







写作背景
前面复习了SpringCloud Netflix的几个核心组件,包括Eureka、Ribbon、Feign、Hystrix、Zuul,并进行了Demo级别的实战,主要是通过简单的Demo跑起来,然后通过源码来验证组件的核心功能。今天要复习的是链路监控部分,SpringCloud Sleuth + Zipkin,参考官网SpringCloud Sleuth,本文的书写思路和之前不太一样,这次就是主要在之前搭的微服务基础上集成Sleuth+Zipkin来实战演示,没有源码验证部分。
为什么要有链路监控
在微服务架构下,一次请求往往会涉及多个服务,在系统发生故障的时候,想要快速定位和解决问题,就需要追踪服务请求序列。因此分布式调用链路监控组件在这样的需求下就产生了。
SpringCloud Sleuth+Zipkin能做什么
Spring Cloud Sleuth 为服务之间的调用提供链路追踪,通过 Sleuth 可以很清楚地了解到,一个服务请求经过了哪些服务,每个服务处理花费了多少时间,从而可以很方便地
1、理清各微服务间的调用关系
2、还可很方便地看到每个采样请求的耗时,从而分析出些服务调用比较耗时
3、Sleuth还可以可视化错误,然后集成到Zipkin的界面看到
4、对于调用比较频繁的服务,可以有针对性地进行优化措施
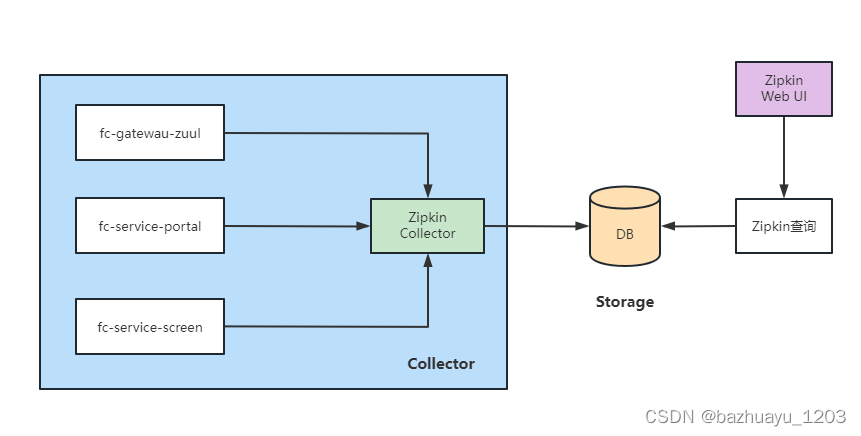
Zipkin是Twitter公司开源的分布式跟踪系统,用于收集服务的定时数据。Zipkin 主要涉及几个组件: Collector (收集 agent 数据)、 Storage (存储)和 Web UI (图形 界面)
下面实战我用之前搭的SpringCloud微服务来演示
上手实战
启动一个Zipkin Server
下载和启动Zipkin可以参考zipkin的github官网https://github.com/openzipkin/zipkin 的quick start模块
我本地通过Docker Desktop启动一个Zipkin Server
然后按照官网说明打开如下地址
http://your_host:9411/zipkin/
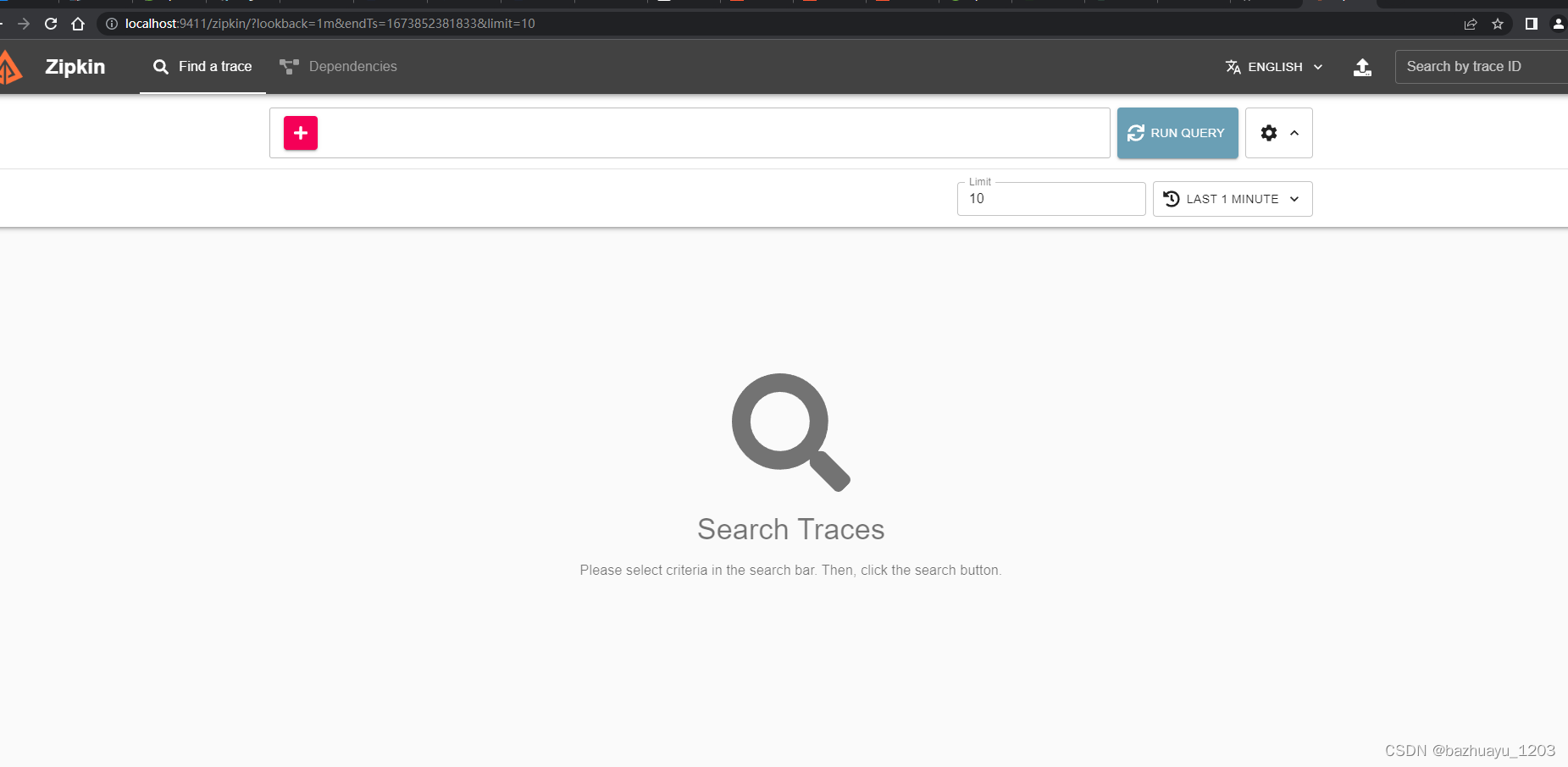
可以看到Zipkin的UI界面。
微服务集成Sleuth+Zipkin
1、pom.xml文件引入依赖坐标
<!-- 链路追踪sleuth+zipkin 相关 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
2、配置文件application里配置Sleuth采集率和Zipkin的地址
spring:
sleuth:
sampler:
#请求采集的速率,默认时候0.1改成1,不然感觉不到它在工作
probability: ${zipkin.rate:1}
zipkin:
base-url: http://localhost:9411/
3、重启微服务,然后访问接口
 我前面复习各个组件的时候搭的服务里,Zuul网关是fc-gateway-zuul,然后fc-service-portal里定义了接口通过OpenFeign调用fc-service-screen服务。访问如下接口
我前面复习各个组件的时候搭的服务里,Zuul网关是fc-gateway-zuul,然后fc-service-portal里定义了接口通过OpenFeign调用fc-service-screen服务。访问如下接口
http://localhost:8000/portal/getUser/2
然后去Zipkin的UI界面点击搜索框右边的RUN QUERY
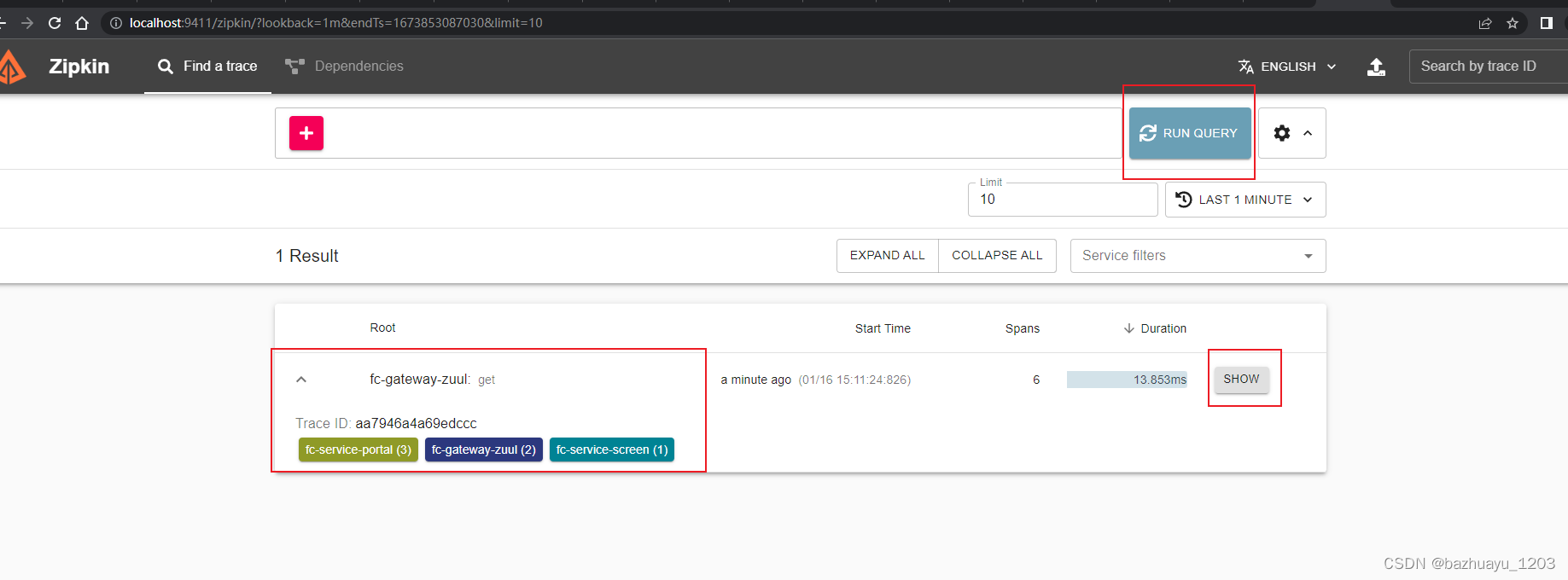
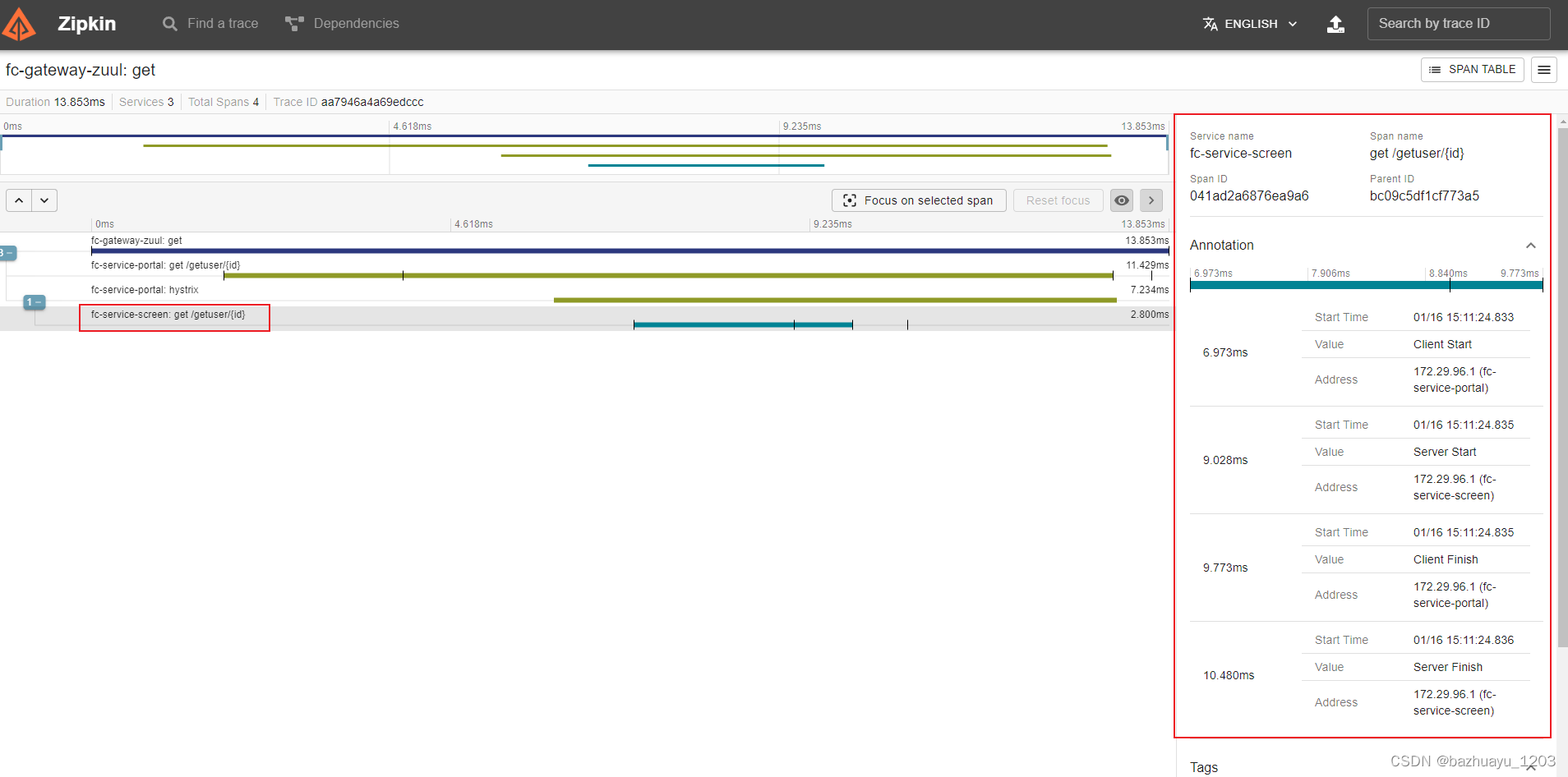
会看到已经采集到数据了。而且服务的调用链路通过序号1,2,3看的很清楚。点击这个SHOW,可以看到具体的内容
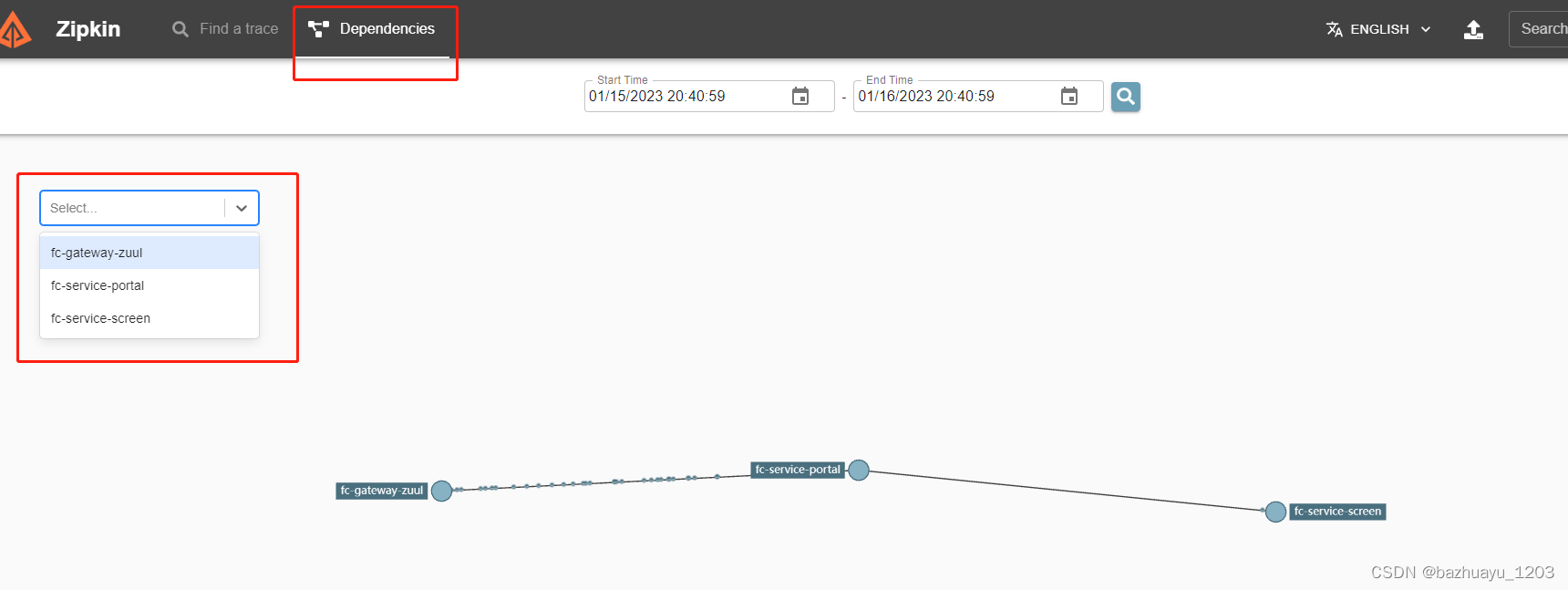
还可以看到服务之间的依赖关系
我这个只是Demo演示,实际公司里如果要用的话,这种方案里有很多不足,比如
1、Zipkin客户端向Zipkin 服务端发送数据使用的是HTTP的方式,那么就会有个问题,如果Zipkin服务端重启,肯定有发送数据的丢失。针对这个问题,可以修改Zipkin客户端和服务端通信的方式为异步,比如用MQ。
2、目前数据存储是在内存里的,没有持久化,实际公司里使用数据量少的情况可以用Mysql来存储,数据量大的建议使用Elasticsearch来存储。
可以参考官网来实现。















 279
279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









