









上节内容讲解了图的邻接表的创建,链接地址为数据结构之图的邻接表存储方法。那么如果想要删除图的一个顶点,并且删除依附于该顶点的所有边,这种情况该如何处理呢?
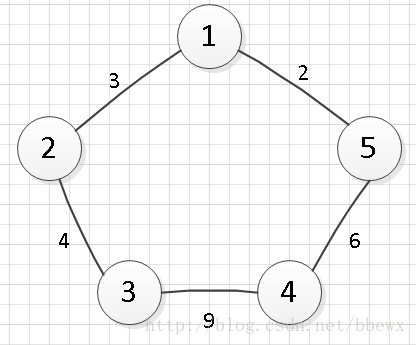
首先来回顾一下邻接表是如何存储的。邻接表包含了一个长度为n的数组(n为图的顶点数),该数组中的每个元素都是一个链表的头结点,头结点后面“链”着与该头结点相关的边结点信息。图以及图的邻接表如下图所示。
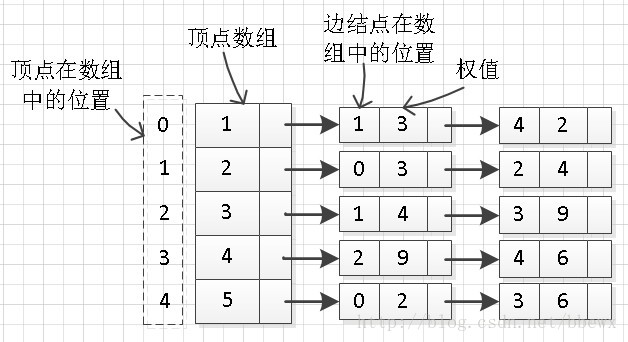
我们以删除上图中位置为2(也就是顶点编号为3)的顶点为例,并删除与该点相关的边信息。
第一步:删除编号为3的顶点链接的边信息,即删除边信息为1,4和3,9的两条边,结果变为
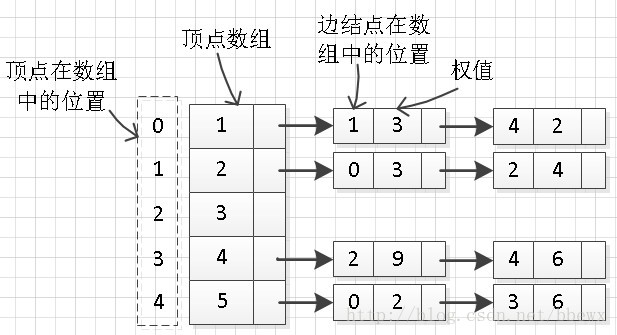
第二步:删除编号为3的顶点信息,并将编号为4的顶点放在顶点数组下标为2的位置,将编号为5的顶点放在顶点数组下标为3的位置,结果为
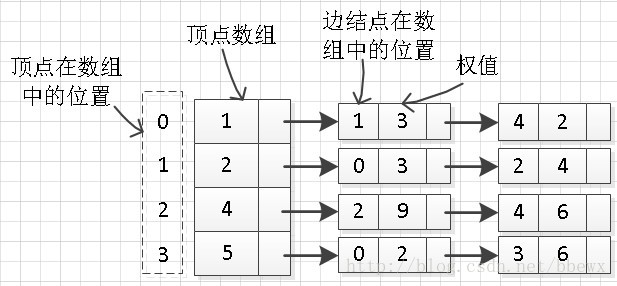
第三步:遍历各个顶点链接的边信息,将与编号为3(即下标为2)的边结点信息删除,并将大于2的边结点下标减一。结果为
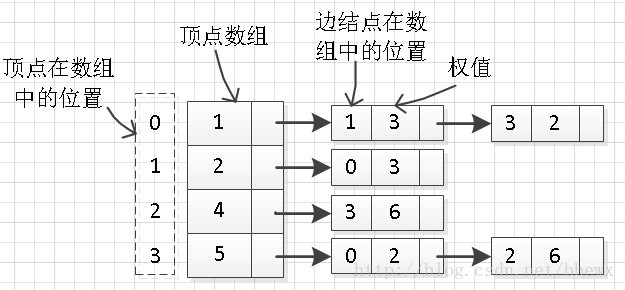
此时便得到了删除编号为3的顶点以及相关边的邻接表。
删除顶点的实现代码如下:
//函数表示在长度为n的顶点数组G中删除顶点数据信息为vertex的顶点
void deleteAdjacencyListElement(VLink *G, int n, int vertex) {
int position = -1; //表示删除顶点在顶点数组中的位置
ELink *p, *q, *r;
//遍历顶点数组,并删除顶点数组中的被删顶点
for(int i=0; i<n; i++) {
if(G[i].vertex == vertex) {
position = i;
p = G[i].link;
for(int j=i+1; j<n; j++) {
G[j-1].vertex = G[j].vertex;
G[j-1].link = G[j].link;
}
n--;
break;
}
}
if(position == -1) {
cout << "不存在数据信息为" << vertex << "的顶点" << endl;
}
else {
//删除被删顶点链接的边信息
while(p) {
q = p->next;
delete p;
p = q;
}
//删除其它顶点中与position相关的边结点
for(int i=0; i<n; i++) {
p = G[i].link;
while(p) {
if (p->adjvex == position) {
if(p == G[i].link) {
G[i].link = p->next;
}
else {
r->next = p->next;
}
q = p;
p = p->next;
delete q;
}
else {
if(p->adjvex > position) {
p->adjvex--;
}
r = p;
p = p->next;
}
}
}
}
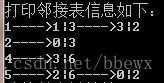
}运行代码后执行结果如下图,此结果与我们分析的结果一致,表示我们的删除算法是正确的。














 1281
1281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









