







 本文详细介绍了Python中的字符串操作,包括拼接、计算长度、截取、分割、检索、大小写转换以及去除空格和特殊字符。同时,讲解了正则表达式的基础知识,如行定位符、元字符、限定符、字符类、排除字符、选择字符、转义字符、分组,并展示了如何在Python中使用re模块进行正则表达式操作,包括匹配、替换和分割字符串的方法。
本文详细介绍了Python中的字符串操作,包括拼接、计算长度、截取、分割、检索、大小写转换以及去除空格和特殊字符。同时,讲解了正则表达式的基础知识,如行定位符、元字符、限定符、字符类、排除字符、选择字符、转义字符、分组,并展示了如何在Python中使用re模块进行正则表达式操作,包括匹配、替换和分割字符串的方法。
Python数据分析基础
五、字符串与正则表达式
字符串几乎是所有编程语言在项目开发过程中涉及最多的一块内容。大部分项目的运行结果,都需要以文本的形式展示给客户,比如财务系统的总账报表,火车站的列车时刻表等。这些都是经过程序精密的计算、判断和梳理,将我们想要的内容用文本形式直观地展示出来。下面我们将重点介绍如果操作字符串和正则表达式的应用。
5.1 字符串常用操作
(1)拼接字符串
使用“+”运算符可完成对多个字符串的拼接,“+”运算符可以连接多个字符串并产生一个字符串对象。代码示例如下:
chinese = "汉语"
english = "English"
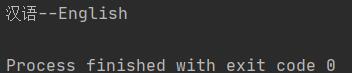
print(chinese + '--' + english)
输出结果如下:
注意:字符串不允许直接与其他类型的数据拼接,示例代码如下:
str1 = '今天我一共花了'
money = 88
str2 = '元'
print(str1 + num + str2)
输出结果如下:

上述问题的解决办法:可以将整数转化为字符串,可以使用str()函数实现,修改后如下,
str1 = '今天我一共花了'
money = 88
str2 = '元'
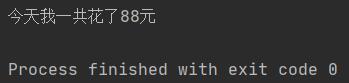
print(str1 + str(money) + str2)
最后输出如下:
(2)计算字符串的长度
由于不同的字符所占字节数不同,所以要计算字符串的长度,需要先了解各字符所占的字节数。在Python中,数字、英文、小数点、下划线和空格占一个字节;一个汉字可能会占2-4个字节,占几个字节取决于采用的编码。汉字在GBK/GB2312编码中占2个字节,在UTF-8/Unicode中一般占用3个字节(或4个字节)。下面以Python默认的UTF-8编码为例进行说明,即一个汉字占3个字节。在Python中,提供了len()函数计算字符串的长度,语法格式如下:
len(string)
string:用于指定要进行长度统计的字符串
代码示例如下:
str1 = '今天我一共花了88个W'
print(len(str1))
代码执行后输出结果为11。从执行结果可以看出,在默认情况下,通过len()函数计算字符串的长度时,不区分英文、数字和汉字,所有字符都认为是一个。
在实际开发中,有时需要获取字符串实际所占的字节数,即如果采用UTF-8编码,汉字占3个字节,采用GBK或者GB2312时,汉字占2个字节。这时,可以通过encode()方法进行编码后再进行获取。代码示例如下:
str1 = '今天我一共花了88个W'
print(len(str1.encode()))
代码执行后输出结果为27。因为8个汉字占24个字节,英文和数字占3个字节,总共27个字节。如果想要获取GBK编码的字符串长度,代码如下:
str1 = '今天我一共花了88个W'
print(len(str1.encode('gbk')))
代码执行后,输出结果为19。
(3)截取字符串
由于字符串也属于序列,所以要截取字符串,可以采用切片方法实现。通过切片截取字符串语法格式如下:
string[start : end : step]
string:表示要截取的字符串
start:表示要截取的第一个字符的索引(包括该字符),如果不指定,默认为0。
end:表示要截取的最后一个字符的索引(不包括该字符),如果不指定则默认为该字符串的长度。
step:表示切片的步长,如果省略,则默认为1,当省略该步长时,最后一个冒号也可以省略
说明:字符串的索引同序列的索引是一样的,也是从0开始,并且每个字符占一个位置。代码示例如下:
str1 = '今天我一共花了88个W'
substr1 = str1[1]
substr2 = str1[5:]
substr3 = str1[:5]
substr4 = str1[2:5]
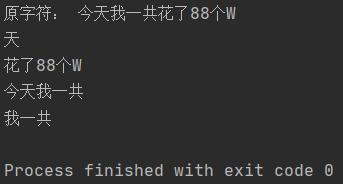
print('原字符:', str1)
print(substr1 + '\n' + substr2 + '\n' + substr3 + '\n' + substr4)
运行结果如下:
(4)分割字符串
在Python中,字符串对象提供了分割字符串的方法。分割字符串是把字符串分割为列表,分割字符串可以看做是互逆操作。字符串对象的split()方法可以实现字符串分割,也就是把一个字符串按照指定的分隔符切分为字符串列表,该列表的元素中,不包括分隔符。split()方法的语法格式如下:
str.split(sep, maxsplit)
str:表示要进行分割的字符串
sep:用于指定分隔符,可以包含多个字符,默认为None,即所有空字符(包括空格、换行“\n”、制表符“\t”等)
maxsplit:可选参数,用于指定分割的次数,如果不指定或者为-1,则分割次数没有限制,否则返回结果列表的元素个数最多为maxsplit+1。
返回值:分隔后的字符串列表
注意:在split()方法中如果不指定sep参数,那么也不能指定maxsplit参数。
示例代码如下:
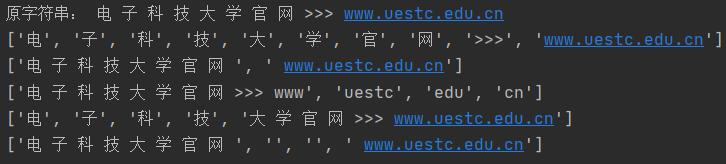
str1 = '电 子 科 技 大 学 官 网 >>> www.uestc.edu.cn'
print('原字符串:', str1)
list1 = str1.split() # 采用默认分隔符进行分割4
list2 = str1.split('>>>')
list3 = str1.split('.')
list4 = str1.split(' ', 4)
print(str(list1) + '\n' + str(list2) + '\n' + str(list3) + '\n' + str(list4))
list5 = str1.split('>')
print(list5)
运行结果如下:
说明:在使用split()方法时,如果不指定参数,默认采用空白符进行分割,这时无论有几个空格或者空白符都将作为一个分隔符进行分割。
(5)检索字符串
在Python中,字符串对象提供了很多应用于字符串查找的方法,下面开始介绍几种方法。
- count()方法
count()方法用于检索指定字符串在另一个字符串中出现的次数。如果检索的字符串不存在,则返回0,否则返回出现的次数。语法格式如下:
str.count(sub[, start[, end]])
str:表示原字符串。
sub:表示要检索的子字符串。
start:可选参数,表示检索范围的起始位置的索引,如果不指定则从头开始。
end:可选参数,表示检索范围的结束位置的索引,如果不指定,则一直检索到结尾。
示例代码如下:
str1 = '@电子科技大学官网 @四川大学 @四川师范大学'
print('字符串”', str1, '“中包括', str1. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 576
576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









