







原文地址:https://arxiv.org/abs/2403.08593
摘要
大型语言模型(LLMs)在推理结构化环境(例如知识图谱和表格)方面展现出潜力。这类任务通常需要多跳推理,即匹配自然语言表述与环境中实例。先前的工作采用LLMs逐步构建推理路径,其中LLMs要么调用工具,要么通过逐步与环境交互来选择项目。本文提出了 Reasoning-Path-Editing (Readi) 框架,LLMs 可以在该框架下高效且忠实地推理结构化环境。在 Readi 中,LLMs 首先根据查询生成推理路径,并在必要时编辑路径。本文将路径实例化到结构化环境中,并在出现错误时提供反馈以编辑路径。
在三个 KGQA 和两个 TableQA 数据集上的实验结果表明 Readi 的有效性,显著优于先前的基于 LLM 的方法(WebQSP 上 Hit@1 提高 9.1%,MQA-3H 上提高 12.4%,WTQ 上提高 9.5%),与最先进的微调方法相当(CWQ 上 67%,WebQSP 上 74.7%),并且显着提高了原始 LLM 的性能(CWQ 上提高 14.9%)。本文的代码将在 https://aka.ms/readi 上提供。
1. 引言
大型语言模型(LLMs)在自然语言处理(NLP)领域表现出色。为了进一步释放它们在复杂场景中的推理能力,研究人员提出了精细的策略,例如让 LLMs 具备类似人类的思维方式(例如 Chain-of-thought)或将它们作为能够进行规划、反思和执行的自主智能体。一个引人入胜的场景是推理结构化环境(SEs),例如知识图谱和表格。这些环境具有专门的架构,抽象现实世界语义以表示、存储和查询具有关系结构的数据。
尽管 LLMs 表现出令人鼓舞的能力,但当面对涉及大规模 SEs 的多跳推理时,它们的性能往往不尽如人意。为了进行忠实的推理,先前的工作采用迭代方法,从某些元素(例如实体、关系或表格中的列)开始,在 SEs 上实例化,然后逐步扩展推理路径,同时仅消耗相关部分而不是整个环境。这种逐步交互可以一定程度上减轻 LLMs 的幻觉。然而,推理效率会降低,从而阻碍其实际可行性。
为了解决这些问题,本文寻求提出一种交互范式,利用 LLMs 在大型 SEs 上高效且忠实地支持复杂推理。本文对 KGQA 任务进行了实证研究,发现 LLMs 最初生成的 46%-60% 的推理路径可以很好地实例化,这激发了本文在复杂推理中充分利用 LLM 内在规划能力的想法。虽然计划-改进的想法简单直观,并且在各种现实世界任务中得到了应用,但当初始计划遇到障碍时,其在 SEs 中的应用研究却很少。
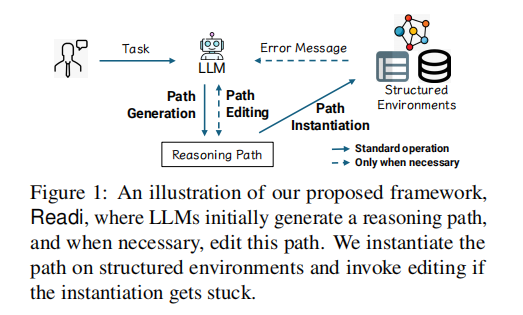
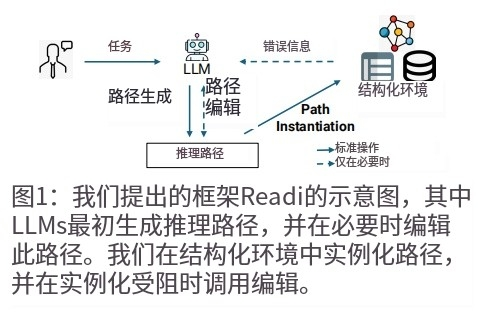
在这篇论文中,本文提出了 Reasoning-Path-Editing (Readi) 框架,该框架利用 LLMs 的内在规划能力(图 1)。在 Readi 中,LLMs 首先生成推理路径,然后将其实例化到环境中以促进忠实推理。仅在实例化受阻时触发路径编辑。这样,本文减轻了 LLMs 逐步交互的负担,从而提高了整体效率。为了利用大规模 SEs 的信息,本文不是将整个静态 SEs 注入模型,而是收集推理日志作为即时反馈,其中包括诸如卡住点的位置、相关关系、半完成实例等详细信息。这种动态指导更有针对性地改进推理路径,并进一步提高了忠实性。本文在知识图谱问答(KGQA)和表格问答(TableQA)上的实验表明,Readi 在 LLM-calls 和准确性方面优于现有解决方案。
2. 相关工作
- LLMs 逐步推理结构化环境:现有工作将任务分解为逐步构建推理路径,将 LLMs 视为基于历史状态和观察调用工具的智能体,或者设计迭代过程,其中 LLMs 负责在 SEs 上选择项目。这些工作通过利用 LLMs 的推理能力来选择工具或项目来实现忠实性。然而,它们的性能受到以下三个方面的限制:
- 与 SEs 的逐步交互繁琐,需要多次 LLM 调用,对于复杂推理任务尤其效率低下。
- 贪婪的逐步决策缺乏对路径的全局视图,容易导致错误传播。
- 累积的提示很长,LLMs 可能会失去对历史或候选者的注意力。
- 通过微调在结构化环境上进行端到端推理:微调模型通过在注释上进行训练来记忆环境。它们要么直接生成路径,然后将其与 SEs 相关联(例如 RoG),要么检索相关项目来构建路径(例如 SR)。这种端到端推理无需与 SEs 进行交互,效率很高。然而,它们存在以下三个局限性:
- 推理路径的关联性仅取决于模型输出,不能保证在 SEs 上的忠实性。
- 它们严重依赖注释,对于大规模环境来说获取注释既昂贵又困难。
- 在训练期间未见过的数据上性能大幅下降,这在现实世界场景中很常见。
- LLMs 的计划-改进推理:为了提高 LLMs 推理的忠实性,先前的工作采用 LLMs 来改进输出。一些方法要求 LLMs 自我纠正,提示它们识别和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









