







1、KNN算法原理:
(1)为了判断预测集的类别,以已知类别的训练集作为参照选择参数K
(2)计算预测集中的实例与训练集中的所有已知实例的距离(如欧氏距离)
(3)选择最近的K个已知实例
(4)根据少数服从多数的投票法则(majority_voting),让未知实例归类为K个最邻近样本中最多数的类别
2、算法缺点:
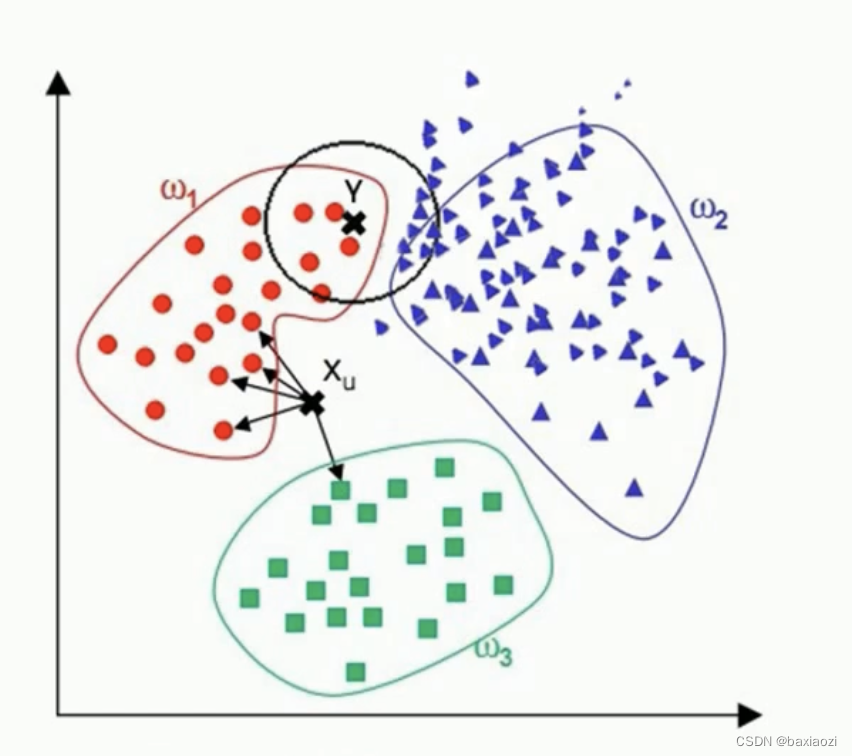
当样本分布不平衡时,比如其中一类样本过大(实例数量过多)占主导的时候,虚拟的未知实例容易被归类为这个主导样本,因为这类样本实例的数量过大,但这个新的未知实例实际并没有接近目标样本。
如下图所示,因为w2样本数量过大,因此有被错误分类到w2的可能
3、代码展示:(关键函数均有注释)
python机器学习KNN算法 相关代码
myknn_iris.py:
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report,confusion_matrix
import operator
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
def knn(x_test,x_data,y_data,k): #x_test是测试元素、x_data是训练集,y_data是训练集分类结果
#计算数据集数量
x_data_size = x_data.shape[0]
#计算x_test与数据集中每一个实例的差值
#np.tile(a,(2,1))第一个参数为Y轴扩大倍数,第二个为X轴扩大倍数,即将数组a向Y轴扩大2倍,向X轴扩大1倍。
diffMat = np.tile(x_test, (x_data_size,1)) - x_data
#计算欧氏距离
sqDiffMat = diffMat**2
#sum()为求和函数,axis=0代表沿Y轴求和;axis=1代表沿X轴求和
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
#进行排序,注意argsort()的返回值是一个列表,其元素是distances的元素的索引值(从零开始),且其排序遵循每个索引值对应的元素值逐渐递增的规则
#ex:distances=[20,18,19,115,117,108] sortedDistances=[1,2,0,5,3,4]
sortedDistances = distances.argsort()
#建立一个空字典
classCount = {}
for i in range(k): #对离测试点最近的k个元素进行分类
#确定对应的类别
votelabel = y_data[sortedDistances[i]]
#统计标签数量,classCount.get(votelabel,0)的意思是如果没有名为votelabel的键,那就添加一个名为votelabel的键并且赋其值为0
classCount[votelabel] = classCount.get(votelabel,0) + 1
#再对字典中的键值对进行排序,寻找值最大的那一组
#key=operator.itemgetter(1)的意思是根据字典的值进行由小到大排序;reverse=True的意思是进行反转,这个函数会返回一个二维数组
#例如:classCount={A:5,B:2,C:3} sortedClassCount = [ [A,5], [C,3], [B,2] ]
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
#返回"值"最大的键值对的"键"
return sortedClassCount[0][0]
iris = datasets.load_iris() # 读入鸢尾花数据集,iris是一个词典,其中iris.data存储的是各个样本四个参数的值,iris.data存储的是分类结果
x_train,x_test,y_train,y_test = train_test_split(iris.data, iris.target, test_size=0.4) #分割得到120个元素的训练集和30个元素的测试集
predictions = [] #用来存储预测的结果
for i in range(x_test.shape[0]):
predictions.append(knn(x_test[i],x_train,y_train,5)) #knn函数一次只能预测一个数据,因此需要进行迭代处理所有的x_test
print(classification_report(y_test,predictions)) #计算准确率,传入预测值和实际值
print(confusion_matrix(y_test,predictions)) #计算混淆矩阵,传入预测值和实际值
data = sns.load_dataset("iris")
sns.pairplot(data,hue="species",diag_kind="kde")
plt.show()
myknn_fruits.py:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report,confusion_matrix
data = pd.read_excel("fruit_data.xlsx") # 读入水果数据集
#切分数据集,stratify=data.iloc[:,1]表示切分后训练集和数据集中数据类型的比例跟切分前原始集中的比例一致
#如原始集中apple和lemon的比例为1:2,则切分后y_train和y_test中apple和lemon的比例也为1:2
#random_state=20设置随机数种子,保证每次切分结果相同
x_train,x_test,y_train,y_test = train_test_split(data.iloc[:,2:], data.iloc[:,1], test_size=0.4,stratify=data.iloc[:,1],random_state=20) #分割得到测试集和训练集
test_scores = [] #保存不同k值下的预测集准确率
k = 30
for i in range(1,k):
knn = KNeighborsClassifier(i) #生成模型
knn.fit(x_train,y_train) #训练模型
test_scores.append(knn.score(x_test,y_test)) #将预测集得分写入test_scores
#绘制k值对于精确度的影响
plt.figure(num=1)
plt.title("KNN Varying number of neighbors")
plt.plot(range(1,k),test_scores,label="Tset")
plt.legend()
plt.xticks(range(1,k))
plt.xlabel("k")
plt.ylabel("scores")
plt.show()
#选取情况最好下的k值作为最终取值
#np.argmax(a)#取出a中元素最大值所对应的索引
#Ex: b=np.argmax(np.array([3, 1, 2, 4, 6, 1])),即b赋值为4
k = np.argmax(test_scores) + 1
knn = KNeighborsClassifier(k) #生成模型
knn.fit(x_train,y_train) #训练模型
y_pre = knn.predict(x_test) #得到预测结果
print(classification_report(y_test,y_pre)) #计算准确率,传入预测值和实际值
print(confusion_matrix(y_test,y_pre)) #计算混淆矩阵,传入预测值和实际值
#绘制直方图
plt.figure(num=2)
sns.countplot(data['fruit_name'],label="Count")
plt.show()
#绘制4x4图
sns.pairplot(data,hue='fruit_label',vars=['mass','width','height','color_score'],diag_kind='hist')
plt.show()















 488
488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









