






有时候,一个编程设计模式使用得十分普遍,甚至会逐步形成自己独特的语法。Python编程语言中的列表解析式(list comprehension)就是这类语法糖(syntactic sugar)的绝佳代表。
Python中的列表解析式是个伟大的发明,但是要掌握好这个语法则有些难,因为它们并是用来解决全新的问题:只是为解决已有问题提供了新的语法。
接下来,我们一起来学习什么是列表解析式,以及如何掌握使用这种语法的时机。
什么是列表解析式?
列表解析式是将一个列表(实际上适用于任何可迭代对象(iterable))转换成另一个列表的工具。在转换过程中,可以指定元素必须符合一定的条件,才能添加至新的列表中,这样每个元素都可以按需要进行转换。
如果你熟悉函数式编程(functional programming),你可以把列表解析式看作为结合了filter函数与map函数功能的语法糖:
>>> doubled_odds = map(lambda n: n * 2, filter(lambda n: n % 2 == 1, numbers)) >>> doubled_odds = [n * 2 for n in numbers if n % 2 == 1]
如果你不熟悉函数式编程,也不用担心:我稍后会通过for循环为大家讲解。
从循环到解析式
每个列表解析式都可以重写为for循环,但不是每个for循环都能重写为列表解析式。
掌握列表解析式使用时机的关键,在于不断练习识别那些看上去像列表解析式的问题(practice identifying problems that smell like list comprehensions)。
如果你能将自己的代码改写成类似下面这个for循环的形式,那么你也就可以将其改写为列表解析式:
new_things = []
for ITEM in old_things: if condition_based_on(ITEM): new_things.append("something with " + ITEM)
你可以将上面的for循环改写成这样的列表解析式:
new_things = ["something with " + ITEM for ITEM in old_things if condition_based_on(ITEM)]
列表解析式:可视化解读
可视化解读听上去是个不错的注意,但是我们怎么才能做到这点呢?
嘿嘿,只需要从for循环中复制粘贴,稍微调整一下就变成了列表解析式啦。
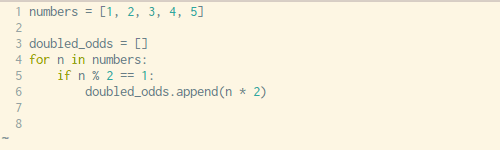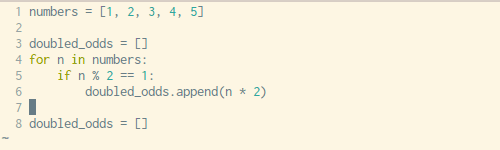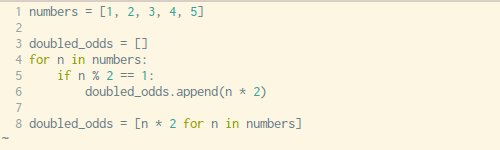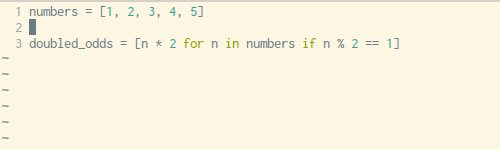
下面是我们复制粘贴的顺序:
- 将变量赋值操作复制到新建的空列表中(第三行)
- 将
append()方法中的表达式参数复制到新列表中(第六行) - 复制
for循环语句,不包括最后的:(第四行) - 复制
if条件控制语句,同样不包括最后的:(第五行)
这样,我们将从下面这段代码:
numbers = [1, 2, 3, 4, 5] doubled_odds = [] for n in numbers: if n % 2 == 1: doubled_odds.append(n * 2)
转换成了这两行代码:
numbers = [1, 2, 3, 4, 5] doubled_odds = [n * 2 for n in numbers if n % 2 == 1]
无条件子句的列表解析式
如果是那些没有条件子句(即if SOMETHING部分)的代码呢,又该怎样复制粘贴?这些形式的代码甚至比有条件子句的代码更好实现。
一个没有if语句的for循环:
doubled_numbers = []
for n in numbers: doubled_numbers.append(n * 2)
上面这段代码页可以改写为一个列表解析式:
doubled_numbers = [n * 2 for n in numbers]
下面是转换过程的详细演示:
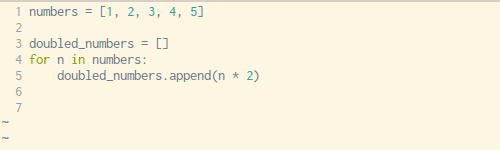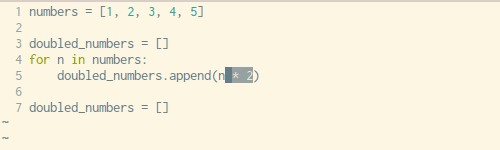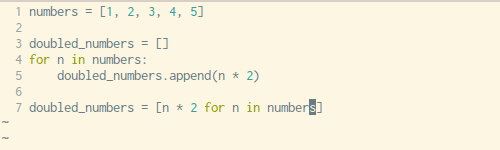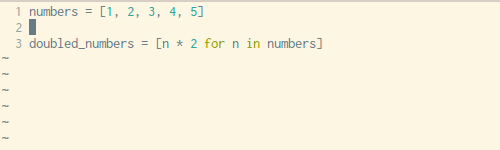
我们可以从上面那个简单的for循环中,安装这样的顺序复制粘贴:
- 将变量赋值操作复制到新建的空列表中(第三行)
- 将
append()方法中的表达式参数复制到新列表中(第五行) - 复制
for循环语句,不包括最后的:(第四行)
嵌套循环
那么嵌套循环(nested loop)又该怎样改写为列表解析式呢?
下面是一个拉平(flatten)矩阵(以列表为元素的列表)的for循环:
flattened = []
for row in matrix: for n in row: flattened.append(n)
下面这个列表解析式实现了相同的功能:
flattened = [n for row in matrix for n in row]
列表解析式中的嵌套循环读起来就有点绕口了。
注意:我本能地会想把这个列表解析式写成这样:
flattened = [n for n in row for row in matrix]
但是这行代码是错误的。这里我不小心颠倒了两个for循环的顺序。正确的代码是之前那个。
如果要在列表解析式中处理嵌套循环,请记住for循环子句的顺序与我们原来for循环的顺序是一致的。
同样地原则也适用集合解析式(set comprehension)和字典解析式(dictionary comprehension)。
其他解析式
下面的代码提取单词序列中每个单词的首字母,创建了一个集合(set):
first_letters = set()
for w in words: first_letters.add(w[0])
同样的代码可以改写为集合解析式:
first_letters = {w[0] for w in words}
下面的代码将原有字典的键和值互换,从而创建了一个新的字典:
flipped = {}
for key, value in original.items(): flipped[value] = key
同样的代码可以改写为字典解析式:
flipped = {value: key for key, value in original.items()}
还要注意可读性
你有没有发现上面的列表解析式读起来很困难?我经常发现,如果较长的列表解析式写成一行代码,那么阅读起来就非常困难。
不过,还好Python支持在括号和花括号之间断行。
列表解析式 List comprehension
断行前:
doubled_odds = [n * 2 for n in numbers if n % 2 == 1]
断行后:
doubled_odds = [
n * 2 for n in numbers if n % 2 == 1 ]
带嵌套循环的列表解析式
断行前:
flattened = [n for n in row for row in matrix]
断行后:
flattened = [
n
for row in matrix for n in row ]
字典解析式
断行前:
flipped = {value: key for key, value in original.items()}
断行后:
flipped = {
value: key for key, value in original.items() }
请注意,我们并不是随意进行断行:我们是在每一行复制过来的代码之后断行的。
总结
纠结于写不出列表解析式吗?不要担心。先写一个for循环,能后按照本文说的顺序复制粘贴,就可以写出解析式了。
任何类似下面代码形式的for循环:
new_things = []
for ITEM in old_things: if condition_based_on(ITEM): new_things.append("something with " + ITEM)
都可以被改写为下面这种列表解析式:
new_things = ["something with " + ITEM for ITEM in old_things if condition_based_on(ITEM)]
转载自:http://codingpy.com/article/python-list-comprehensions-explained-visually/















 7456
7456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









