







现在的Windows操作系统有许多不同语言版本,可以支持所有国家现有的语言文字。这就涉及到不同字符集的编码规则。
本节必须掌握的知识点:
字符集
C语言款字符
宽字符和Windows
1.4.1 字符集
■ANSI多字节字符集
●ASCII码
现代计算机发源于美国,计算机最早支持的语言文字自然是美式英语。为了能够显示美式英语字符,美国人发明了一种ASCII码的编码规则。ASCII码采用7位二进制数定义一个符号,取值范围为0~127,对应128个字符。如图1-6所示。
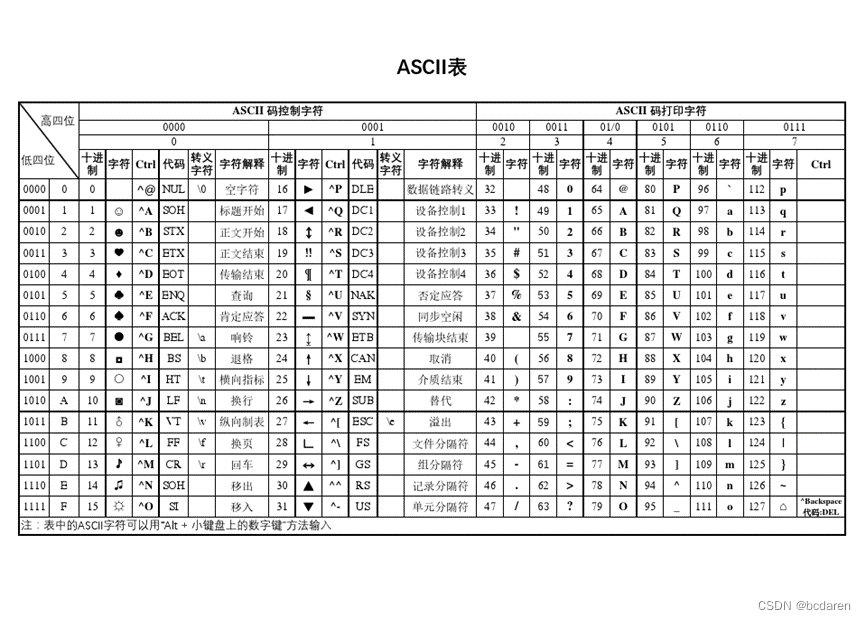
|
图1-6 ASCII码表 |
ASCII码的编写具有一定规律,是一种非常可靠的编码,广泛应用于计算机的键盘、显示器、系统硬件、打印机、字体文件操作系统和互联网。
ASCII码只能满足美国的需要,但是对于世界其他国家的文字符号并不能满足。为了满足欧洲国家的需要,IBM公司使用8位二进制数表示字符,编写了扩展ASCII码表,最多支持256个字符。
为了统一标准,美国国家标准局(ANSI)制定了统一标准的ASCII码。
●对于中文、日文等用两个字节
如果将计算机应用于东亚国家,如中文、韩文和日文,就需要编写多达几万个字符。因此即使8位二进制数也无法实现。为此,将二进制数扩展到16位,最多可以编写216个字符,基本就可以满足需要了。
●一个字符串中,如何区分哪个是中文字符,那个是ASCII字符呢?
举例说明,例如ANSI字符集“Windows程序设计”16进制(10进制)的编码如下表所示。
| W | i | n | d | o | w | s | 程 | 序 | 设 | 计 | |
| 57 | 69 | 6E | 64 | 6F | 77 | 73 | B3 CC | D0 F2 | C9 E8 | BC C6 | 0 |
| 87 | 105 | 110 | 100 | 111 | 119 | 115 | -77 -52 | -48 -14 | -55 -24 | -68 -58 | 0 |
前面的英文字母使用ASCII码单字节表示,中文字符使用两个字节表示,均为负数。
优点:节约内存。
缺点:每次查找都需要从头到尾扫描,效率低。
●计算字符串的长度
char c[] ="Windows程序设计";
printf("%d\n",sizeof(c)); //输出16,数组总长度为16字节,含\0
printf("%d\n",strlen(c)); //输出15,字符的长度为15个字节,不含\0
■Unicode宽字节字符集
Unicode字符集为16位,最多可以支持65536个字符。 Unicode字符串中的所有字符都是16位的(两个字节)。这样,它就能够对世界各国的书面文字中的所有字符进行编码,远远超过了单字节字符集的256个字符的数目。但Unicode并非尽善尽美。Unicode字符的字符串占用的内存比ASCII字符串大两倍。
这65536个字符可以分成不同的区域。表1-1 显示了这样的区域的一部分以及分配给这些区域的字符。
| 16位代码 | 字符 | 16位代码 | 字符 |
| 0000-007F | ASCII | 0300-036F | 通用区分标志 |
| 0080-00FF | 拉丁文字符 | 0400-04FF | 西里尔字母 |
| 0100-017F | 欧洲拉丁文 | 0530-058F | 亚美尼亚文 |
| 0180-01FF | 扩充拉丁文 | 0590-05FF | 希伯莱文 |
| 0250-02AF | 标准拼音 | 0600-06FF | 阿拉伯文 |
| 02B0-02FF | 修改型字母 | 0900-097F | 梵文 |
| 2E80-2EFF | 中日韩汉字部首补充 | 31C0-31EF | 中日韩汉语笔画 |
表1-1 区域字符
目前尚未分配的代码点大约还有29 000个,不过它们是保留供将来使用的。另外,大约有 6 0 0 0个代码点是保留供个人使用的。
●Unicode
1.ASCII字符的处理。扩充为两个字节,在原先的字节前补充一个字节00h。
2.结束符为两个”\0\0”。
3.字符串的解释都是两个字符为单位进行的。所以查找效率快,但内存占用大。
举例
“Windows程序设计”16进制的编码:
| W | i | n | d | o | w | s | 程 | 序 | 设 | 计 | |
| 00 57 | 00 69 | 00 6E | 00 64 | 00 6F | 00 77 | 00 73 | 7A 0B | 5E 8F | 8B BE | 8B A1 | 00 00 |
●计算字符串的长度
wchar_t c[] = L"Windows程序设计";
printf("%d\n",sizeof(c)); //输出24,数组总长度为16字节,含结束符
printf("%d\n",wcslen(c)); //输出11,字符的长度为11个,不含结束符
■字符编码UTF-8
Unicode 统一了所有字符的编码,是一个 Character Set,也就是字符集,字符集只是给所有的字符一个唯一编号,但是却没有规定如何存储,一个编号为 65 的字符,只需要一个字节就可以存下,但是编号40657的字符需要两个字节的空间才可以装下,而更靠后的字符可能会需要三个甚至四个字节的空间。
这时,用什么规则存储 Unicode 字符就成了关键,我们可以规定,一个字符使用四个字节存储,也就是 32 位,这样就能涵盖现有 Unicode 包含的所有字符,这种编码方式叫做 UTF-32(UTF 是 UCS Transformation Format 的缩写)。UTF-32 的规则虽然简单,但是缺陷也很明显,假设使用 UTF-32 和 ASCII 分别对一个只有西文字母的文档编码,前者需要花费的空间是后者的四倍(ASCII 每个字符只需要一个字节存储)。
在存储和网络传输中,通常使用更为节省空间的变长编码方式 UTF-8,UTF-8 代表 8 位一组表示 Unicode 字符的格式,使用 1 - 4 个字节来表示字符。
UTF-8 的编码规则如下(U+ 后面的数字代表 Unicode 字符代码):
U+ 0000 ~ U+ 007F: 0XXXXXXX
U+ 0080 ~ U+ 07FF: 110XXXXX 10XXXXXX
U+ 0800 ~ U+ FFFF: 1110XXXX 10XXXXXX 10XXXXXX
U+10000 ~ U+1FFFF: 11110XXX 10XXXXXX 10XXXXXX 10XXXXXX
可以看到,UTF-8 通过开头的标志位位数实现了变长。对于单字节字符,只占用一个字节,实现了向下兼容 ASCII,并且能和 UTF-32 一样,包含 Unicode 中的所有字符,又能有效减少存储传输过程中占用的空间。
当前Windows操作系统默认使用Unicode字符集。
1.4.2 C语言宽字符
由于本书采用C语言实现Windows程序,因此我们必须介绍一下C语言宽字符集函数。最早我们学习C语言时,使用的是ANSI C(美国国家标准程式设计语言——C),支持7位ASCII码字符。ANSI C 还支持多字节字符集,例如中文、日文和韩文版本 Windows 支持的字符集。然而,这些多字节字符集被当成单字节值的字符串。多字节字符集主要影响 C 语言运行库函数。相比之下,宽字符比正常字符宽,而且会引起一些编译问题。
宽字符不一定是 Unicode。Unicode 是一种可能的宽字符集。然而,因为本书的焦点是 Windows 而不是一个抽象的C语言实现,所以本书将把宽字符和 Unicode 作为同义词。
■ANSI字符集char数据类型
char c = 'A';
变量c需要一个字节来存储空间十六进制值0x41,表示ASCII码字母A。
再定义一个字符串指针:
char *p;
因为windows是32位系统,指针变量P需要4个字节的存储空间。
char *p = "Hello!";
字符串需要7个字节的空间存储,其中一个是字符串结尾的空字符。
还可以定义一个字符数组:
char a[10];
编译器保留10个字节的空间给这个数组。sizeof(a)表达式会返回10。
还可以写成:
char a[] = "Hello!";//初始化数组
■宽字符集char数据类型
使用Unicode宽字符并不会改变C语言中的字符数据类型。char类型继续代表1个字节的存储空间,而且sizeof(char)返回1。理论上来说,C语言中的一个字节可能长于8位,但是对于大多数人来说,一个字节就是8位宽。
C语言中的宽字符是基于wchar_t数据类型的。这个数据类型被定义在多个头文件中,包括WCHAR.H:
typedef usigned short wchar_t;
wchar_t数据类型和一个无符号短整型一样都是16位宽。
可以用下面的语句来定义一个包含单个宽字符的变量:
wchar_t c = 'A';
变量C是一个两个字节的值0X0041,这是Unicode字母A的代表。
由于Intel处理器存储多字节值时总是最低有效字节优先(小端存储模式),所以这些字节实际上在内存中式以0x41 ,0x00的顺序存储的。如果检查Unicode文本的内存存储,请务必记住这点。
wchar_t *p = L"Hello!";
大写字母L表示长整型,紧接左引号。这向编译器表明这个字符串将用宽字符存储,也就是说,每个字符占两个字节。指针变量p需要4个字节的存储空间,但这个字符串需要14个字节的存储空间。
wchar_t a[] = L"Hello!";
sizeof(a)同样返回14。
虽然看起来像是一个录入错误,但是引号之前的L非常重要,而且这两个字符之间绝对不能有空格。只有有了这个L,编译器才知道你想要字符串用用两个字节来存储一个字符。
wchar_t c = L'A';
单个字符而言,可以使用L前缀表示宽字符,也可以缺省,编译器会自动加0。
C语言标志库函数对应有ANSI字符集函数和宽字符集函数,详见下一小节中的表1-2。
1.4.3 Windows宽字符
■ANSI函数和UNICODE函数的兼容
在Windows中ANSI和UNICODE字符串操作分别提供了相应的函数,也提供了一套兼容两者的函数。比如:
![]()
 举例
举例
例1:
#ifdef UNICODE
#define _tcscpy wcscpy
#else
#define _tcscpy strcpy
#endif
例2:
#ifdef UNICODE
#define MessageBox MessageBoxW
#else
#define MessageBox MessageBoxA
#endif // !UNICODE
例3:
#ifdef _UNICODE
#define _tcslen wcslen
#define TCHAR wchar_t
#define LPTSTR wchar_t*
#define _T(x) L##x
#else
#define _tcslen strlen
#define TCHAR char
#define LPTSTR char*
#define _T(x) x
#endif
例4:
//多字节字符集下
printf("%d\n",sizeof(c)); //16
printf("%d\n",_tcslen(c)); //15
//宽字符集下
printf("%d\n",sizeof(c)); //24
printf("%d\n",_tcslen(c)); //11
![]()
●字符集对比
|
| ASCII | Unicode | 通用版本 |
| 字符类型 | char\CHAR | wchar_t\WCHAR | TCHAR |
| 函数两种版本 | printf | wprintf | _tprintf |
![]()
![]() 提示
提示
1.Windows API函数定义的是Unicode函数,与此对应的ASCII函数是将ASCII字符转换为Unicode字符,然后再由Unicode函数实现。
2.Windows操作系统动态链接库中的函数名和动态链接库名为ASCII字符。
![]()
■Windows头文件的类型
WINDOWS.H头文件包含许多其他头文件,比如:
WINDEF.H头文件:基本数据类型的定义
WINNT.H头文件:负责处理基本的Unicode支持功能
WINNT.H头文件在开始位置包含了C的头文件CTYPE.H,CTYPE.H头文件中定义了wchar_t数据类型。而WINNT.H头文件中定义了两个新的数据类型CHAR和WCHAR:
typedef char CHAR;
typedef char WCHAR; //wc
CHAR和WCHAR是Windows推荐使用的数据类型,分别定义8位和16位的字符。WCHAR后面注释wc,是建议使用匈牙利标记法来说明这是一个基于WCHAR数据类型的变量,即这是一个宽字符。
接下来WINNT.H头文件定义了可用做8位字符串指针的6种数据类型和可用作const 8位字符串指针的4种数据类型。
typedef CHAR * PCHAR, * LPCH, * PCH, * NPSTR, * LPSTR, * PSTR ;
typedef CONST CHAR * LPCCH, * PCCH, * LPCSTR, * PCSTR ;
前缀N和L代表near和long,指16位windows系统中的两种大小不同的指针。但在win32中near和long指针则没有区别。
同样接下来WINNT.H头文件定义了可用做16位字符串指针的6种数据类型和可用作const 16位字符串指针的4种数据类型。
typedef WCHAR * PWCHAR, * LPWCH, * PWCH, * NWPSTR, * LPWSTR, * PWSTR ;
typedef CONST WCHAR * LPCWCH, * PCWCH, * LPCWSTR, * PCWSTR ;
这样我们就有了数据类型CHAR和WCHAR的各种指针。像TCHAR.H中一样,WINNT.H将TCHAR定义为一个通用的字符类型。如果标识符_UNICODE被定义了,则TCHAR和TCAHR的指针就被分别定义为WCHAR和指向WCHAR的指针。如果标识符UNICODE没有被定义,则TCHAR被定义为char类型或char类型的指针。
#ifdef UNICODE
typedef WCHAR TCHAR, * PTCHAR ;
typedef LPWSTR LPTCH, PTCH, PTSTR, LPTSTR ;
typedef LPCWSTR LPCTSTR ;
#else
typedef char TCHAR, * PTCHAR ;
typedef LPSTR LPTCH, PTCH, PTSTR, LPTSTR ;
typedef LPCSTR LPCTSTR ;
#endif
如果TCHAR已经在头文件中被定义了,WINNT.H和WCHAR.H头文件都能防止TCHAR数据类型被重复定义。WINNT.H头文件还定义了一个宏,它将L添加到一个字符串的第一个引号前。
#define __TEXT(quote) L##quote //UNICODE已定义
#define __TEXT(quote) quote //UNICODE未定义
而不管怎样,TEXT宏如下定义:
#define __TEXT(quote) __TEXT(quote)
这些定义可以让你在同一个程序中混合使用ASCII和Unicode字符串。
Windows NT从底层支持Unicode,意味着Windows NT内部使用16位字符的字符串。因为世界上还有许多地方不使用16位字符串,所以windows NT操作系统必须经常在内部转换字符串。在Windows NT上,既可以执行ASCII、UNICODE单写的程序,也可以执行为ASCII和Unicode混合编写的程序。其实是通过相关的API函数实现的。
■ Windows的字符串函数
Microsoft C包含了宽字符以及通用版的需要字符串参数的C语言运行库函数。不过,Windows复制了其中一部分C函数。
ILength = lstrlen (pString) ;
pString = lstrcpy (pString1, pString2) ;
pString = lstrcpyn (pString1, pString2, iCount) ;
pString = lstrcat (pString1, pString2) ;
iComp = lstrcmp (pString1, pString2) ;
iComp = lstrcmpi (pString1, pString2) ;
这些函数提供了与C运行库中对应的函数功能。当定义了UNICODE标识符时,这些函数就支持宽字符串,否则只接受常规字符串。
■在Windows中使用printf
遗憾的是在windows程序中不能使用printf函数,因为Windows不存在标准输入和标准输出的概念。但是在Windows程序中可以使用fprintf函数和sprintf函数。
函数原型:
int printf (const char * szFormat, ...) ;
int sprintf (char * szBuffer, const char * szFormat, ...) ;
sprintf函数并不是将格式化结果写到标准输出,而是将其存入szBuffer缓冲区。
printf ("The sum of %i and %i is %i", 5, 3, 5+3) ;
的功能等同于:
char szBuffer [100] ;
sprintf (szBuffer, "The sum of %i and %i is %i", 5, 3, 5+3) ;
puts (szBuffer) ;
【注意】缓冲区要足够的大。
sprintf函数还有一个变形函数vsprintf函数。
int sprintf (char * szBuffer, const char * szFormat, ...)
{
int iReturn ;
va_list pArgs ;
va_start (pArgs, szFormat) ;
iReturn = vsprintf (szBuffer, szFormat, pArgs) ;
va_end (pArgs) ;
return iReturn ;
}
参见C语言中可变参数的内容。
因为很多早期的windows程序使用了sprintf和vsprintf函数,所以windows API中增加了两个相似的函数wsprint和wvsprintf函数。
随着宽字符的引入,sprintf函数增加了许多,如下表:
| ASCII | 宽字符 | 通用 | |
| 可变数目的参数 | |||
| 标准版 | sprintf | swprintf | _stprintf |
| 最大长度版 | _sprintf | _snwprintf | _sntprintf |
| Windows版 | wsprintfA | wsprintfW | wsprintf |
| 参数数组的指针 | |||
| 标准版 | vsprintf | vswprintf | _vstprintf |
| 最大长度版 | _vsnprintf | _vsnwprintf | _vsntprintf |
| Windows版 | wvsprintfA | wvsprintfW | wvsprintf |
表1-2 printf函数
在宽字符版的sprintf函数中,字符串缓冲区被定义为宽字符串。在所有的宽字符版的函数中,格式字符串必须是宽字符串。不过,确保传递给这些函数的其他字符串也是宽字符串则是你的责任。
■字符串处理函数常用函数对照表
| ANSI | UNICODE | 通用 | 说明 |
| 数据类型 | |||
| (char.h) | (wchar.h) | (tchar.h) | |
| char | wchar_t | TCHAR | |
| char * | wchar_t * | TCHAR* | |
| LPSTR | LPWSTR | LPTSTR | |
| LPCSTR | LPCWSTR | LPCTSTR | |
| 字符串转换 | |||
| atoi | _wtoi | _ttoi | 把字符串转换成整数(int) |
| atol | _wtol | _ttol | 把字符串转换成长整型数(long) |
| atof | _wtof | _tstof | 把字符串转换成浮点数(double) |
| itoa | _itow | _itot | 将任意类型的数字转换为字符串 |
| 字符串操作 | |||
| strlen | wcslen | _tcslen | 获得字符串的数目 |
| strcpy | wcscpy | _tcscpy | 拷贝字符串 |
| strncpy | wcsncpy | _tcsncpy | 类似于strcpy/wcscpy,同时指定拷贝的数目 |
| strcmp | wcscmp | _tcscmp | 比较两个字符串 |
| strncmp | wcsncmp | _tcsncmp | 类似于strcmp/wcscmp,同时指定比较字符字符串的数目 |
| strcat | wcscat | _tcscat | 把一个字符串接到另一个字符串的尾部 |
| strncat | wcsncat | _tcsnccat | 类似于strcat/wcscat,而且指定粘接字符串的粘接长度. |
| strchr | wcschr | _tcschr | 查找子字符串的第一个位置 |
| strrchr | wcsrchr | _tcsrchr | 从尾部开始查找子字符串出现的第一个位置 |
| strpbrk | wcspbrk | _tcspbrk | 从一字符字符串中查找另一字符串中任何一个字符第一次出现的位置 |
| strstr | wcsstr/wcswcs | _tcsstr | 在一字符串中查找另一字符串第一次出现的位置 |
| strcspn | wcscspn | _tcscspn | 返回不包含第二个字符串的的初始数目 |
| strspn | wcsspn | _tcsspn | 返回包含第二个字符串的初始数目 |
| strtok | wcstok | _tcstok | 根据标示符把字符串分解成一系列字符串 |
| wcswidth | 获得宽字符串的宽度 | ||
| wcwidth | 获得宽字符的宽度 | ||
| 字符串测试 | |||
| isascii | iswascii | _istascii | 测试字符是否为ASCII 码字符, 也就是判断c 的范围是否在0 到127 之间 |
| isalnum | iswalnum | _istalnum | 测试字符是否为数字或字母 |
| isalpha | iswalpha | _istalpha | 测试字符是否是字母 |
| iscntrl | iswcntrl | _istcntrl | 测试字符是否是控制符 |
| isdigit | iswdigit | _istdigit | 测试字符是否为数字 |
| isgraph | iswgraph | _istgraph | 测试字符是否是可见字符 |
| islower | iswlower | _istlower | 测试字符是否是小写字符 |
| isprint | iswprint | _istprint | 测试字符是否是可打印字符 |
| ispunct | iswpunct | _istpunct | 测试字符是否是标点符号 |
| isspace | iswspace | _istspace | 测试字符是否是空白符号 |
| isupper | iswupper | _istupper | 测试字符是否是大写字符 |
| isxdigit | iswxdigit | _istxdigit | 测试字符是否是十六进制的数字 |
| 大小写转换 | |||
| tolower | towlower | _totlower | 把字符转换为小写 |
| toupper | towupper | _totupper | 把字符转换为大写 |
| 字符比较 | |||
| strcoll | wcscoll | _tcscoll | 比较字符串 |
| 日期和时间转换 | |||
| strftime | wcsftime | _tcsftime | 根据指定的字符串格式和locale设置格式化日期和时间 |
| strptime | 根据指定格式把字符串转换为时间值, 是strftime的反过程 | ||
| 打印和扫描字符串 | |||
| printf | wprintf | _tprintf | 使用vararg参量的格式化输出到标准输出 |
| fprintf | fwprintf | _ftprintf | 使用vararg参量的格式化输出 |
| scanf | wscanf | _tscanf | 从标准输入的格式化读入 |
| fscanf | fwscanf | _ftscanf | 格式化读入 |
| sprintf | swprintf | _stprintf | 根据vararg参量表格式化成字符串 |
| sscanf | swscanf | _stscanf | 以字符串作格式化读入 |
| vfprintf | vfwprintf | _vftprintf | 使用stdarg参量表格式化输出到文件 |
| vprintf | 使用stdarg参量表格式化输出到标准输出 | ||
| vsprintf | vswprintf | _vstprintf | 格式化stdarg参量表并写到字符串 |
| sprintf_s | swprintf_s | _stprintf_s | 格式化字符串 |
| 数字转换 | |||
| strtod | wcstod | _tcstod | 把字符串的初始部分转换为双精度浮点数 |
| strtol | wcstol | _tcstol | 把字符串的初始部分转换为长整数 |
| strtoul | wcstoul | _tcstoul | 把字符串的初始部分转换为无符号长整数 |
| _strtoi64 | _wcstoi64 | _tcstoi64 | |
| 输入和输出 | |||
| fgetc | fgetwc | _fgettc | 从流中读入一个字符并转换为宽字符 |
| fgets | fgetws | _fgetts | 从流中读入一个字符串并转换为宽字符串 |
| fputc | fputwc | _fputtc | 把宽字符转换为多字节字符并且输出到标准输出 |
| fputs | fputws | _fputts | 把宽字符串转换为多字节字符并且输出到标准输出串 |
| getc | getwc | _gettc | 从标准输入中读取字符, 并且转换为宽字符 |
| getchar | getwchar | _gettchar | 从标准输入中读取字符 |
| putc | putwc | _puttc | 标准输出 |
| putchar | putwchar | _puttchar | 标准输出 |
| ungetc | ungetwc | _ungettc | 把一个字符放回到输入流中 |
表1-3 字符串处理函数常用函数对照表
















 178
178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









