








原文链接:https://arxiv.org/abs/2201.05596
摘要
随着大型密集模型训练资源的需求达到瓶颈,混合专家(MoE)模型因其显著的训练成本降低而成为最具前景的模型架构之一。其训练成本降低不仅体现在编码器-解码器模型上,更在自动回归语言模型上实现了 5 倍的节省。然而,由于 MoE 模型规模庞大且架构独特,如何提供快速推理仍然是一个挑战,这限制了其实际应用。
为了解决这个问题,本文提出了 DeepSpeed-MoE,这是一个端到端的 MoE 训练和推理解决方案,作为 DeepSpeed 库的一部分。它包括新颖的 MoE 架构设计和模型压缩技术,可以将 MoE 模型规模降低高达 3.7 倍,并提供了一个高度优化的推理系统,其延迟和成本比现有的 MoE 推理解决方案提高了 7.3 倍。DeepSpeed-MoE 为大规模 MoE 模型提供了前所未有的规模和效率,其推理速度比质量相当的密集模型快 4.5 倍,成本低 9 倍。本文希望本文的创新和系统能够为大型模型领域开辟一条新的道路,从密集模型转向稀疏 MoE 模型,使得使用更少的资源训练和部署更高质量的模型成为可能。
1. 引言
在过去的三年里,训练的最大的模型规模增加了超过 1000 倍,从几亿参数增加到 500 亿参数(Megatron-Turing NLG 530B)。模型质量的提升表明,这一趋势将继续发展,更大的模型规模将带来更好的模型质量。
然而,由于计算需求的增加,维持模型规模的增长变得越来越困难。例如,截至 2021 年 12 月,最大的单个密集模型 Megatron-Turing NLG 530B 模型,在 NVIDIA Selene 超级计算机上的 2000 多个 A100 GPU 上训练需要大约 3 个月,消耗了超过 300 万 GPU 小时。
在现有硬件资源限制下,模型规模的进一步增加是不切实际的。因此,一个自然的问题就是:是否可以在不增加计算成本的情况下显著提高模型质量?或者说,是否可以使用 3 到 5 倍更少的资源来生成具有相似质量的模型?
为了减少训练大型模型所需的计算资源,已经做出了许多努力。为此,基于混合专家(MoE)的架构开辟了一条有希望的道路,它能够实现与模型参数成非线性关系的计算需求,并在不增加训练成本的情况下提高模型质量。
然而,MoE 模型也面临一些挑战,限制了其在各种实际场景中的应用:
- 应用范围有限:MoE 模型在自然语言处理(NLP)领域的应用范围主要局限于编码器-解码器模型和序列到序列任务,在其他领域的应用探索有限。将 MoE 应用于自动回归自然语言生成(NLG)任务,如 GPT-3 和 MT-NLG 530B,这些任务中训练最先进语言模型的计算成本比编码器-解码器模型高几个数量级,目前探索较少。
- 大量内存需求:虽然 MoE 模型在实现与密集模型相同模型质量的同时,所需的计算量更少,但它们需要显著更多的参数。例如,基于 MoE 的 Switch-Base 模型比 T5-large (7.4B vs 0.74B) 多 10 倍的参数,但即使在广泛的下游任务中比较,其模型质量也仍然不如后者。换句话说,与质量相当的密集模型相比,基于 MoE 的模型具有更低的“参数效率”。
- 推理性能有限:由于上述模型规模庞大和参数效率低,快速推理 MoE 模型更具挑战性。一方面,更大的参数规模需要更多的 GPU 来容纳,而多 GPU 推理技术尚未针对 MoE 模型进行优化。另一方面,由于推理通常受内存带宽限制,MoE 模型可能需要比密集模型高 10 倍的内存带宽才能实现相同的推理延迟。
尽管 MoE 在降低训练成本方面具有巨大的潜力,但上述挑战严重限制了其实际应用。为了使 MoE 更实用、易用和适用,本文提出了解决这些挑战的三种对应方案:
- 将 MoE 模型的应用范围扩展到自动回归 NLG 任务,证明通过 5 倍的训练成本降低,可以实现与 GPT-3 和 MT-NLG 等模型相同的质量。这些结果不仅证明了降低大规模 NLG 模型训练成本的明确机会,而且为在现有硬件资源限制下达到更高的下一代模型质量开辟了可能性。
- 通过开发名为Pyramid-Residual MoE (PR-MoE) 的新型 MoE 架构来提高 MoE 模型的参数效率。PR-MoE 是一个混合密集和 MoE 模型,使用残差连接创建,同时在最有效的地方应用专家。PR-MoE 可以将 MoE 模型参数规模降低高达 3 倍,而不会影响模型质量,也不会显著改变计算需求。此外,本文通过阶段知识蒸馏创建了 PR-MoE 的蒸馏版本,本文称之为Mixture-of-Students(MoS)。MoS 将 MoE 模型规模降低高达 3.7 倍,同时保持可比较的模型质量。
- 开发 DeepSpeed-MoE 推理系统,这是一个高度优化的 MoE 推理系统,能够在数百个 GPU 上高效地扩展推理工作负载,与现有的 MoE 推理解决方案相比,推理延迟和成本降低了 7.3 倍。它为万亿参数 MoE 模型提供超低延迟(低于 25 毫秒)的推理。DeepSpeed-MoE 还结合了系统和模型优化,为 MoE 模型提供高达 4.5 倍的推理速度和 9 倍的更低的推理成本,与质量相当的密集模型相比。
总之,本文的创新和系统使 MoE 成为比密集模型更有效、更经济的替代方案,在获得相同模型质量的同时,显著降低了训练和推理成本。或者说,它们可以用来赋能下一代人工智能规模,而无需增加计算资源。本文希望 DeepSpeed-MoE 能够为大型模型领域开辟一条新的道路,从密集模型转向稀疏 MoE 模型,使得使用更少的资源训练和部署更高质量的模型成为可能。
论文大纲 本文接下来将首先介绍必要的背景和相关工作,然后以独立章节的形式介绍上述三个解决方案。
软件代码 本文正在分阶段将 DeepSpeed-MoE 作为 DeepSpeed 库的一部分进行开源。请在 DeepSpeed GitHub (https://github.com/microsoft/DeepSpeed) 和网站 (https://www.deepspeed.ai/) 找到代码、教程和文档。
本文中的实验是在 Microsoft Azure AI 平台上进行的,这是使用 DeepSpeed 训练和服务模型的最佳平台。本文的教程包括如何在 Azure 上开始使用 DeepSpeed,以及如何使用 Azure ML 进行不同模型的实验。
2. 相关工作
2.1 大规模密集 NLP 模型
为了测试和验证模型容量与参数数量之间的关系缩放法则,预训练的自然语言处理模型规模在过去几年中每年增长 10 倍。
早期工作通常规模为几亿参数,包括 BERT、XLNet、RoBERTa、ALBERT 和 GPT等。后来,出现了数十亿到数百亿参数的模型,例如 GPT-2、TuringNLG、Megatron-LM和 T5 ,它们在各种自然语言理解和生成任务上表现出更好的泛化性能 。GPT-3 进一步将上限推高到 1750 亿参数,并表明,通过零样本/少样本学习,它可以达到与之前小型模型相当甚至更好的性能。
最近,Megatron-Turing NLG 530B 模型通过 DeepSpeed和 Megatron-LM的软件支持实现了 5300 亿参数,并在一个密集模型内实现了零样本/少样本学习的最新最先进结果。然而,由于训练需要超过 2000 个 A100 GPU 的 3 个月时间,单纯通过增加模型规模来提高模型质量已经不再可行,因为计算需求无法克服。
2.2 通过 MoE 架构降低训练成本
降低训练成本的一个有希望的方法是使用混合专家 (MoE)。在 [3] 中,作者通过在堆叠的 LSTM 层之间应用卷积 MoE 层,将基于 LSTM 的模型扩展到 1270 亿参数,用于语言建模和机器翻译。MoE 的稀疏特性显着提高了模型规模的缩放能力,同时没有增加计算成本。GShard 利用 MoE 训练基于 Transformer 的模型,参数达到 6000 亿,用于多语言翻译,并表明该 6000 亿 MoE 模型的训练成本甚至低于 1000 亿参数的密集模型。Switch Transformer基于 T5 模型,将模型扩展到 1600 亿。为了实现相同的精度性能,表明 MoE 模型的训练速度比大型密集模型快 2.5 倍。
之后,更多最近的研究展示了 MoE 的稀疏优势。
一些最近和并行的工作表明,MoE 模型也可以应用于自动回归自然语言生成任务,包括在多个下游评估任务上的初步结果。然而,本文的工作与这些并行探索的主要区别在于:
(1) 本文的工作研究了 MoE 模型的训练、模型设计和推理机会,而 [30, 31] 主要关注 MoE 训练;
(2) 本文提出了 PR-MoE 架构和 MoS 知识蒸馏,以实现更好的 MoE 参数效率和可比较/更好的零样本评估质量,如第 3.3 节所述;
(3) 本文开发了 DeepSpeed-MoE 推理系统,以有效地在数百个 GPU 上服务大规模 MoE 模型,与现有的 MoE 推理解决方案相比,推理延迟和成本降低了 7.3 倍。
虽然最近的研究讨论了 FLOPs 的减少,但值得注意的是,与训练不同,推理延迟和成本不仅取决于计算。高效的推理取决于模型大小、内存带宽以及系统从内存中高效读取数据的能力。DeepSpeed-MoE 推理系统是一个端到端的系统,它结合了模型架构创新(第 4 节)和众多优化和技巧(第 5 节),以提供超低延迟和超线性速度提升,从而提高吞吐量。
2.3 MoE 训练和推理系统
鉴于世界各地许多研究人员对 MoE 模型的采用,正在开发或扩展开源系统和框架以支持 MoE 模型训练。据本文所知,还没有专门设计并优化用于推理的 MoE 系统。最近提出了几个 MoE 训练系统。下面本文讨论其中几个。
DeepSpeed MoE 训练系统主要针对大规模 MoE 模型的优化训练。这项工作的主要目标是建立一个灵活的用户 API,以扩展现有的训练代码,以有效地进行可扩展的 MoE 模型训练。它通过灵活组合不同类型的并行性(包括张量切片、数据并行、ZeRO动力的数据并行和专家并行)支持高达 8 倍更大的模型大小。它被用于训练 Z-code MoE,这是一个 10 亿参数的多任务多语言 MoE 模型(Transformer 编码器-解码器架构),在 50 种语言上训练,与同等质量的密集模型相比,训练时间减少了 5 倍。
FastMoE是一种研究软件,用于展示如何在数据并行和专家并行下训练 MoE 模型。各种并行维度的组合并不完全支持。
Fast-MoE 示例包括 Transformer-XL 和 Megatron-LM,但关于大规模端到端训练的结果尚不可用。Fairseq-MoE提供了一个 MoE API 以及用于通用语言模型的训练流程。Fairseq 系统已被 Tutel进一步优化,比 Fairseq 提供高达 40% 的改进。
3. DeepSpeed-MoE 用于 NLG:将语言模型的训练成本降低 5 倍
基于 Transformer 的自动回归自然语言生成 (NLG) 模型为从文档摘要、标题生成、问答到在各种编程语言中生成代码等广泛的语言任务提供了有说服力的解决方案。由于这些模型的通用性,提高其质量对学术界和工业界都极为重要。
由于 NLG 家族模型的训练需要巨大的计算和能源,本文探索 MoE 提供的降低训练成本的机会。本文表明,MoE 可以应用于 NLG 家族模型,以显着提高其模型质量,同时保持相同的训练成本。或者,它可以将训练成本降低 5 倍,以实现与密集 NLG 模型相同的质量。
3.1 基于 MoE 的 NLG 模型架构
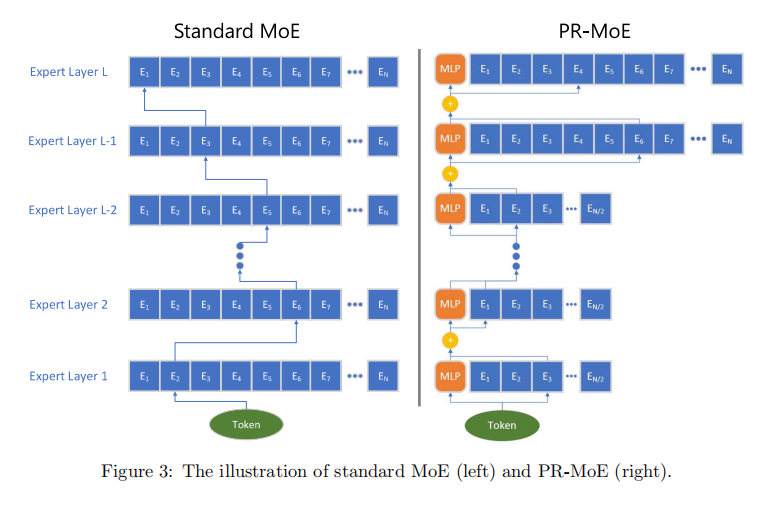
为了创建一个基于 MoE 的 NLG 模型,本文研究了类似 GPT 的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1767
1767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









