






 本文介绍了TensorFlow中创建和操作张量的基本方法,包括常量、转换、全零和全一张量,以及随机数生成。此外,还涉及张量的数学运算、变量、梯度计算,以及数据处理如one-hot编码。文章进一步讲解了卷积层、BN层、池化层在神经网络中的应用,以及数据增强技术提高模型泛化能力。
本文介绍了TensorFlow中创建和操作张量的基本方法,包括常量、转换、全零和全一张量,以及随机数生成。此外,还涉及张量的数学运算、变量、梯度计算,以及数据处理如one-hot编码。文章进一步讲解了卷积层、BN层、池化层在神经网络中的应用,以及数据增强技术提高模型泛化能力。
创建一个张量
tf.constant(张量内容,dtype=数据类型(可选))
将numpy的数据类型转换为Tensor数据类型
tf.convert_to_tensor(数据名,dtype=数据类型(可选))
创建全为0的张量 维度:
tf.zeros(维度) 一维 直接写个数
创建全为1的张量 二维 用【行,列】
tf.ones(维数) 多维 用【n,m,j,k........】
创建全为指定值的张量
tf.fill(维度,指定值)
生成正态分布的随机数,默认均值为0,标椎差为1
tf.random.normal(维度,mean=均值,stddev=标椎差)
生成截断式正态分布的随机数
tf.random.truncated_normal(维度,mean=均值,stddev=标椎差),在tf.truncated_normal中如果随机生成数据的取值在(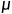 -2
-2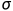 ,+2)之外则重新进行生成,保证了生成值在均值附近。
,+2)之外则重新进行生成,保证了生成值在均值附近。
生成均匀分布随机数
tf.random.uniform(维度, minval=最小值, maxval=最大值)
强制tensor转换为该数据类型
tf.cast(张量名,dtype=数据类型)
计算张量维度上元素的最小值
tf.reduce_min(张量名)
计算张量维度上元素的最大值
tf.reduce_max(张量名)
理解axis
在一个二维张量或数组中,可以通过调整axis等于0或1控制执行维度。axis=0代表跨性行(经度,down),而axis=1代表跨列(维度,across)。如果不指定axis。则所有元素参与计算。
计算张量沿着指定维度的平均值
tf.reduce_mean(张量名,axis=操作轴)
计算张量沿着指定维度的和
tf.reduce_sum(张量名,axis=操作轴)
常用函数
tf.Variable()将变量标记为“可训练”,被标记的变量会在反向传播中记录梯度信息。神经网络训练中,常用该函数标记待训练参数。
实现两个张量的对应元素相加
tf.add(张量1,张量2) 只有维度相同的张量才可以做四则运算
实现两个张量的对应元素相减
tf.substract(张量1,张量2)
实现两个张量的对应元素相乘
tf.multiply(张量1,张量2)
实现两个张量的对应元素除
tf.divide(张量1,张量2)
计算某个张量的平方
tf.square(张量名)
计算某个张量的n次方
tf.pow(张量名,n次方数)
计算某个张量的开方
tf.sqrt(张量名)
实现两个矩阵的相乘
tf.matmul(矩阵1,矩阵2)
切分传入张量的第一维度,生成输入特征/标签对,构建数据集
data = tf.data.Dataset.from_tensor_slices((输入特征,标签))(Numpy和Tensor格式都可用该语句读入数据)
with结构记录计算过程,gradient求出张量的梯度
with tf.GradientTape() as tape:
若干个计算过程
grad=tape.gradient函数,对谁求导)
enumerate是python的内建函数,它可遍历每个元素(如列表、元组或字符串),组合为:索引 元素,常在for循环中使用。
tf.one_hot()函数将待转换数据,转换为one_hot形式的数据输出。
tf.one_hot(待转换数据,depth=几分类)
赋值操作,更新参数的值并返回。
调用assign_sub前,先用tf.Variable定义变量w为可训练(可自更新)
w.assign_sub(w要自减的内容)
返回张量沿指定维度最大值的索引
tf.argmax(张量名,axis=操作轴)
条件语句真返回A,条件语句假返回B
tf.where(条件语句,真返回A,假返回B)
将两个数组按垂直方向叠加
np.vstack(数组1,数组2)
np.mgrid[起始值:结束值:步长,起始值:结束值:步长,......]
x.ravel() 将x变为一维数组,“把.前变量拉直”
np.c_[ ]使返回的间隔数值点配对
np.c_[数组1,数组2,.......]
数据增强
image_gen_train = tf.keras.preprocessing.image.ImageDataGenerator(rescale = 所有数据将乘以该数值 rotation_ange = 随机旋转角度数范围 width_shift_range = 随机宽度偏移量 height_shift_range = 随机高度偏移量 水平翻转:horizontal_filp = 是否随机水平翻转 随机缩放: zoom_range = 随机缩放的范围【1-n,1+n】)
TF描述卷积层
tf.keras.layers.Conv2D(
filters = 卷积核个数,
kernel_size =卷积核尺寸,#正方形写核长整数或(核高h,核宽w)
strides =滑动步长,#横纵向相同写步长整数,或(纵向步长h,横向步长w),默认1
padding = “same”or“valid”#使用全零填充是“same”,不使用是“valid”(默认)
activation= “relu”or“sigmoid”or“tanh”or“softmax”等
input_shape = (高,宽,通道数) #输入特征图维度,可省
)
BN层位于卷积之后,激活层之前。
tf.keras.layers.BatchNormalization()
池化用于减少特征数据量,最大值池化可提取图片纹理,均值池化可保留背景特征。
tf.keras.layers.MaxPool2D(
pool_size = 池化核尺寸,#正方形写核长整数,或(核高h,核宽w)
strides=池化步长,#步长整数,或(纵向步长h,横向步长w),默认为pool_size
padding=“valid”or“same”#使用全零填充是“same”,不使用“valid”(默认)
)
tf.keras.layers.AveragePooling2D(
pool_size=池化核尺寸,#正方形写核长整数,或(核高h,核宽w)
strides=池化步长,#步长整数,或(纵向步长h,横向步长w),默认为pool_size
padding=“valid”or“same”#使用全零填充是“same”,不使用是“valid”(默认)
)
在神经网络训练时,将一部分神经元按照一定概率从神经网络中暂时舍弃。神经网络使用时,被舍弃的神经元恢复链接。
tf.keras.layers.Dropout(舍弃的概率)

















 6986
6986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









