







一、工具使用步骤
1、打开竖排日语图片文件识别
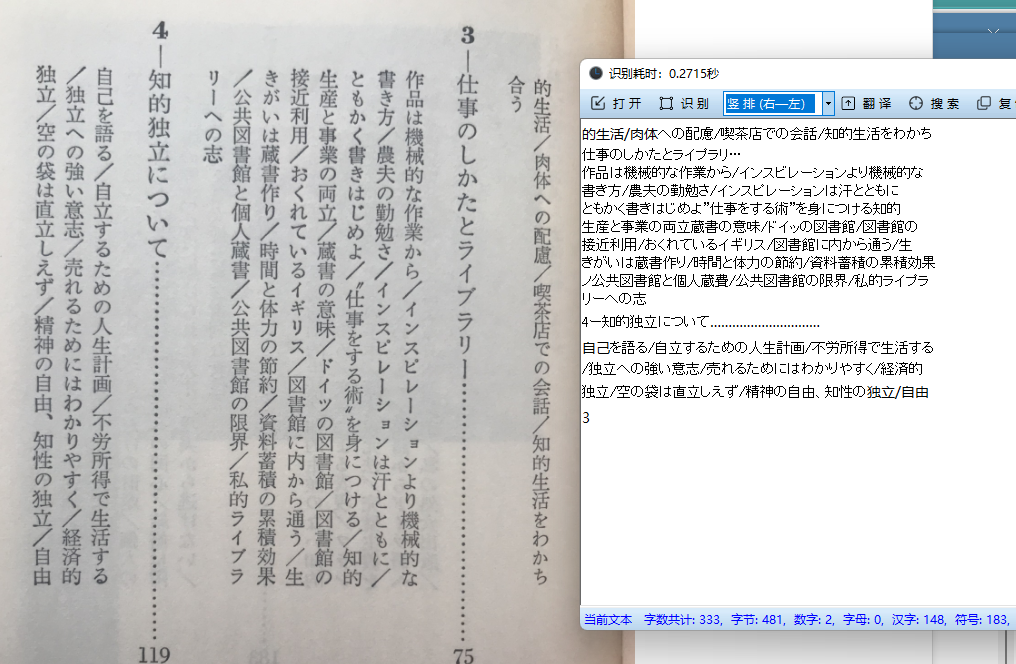
2、支持对屏幕截图日语竖排的识别
3、拖拽竖排的日语图片进窗体识别
4、从左到右,从右到左的文字顺序切换
5、支持跳转到搜狗和百度的网页对识别内容翻译
6、支持对窗体双击内容部分,直接文字复制到别处粘贴
7、ctrl+鼠标滚轮,对字体放大缩小
8、支持记录板,多次记录一次导出
9、支持多次识别记录版,简体繁体互转
10、支持识别文字百度搜索
单击翻译:可以跳转到网页进行翻译,双击窗体就能复制识别后的文本
双击窗体:可以复制文本,复制到指定地方
记 录 板:能记录每一次的识别结果一次性导出
二、操作注意事项
- 图片质量:图片的清晰度对识别准确率至关重要。尽量使用高清、无模糊、无阴影的图片,以提高 OCR 识别的效果。如果图片存在倾斜,可能需要先进行倾斜校正,可以通过检测文字线条的方向,使用霍夫变换等方法来实现。
- 语言设置:在使用相关软件或工具时,要确保正确设置语言为日语,以及正确选择竖排文字的识别方向(从左到右或从右到左),否则可能导致识别错误。
- 翻译准确性:虽然各种工具都能进行翻译,但对于一些专业术语、特定语境或具有文化背景的内容,翻译可能不够准确。如有需要,可以结合人工翻译或查阅专业词典进行校对。
- 软件兼容性:不同的软件或工具在不同的设备和操作系统上可能存在兼容性问题。如果遇到问题,可以尝试更新软件版本或更换设备进行操作。


















 1105
1105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









