Combiner,还要对排序后的数据进行 Combiner。
3. spill(溢写)阶段
当排序完成,便开始把数据刷到磁盘,刷磁盘的过程以分区为单位,一个分区写完,写下一个分区,分区内数据有序,最终实际上会多次溢写,然后生成多个溢出文件。
4. merge(合并)阶段
每次溢写会在磁盘上生成一个溢写文件,如果 Map 的输出结果很大,有多次这样的溢写发生,磁盘上相应的就会有多个溢写文件存在。因为最终的文件只有一个,所以需要将这些溢写文件归并到一起,这个过程就叫做 Merge。Merge 的过程也是相同分区的合并成一个片段(segment),最终所有的 segment 组装成一个最终文件,那么合并过程就完成了。如下图所示:
至此,Map 的操作就已经完成,Reduce 端操作即将登场。
任务4:Reduce 端的 Shuffle 过程
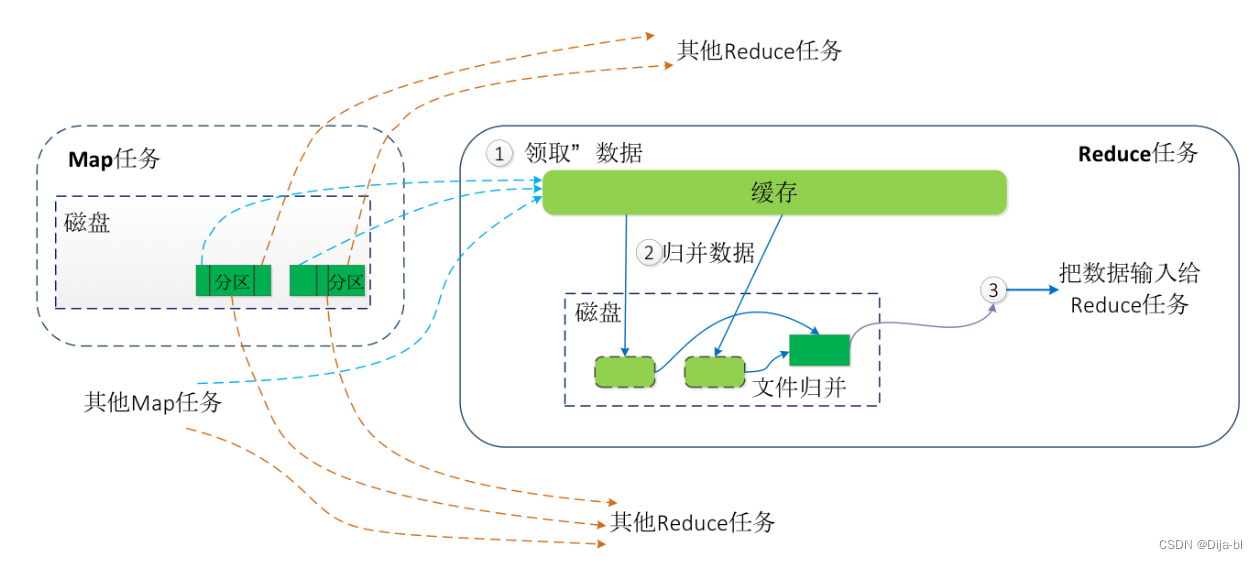
1. fetch copy(拉取拷贝) 阶段
Reduce 端默认有5个数据复制线程从 Map 端复制数据,其通过 Http 方式得到 Map 对应分区的输出文件。每个 MapTask 的完成时间可能不同,因此只要有一个任务完成,ReduceTask 就开始复制(copy)其输出。这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阈值的时候,就会将数据写到磁盘之上。
2. merge sort(合并排序)阶段
接下来就是sort阶段,也称为merge阶段。因为这个阶段的主要工作是执行了归并排序。
在 ReduceTask 远程复制数据的同时,会在后台开启2个线程(一个是内存到磁盘的合并,一个是磁盘到磁盘的合并)对内存中和本地磁盘中的数据文件进行合并操作,以防止内存使用过多或磁盘上文件过多。
在对数据进行合并的同时,会进行排序操作,由于MapTask 阶段已经对数据进行了局部的排序,因此,ReduceTask 只需对所有数据进行一次归并排序即可。
3. Reduce 阶段
当Reduce的输入文件确定后,整个Shuffle操作才最终结束。之后就是Reduce的执行了,reduce()函数将计算结果写到 HDFS 上。
至此整个 Shuffle 过程完成,最后总结几点:
1. Map 阶段的输出是写入本地磁盘而不是 HDFS,但是一开始数据并不是直接写入磁盘而是缓冲在内存中。
2. 缓存的好处就是减少磁盘 I/O 的开销,提高合并和排序的速度。
3. 内存缓冲区的大小默认是 100M(原则上说,缓冲区越大,磁盘 io 的次数越少,执行速度就越快。缓冲区的大小可以通过 mapreduce.task.io.sort.mb 参数调整),所以在编写 map 函数的时候要尽量减少内存的使用,为 Shuffle 过程预留更多的内存,因为该过程是最耗时的过程。














 2879
2879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









