







4.SparkMLlib 支持向量机SVM算法
4.1 支持向量机算法
支持向量机是数据挖掘中一个很经典的算法,因为其推导过程涉及很多数学概念且其核函数的变化,在此将用尽量通俗的语言来描述这一算法,从其功能性出发进行讲解。支持向量机不仅对分类问题有良好的处理效果,对回归问题也有很好的解决方案。
SVM分类器可以在样本空间中对属于不同类别的样本进行区分,用来作为区分的分隔面就是分隔超平面。对于一个SVM算法,输入带有标签的训练样本,输出的是一个最好的分隔超平面。如下图所示:
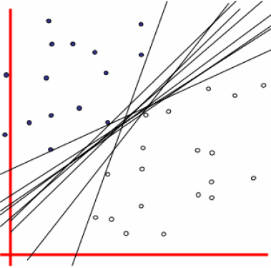
这是一个二维平面上属于两个类别上的点,我们试图寻找一条直线进行分隔,可以发现有很多条直线满足要求。但是一条直线如果距离样本太近,会对数据中的噪声敏感性高,就会导致泛化能力下降,所以我们的目标是找到一条尽可能远离所有样本点的直线。
支持向量机的实质就是找出一个分隔超平面使得该超平面距离所有训练样本(这里的点可以简化为是离超平面最近的点)的最小距离在所有分隔面中是最大的,这个最小距离叫做间隔margin,这些距离超平面最近的点叫做支持向量,该超平面也就是最优超平面。
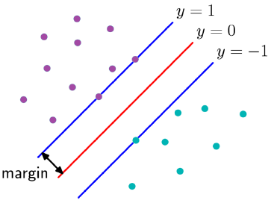
如上图所示,我们的目标就是在超平面将所有样本正确分类的前提下,求出这个最优超平面的margin,然后最大化这个margin。这个问题可以转化为一个拉格朗日优化问题,可以使用拉格朗日乘数法得到最优超平面的相关参数。这里就不再赘述正面过程。此外svm还可以通过改变核函数,将原始空间线性不可分的数据映射到高维空间变成线性可分的。
4.2 算法源码分析
在MLlib中,实现了线性SVM分类模型,使用随机梯度下降算法来优化目标函数。其实现过程如下:
(1)SVMWtihSGD:SVM线性分类伴生对象:基于随机梯度下降,含有train静态方法,设置SVM分类参数创建SVM分类,执行run方法训练模型,train方法主要参数如下:
- input——训练样本格式为RDD(label,features)
- numIterations——运行的迭代次数,默认100
- stepSize——每次迭代的步长,默认1
- miniBatchFraction——每次迭代参与计算的样本比例,默认1
- initialWeights——初始化权重
(2)SVMWithSGD类:SVM线性分类,包含run方法,先对样本加偏置再初始化权重,最后用optimizer.optimize方法计算优化权重从而获取最优权重;
(3)runMiniBatchSGD:优化计算权重:根据训练样本迭代计算随机梯度从而得到最优权重,每次迭代计算样本梯度并更新,分别使用gradient.compute和updater.compute方法;
(4)SVMModel:SVM线性分类模型,含有predict方法,根据分类模型计算样本预测值,返回RDD[double]。
4.3 应用实战
4.3.1 数据说明
此次实战使用sample_libsvm_data样本数据。
4.3.2 代码详解
//导入需要的包文件
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.mllib.classification.{SVMModel, SVMWithSGD}
import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics
import org.apache.spark.mllib.util.MLUtils
//构建Spark对象
val conf = new SparkConf().setAppName("SVM")
val sc = new SparkContext(conf)
//读取样本数据
val data = MLUtils.loadLibSVMFile(sc, "/mnt/hgfs/thunder-
download/MLlib_rep/data/sample_libsvm_data.txt")
//对样本数据划分为训练与测试样本,比例为6:4
val splits = data.randomSplit(Array(0.6, 0.4), seed = 11L)
//训练样本
val training = splits(0).cache()
输出结果:
training: org.apache.spark.rdd.RDD[org.apache.spark.mllib.regression.LabeledPoint] = MapPartitionsRDD[112] at randomSplit at <console>:37
//测试样本
val test = splits(1)
输出结果:
test: org.apache.spark.rdd.RDD[org.apache.spark.mllib.regression.LabeledPoint] = MapPartitionsRDD[113] at randomSplit at <console>:37
//配置训练参数
val numIterations = 100
输出结果:numIterations: Int = 100
//训练模型
val model = SVMWithSGD.train(training, numIterations)
输出结果:
model: org.apache.spark.mllib.classification.SVMModel =
org.apache.spark.mllib.classification.SVMModel: intercept = 0.0, numFeatures = 692, numClasses = 2, threshold = 0.0
//对测试样本进行预测
val scoreAndLabels = test.map { point =>
| val score = model.predict(point.features)
| (score, point.label)
| }
输出结果:
scoreAndLabels: org.apache.spark.rdd.RDD[(Double, Double)] =
MapPartitionsRDD[317] at map at <console>:47
返回数据类型RDD
//计算误差
val metrics = new BinaryClassificationMetrics(scoreAndLabels)
val auROC = metrics.areaUnderROC()
println("Area under ROC = " + auROC)
输出结果:
Area under ROC = 1.0
分类精度1.0














 4457
4457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









