










下面将从链表的定义、分类、特点对链表展开介绍。
链表:
链表是一种物理存储单元上非连续、非顺序的存储结构。它链表有一个“head”变量,它存放一个地址。该地址指向一个元素。链表中每一个元素称为“结点”,每个结点都应包括两个部分:一为用户需要用的实际数据,二为下一个结点的地址(双向链表为三个部分,分别为前驱指针、数据、后驱指针)。因此,head指向第一个元素;第一个元素又指向第二个元素;……,直到最后一个元素,该元素不再指向其它元素,它称为“表尾”,它的地址部分放一个“NULL”(表示“空地址”),链表到此结束。
特点:
(结合数组进行理解和记忆)
线性查找、访问效率低。
插入、删除等效率高。
链表存放在堆中。(数组是从栈中分配空间)
动态地进行存储分配,可以根据需要开辟内存单元。
分类:
根据指针域的不同,链表可以分为单向列表、双向链表、循环列表。
1.单向列表

单向链表的链接方向是单向的,对链表的访问要通过顺序读取从头部开始。添加顺序为从右向左,也就说最后添加的节点位于链表的最左端(图),也就是头指针指向的那个节点。
2.双向链表
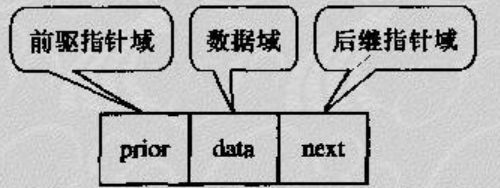
双向链表的出现可以说是为了解决循环链表对前驱节点查找的不足。循环链表虽然能够实现从任一结点出发沿着链能找到其前驱结点,但时间耗费是O(n)。如果希望从表中快速确定某一个结点的前驱,另一个解决方法就是在单链表的每个结点里再增加一个指向其前驱的指针域prior。这样形成的链表中就有两条方向不同的链,我们可称之为双(向)链表(Double Linked List)。双向链表图示如下:

3.循环列表
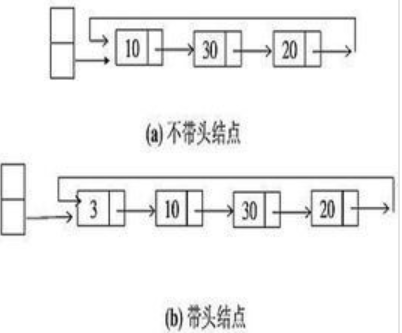
循环列表的特点是如图所示,可以理解成“尾节点”不再指向“NULL”,而是指向头节点。上图中的带头节点和不带头节点的区别是:不带头节点的情况下,最先添加的元素的“index”指针直接指向最后添加的元素;而带头节点的循环列表则人为的添加了一个节点,这个节点不属于链表内容。添加的头结点用于记录链表的信息(如节点的数目),另外也是为了算法处理上的方便。
(看了很多人的文章,好多都是手撕代码,很牛逼的样子,我还是先从概念出发吧,加油!^^)














 809
809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









